
“Darkroom: compiling high-level image processing code into hardware pipelines” by Hegarty, DeVito, Brunhaver, Ragan-Kelley, Bell, et al. …
Conference:
Type(s):
Title:
- Darkroom: compiling high-level image processing code into hardware pipelines
Session/Category Title: Hardware Systems
Presenter(s)/Author(s):
- James Hegarty
- Zachary DeVito
- John Brunhaver
- Jonathan Ragan-Kelley
- Steven Bell
- Artem Vasilyev
- Noy Cohen
- Mark Horowitz
- Patrick (Pat) Hanrahan
Moderator(s):
Abstract:
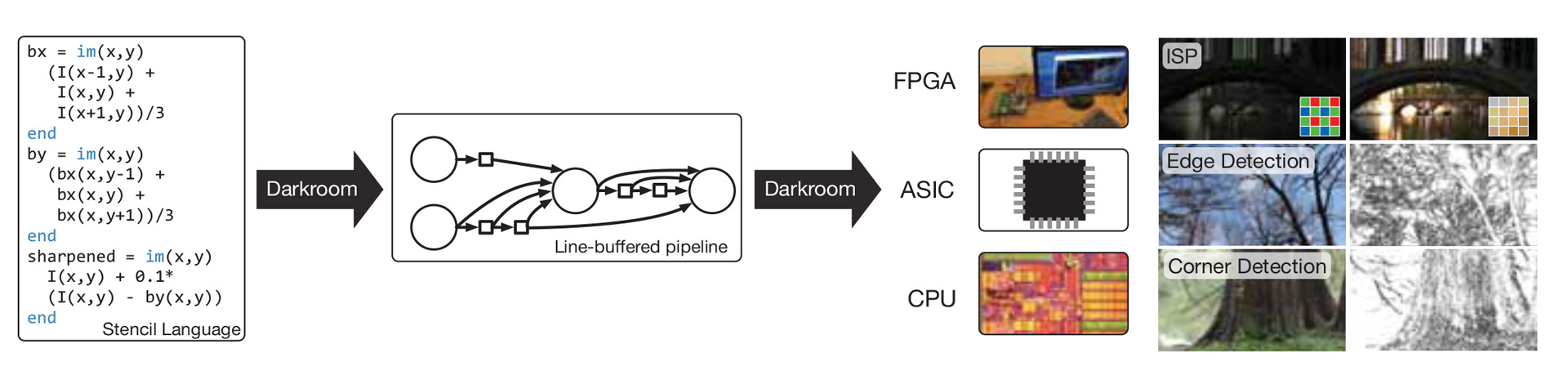
Specialized image signal processors (ISPs) exploit the structure of image processing pipelines to minimize memory bandwidth using the architectural pattern of line-buffering, where all intermediate data between each stage is stored in small on-chip buffers. This provides high energy efficiency, allowing long pipelines with tera-op/sec. image processing in battery-powered devices, but traditionally requires painstaking manual design in hardware. Based on this pattern, we present Darkroom, a language and compiler for image processing. The semantics of the Darkroom language allow it to compile programs directly into line-buffered pipelines, with all intermediate values in local line-buffer storage, eliminating unnecessary communication with off-chip DRAM. We formulate the problem of optimally scheduling line-buffered pipelines to minimize buffering as an integer linear program. Finally, given an optimally scheduled pipeline, Darkroom synthesizes hardware descriptions for ASIC or FPGA, or fast CPU code. We evaluate Darkroom implementations of a range of applications, including a camera pipeline, low-level feature detection algorithms, and deblurring. For many applications, we demonstrate gigapixel/sec. performance in under 0.5mm2 of ASIC silicon at 250 mW (simulated on a 45nm foundry process), real-time 1080p/60 video processing using a fraction of the resources of a modern FPGA, and tens of megapixels/sec. of throughput on a quad-core x86 processor.
References:
1. Adams, A., Talvala, E.-V., Park, S. H., Jacobs, D. E., Ajdin, B., Gelfand, N., Dolson, J., Vaquero, D., Baek, J., Tico, M., Lensch, H. P. A., Matusik, W., Pulli, K., Horowitz, M., and Levoy, M. 2010. The Frankencamera: An experimental platform for computational photography. ACM Transactions on Graphics 29, 4 (July), 29:1–29:12. Google ScholarDigital Library
2. Aptina. Aptina MT9P111. http://www.aptina.com/products/soc/mt9p111/.Google Scholar
3. Berkelaar, M., Eikland, K., Notebaert, P., et al. 2004. lpsolve: Open source (mixed-integer) linear programming system. Eindhoven U. of Technology.Google Scholar
4. Bilsen, G., Engels, M., Lauwereins, R., and Peperstraete, J. 1995. Cyclo-static data flow. In 1995 International Conference on Acoustics, Speech, and Signal Processing, vol. 5, 3255–3258.Google Scholar
5. Bouguet, J.-Y. 2001. Pyramidal implementation of the affine Lucas Kanade feature tracker description of the algorithm. Tech. rep., Intel Corporation.Google Scholar
6. Canny, J. 1986. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 6, 679–698. Google ScholarDigital Library
7. Datta, K., Murphy, M., Volkov, V., Williams, S., Carter, J., Oliker, L., Patterson, D., Shalf, J., and Yelick, K. 2008. Stencil computation optimization and auto-tuning on state-of-the-art multicore architectures. In Proceedings of the 2008 ACM/IEEE conference on Supercomputing, IEEE Press, 4. Google ScholarDigital Library
8. DeVito, Z., Hegarty, J., Aiken, A., Hanrahan, P., and Vitek, J. 2013. Terra: A multi-stage language for high-performance computing. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, 105–116. Google ScholarDigital Library
9. Elliott, C. 2001. Functional image synthesis. In Proceedings of Bridges.Google Scholar
10. Frigo, M., and Strumpen, V. 2005. Cache oblivious stencil computations. In Proceedings of the 19th annual international conference on Supercomputing, ACM, 361–366. Google ScholarDigital Library
11. Gummaraju, J., and Rosenblum, M. 2005. Stream programming on general-purpose processors. In Proceedings of the 38th Annual IEEE/ACM International Symposium on Microarchitecture, IEEE, 343–354. Google ScholarDigital Library
12. Hameed, R., Qadeer, W., Wachs, M., Azizi, O., Solomatnikov, A., Lee, B. C., Richardson, S., Kozyrakis, C., and Horowitz, M. 2010. Understanding sources of inefficiency in general-purpose chips. In Proceedings of the 37th Annual International Symposium on Computer Architecture, ACM, 37–47. Google ScholarDigital Library
13. Harris, C., and Stephens, M. 1988. A combined corner and edge detector. In Proceedings of the 4th Alvey Vision Conference, 147–151.Google Scholar
14. Holzmann, G. 1988. Beyond Photography: The Digital Darkroom. Prentice Hall. Google ScholarDigital Library
15. Kung, H. T. 1979. Let’s design algorithms for VLSI systems. In Proceedings of the Caltech Conference on Very Large Scale Integration.Google Scholar
16. Lattner, C., and Adve, V. 2004. LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation. In Proceedings of the 2004 International Symposium on Code Generation and Optimization (CGO’04). Google ScholarDigital Library
17. Lee, E. A., and Messerschmitt, D. G. 1987. Static scheduling of synchronous data flow programs for digital signal processing. IEEE Transactions on Computers 100, 1, 24–35. Google ScholarDigital Library
18. Leiserson, C. E., and Saxe, J. B. 1991. Retiming synchronous circuitry. Algorithmica 6, 1–6, 5–35.Google ScholarDigital Library
19. Lucas, B. D., Kanade, T., et al. 1981. An iterative image registration technique with an application to stereo vision. In IJCAI, vol. 81, 674–679. Google ScholarDigital Library
20. Malladi, K., Nothaft, F., Periyathambi, K., Lee, B., Kozyrakis, C., and Horowitz, M. 2012. Towards energy-proportional datacenter memory with mobile dram. In 2012 39th Annual International Symposium on Computer Architecture (ISCA), 37–48. Google ScholarDigital Library
21. Muralimanohar, N., and Balasubramonian, R. 2009. Cacti 6.0: A tool to understand large caches. Tech. rep., HP Labs.Google Scholar
22. Murthy, P., Bhattacharyya, S., and Lee, E. 1997. Joint minimization of code and data for synchronous dataflow programs. Formal Methods in System Design 11, 1, 41–70. Google ScholarDigital Library
23. Nguyen, A., Satish, N., Chhugani, J., Kim, C., and Dubey, P. 2010. 3.5-d blocking optimization for stencil computations on modern cpus and gpus. In in Proc. of the 2010 ACM/IEEE Intl Conf. for High Performance Computing, Networking, Storage and Analysis, 2010, 1–13. Google ScholarDigital Library
24. OpenCV. OpenCV. http://opencv.org/.Google Scholar
25. Qualcomm. Qualcomm hexagon SDK. https://developer.qualcomm.com/mobile-development/maximize-hardware/mobile-multimedia-optimization-hexagon-sdk.Google Scholar
26. Ragan-Kelley, J., Adams, A., Paris, S., Levoy, M., Amarasinghe, S., and Durand, F. 2012. Decoupling algorithms from schedules for easy optimization of image processing pipelines. ACM Transactions on Graphics (TOG) 31, 4, 32. Google ScholarDigital Library
27. Ragan-Kelley, J., Barnes, C., Adams, A., Paris, S., Durand, F., and Amarasinghe, S. 2013. Halide: A language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, ACM, 519–530. Google ScholarDigital Library
28. Richardson, W. H. 1972. Bayesian-based iterative method of image restoration. JOSA 62, 1, 55–59.Google ScholarCross Ref
29. Shacham, O., Galal, S., Sankaranarayanan, S., Wachs, M., Brunhaver, J., Vassiliev, A., Horowitz, M., Danowitz, A., Qadeer, W., and Richardson, S. 2012. Avoiding game over: Bringing design to the next level. In Proceedings of the 49th Annual Design Automation Conference (DAC), 623–629. Google ScholarDigital Library
30. Shantzis, M. A. 1994. A model for efficient and flexible image computing. In Proceedings of the 21st annual conference on Computer graphics and interactive techniques, ACM, 147–154. Google ScholarDigital Library
31. Sugerman, J., Fatahalian, K., Boulos, S., Akeley, K., and Hanrahan, P. 2009. Gramps: A programming model for graphics pipelines. ACM Transactions on Graphics (TOG) 28, 1 (Feb.), 4:1–4:11. Google ScholarDigital Library
32. Tang, Y., Chowdhury, R. A., Kuszmaul, B. C., Luk, C.-K., and Leiserson, C. E. 2011. The Pochoir stencil compiler. In Proceedings of the 23rd ACM Symposium on Parallelism in Algorithms and Architectures, ACM, 117–128. Google ScholarDigital Library
33. Vivado. vivado. http://www.xilinx.com/products/design-tools/vivado/integration/esl-design/.Google Scholar