
“PiGraphs: learning interaction snapshots from observations” by Savva and Chang
Conference:
Type(s):
Title:
- PiGraphs: learning interaction snapshots from observations
Session/Category Title: PLANTS & HUMANS
Presenter(s)/Author(s):
Moderator(s):
Abstract:
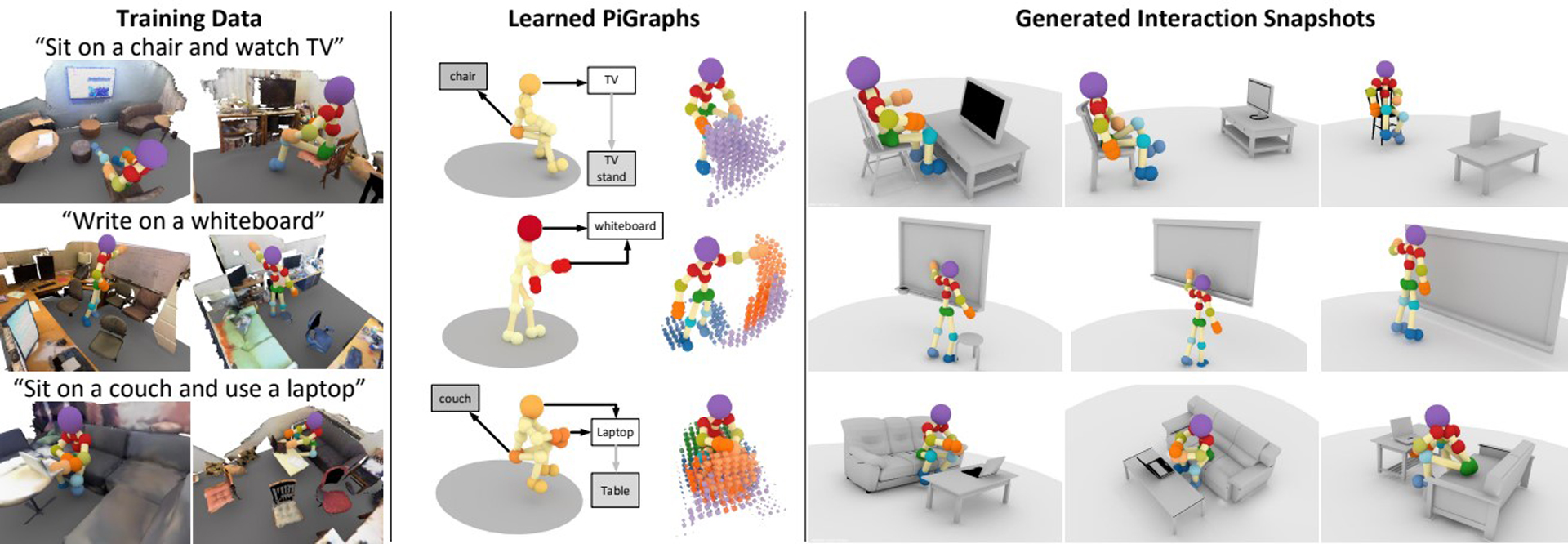
We learn a probabilistic model connecting human poses and arrangements of object geometry from real-world observations of interactions collected with commodity RGB-D sensors. This model is encoded as a set of prototypical interaction graphs (PiGraphs), a human-centric representation capturing physical contact and visual attention linkages between 3D geometry and human body parts. We use this encoding of the joint probability distribution over pose and geometry during everyday interactions to generate interaction snapshots, which are static depictions of human poses and relevant objects during human-object interactions. We demonstrate that our model enables a novel human-centric understanding of 3D content and allows for jointly generating 3D scenes and interaction poses given terse high-level specifications, natural language, or reconstructed real-world scene constraints.
References:
1. Bai, Y., Siu, K., and Liu, C. K. 2012. Synthesis of concurrent object manipulation tasks. ACM Trans. Graph. 31, 6, 156. Google ScholarDigital Library
2. Bohg, J., Morales, A., Asfour, T., and Kragic, D. 2013. Data-driven grasp synthesis—a survey.Google Scholar
3. Chang, A. X., Savva, M., and Manning, C. D. 2014. Learning spatial knowledge for text to 3D scene generation. In Empirical Methods in Natural Language Processing (EMNLP).Google Scholar
4. Coyne, B., and Sproat, R. 2001. WordsEye: an automatic text-to-scene conversion system. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques. Google ScholarDigital Library
5. De la Torre, F., Hodgins, J., Montano, J., Valcarcel, S., and Macey, J. 2009. Guide to the Carnegie Mellon university multimodal activity (CMU-MMAC) database. Robotics Institute, Carnegie Mellon University.Google Scholar
6. Delaitre, V., Fouhey, D. F., Laptev, I., Sivic, J., Gupta, A., and Efros, A. A. 2012. Scene semantics from long-term observation of people. In ECCV. Google ScholarDigital Library
7. Felzenszwalb, P. F., and Huttenlocher, D. P. 2004. Efficient graph-based image segmentation. IJCV. Google ScholarDigital Library
8. Fisher, M., Ritchie, D., Savva, M., Funkhouser, T., and Hanrahan, P. 2012. Example-based synthesis of 3D object arrangements. In ACM TOG. Google ScholarDigital Library
9. Fisher, M., Savva, M., Li, Y., Hanrahan, P., and Niessner, M. 2015. Activity-centric scene synthesis for functional 3D scene modeling. ACM Transactions on Graphics (TOG) 34, 6, 179. Google ScholarDigital Library
10. Fouhey, D. F., Delaitre, V., Gupta, A., Efros, A. A., Laptev, I., and Sivic, J. 2012. People watching: Human actions as a cue for single view geometry. In ECCV. Google ScholarDigital Library
11. Gibson, J. 1977. The concept of affordances. Perceiving, acting, and knowing.Google Scholar
12. Grabner, H., Gall, J., and Van Gool, L. 2011. What makes a chair a chair? In CVPR. Google ScholarDigital Library
13. Grochow, K., Martin, S. L., Hertzmann, A., and Popović, Z. 2004. Style-based inverse kinematics. In ACM Transactions on Graphics (TOG), vol. 23, ACM, 522–531. Google ScholarDigital Library
14. Guo, S., Southern, R., Chang, J., Greer, D., and Zhang, J. J. 2014. Adaptive motion synthesis for virtual characters: a survey. The Visual Computer, 1–16. Google ScholarDigital Library
15. Gupta, A., Satkin, S., Efros, A. A., and Hebert, M. 2011. From 3D scene geometry to human workspace. In CVPR. Google ScholarDigital Library
16. Hu, R., Zhu, C., van Kaick, O., Liu, L., Shamir, A., and Zhang, H. 2015. Interaction context (icon): Towards a geometric functionality descriptor. ACM Trans. Graph. 34, 4 (July), 83:1–83:12. Google ScholarDigital Library
17. Huang, H., Kalogerakis, E., and Marlin, B. 2015. Analysis and synthesis of 3D shape families via deep-learned generative models of surfaces. Computer Graphics Forum 34, 5.Google ScholarCross Ref
18. Jiang, Y., and Saxena, A. 2013. Infinite latent conditional random fields for modeling environments through humans. In RSS.Google Scholar
19. Jiang, Y., Lim, M., and Saxena, A. 2012. Learning object arrangements in 3D scenes using human context. arXiv preprint arXiv:1206.6462.Google Scholar
20. Jiang, Y., Koppula, H., and Saxena, A. 2013. Hallucinated humans as the hidden context for labeling 3D scenes. In CVPR. Google ScholarDigital Library
21. Kallmann, M., and Thalmann, D. 1999. Modeling objects for interaction tasks. Springer.Google Scholar
22. Kalogerakis, E., Chaudhuri, S., Koller, D., and Koltun, V. 2012. A probabilistic model of component-based shape synthesis. ACM Transactions on Graphics 31, 4. Google ScholarDigital Library
23. Kang, C., and Lee, S.-H. 2014. Environment-adaptive contact poses for virtual characters. In Computer Graphics Forum, vol. 33, Wiley Online Library, 1–10. Google ScholarDigital Library
24. Kim, V. G., Chaudhuri, S., Guibas, L., and Funkhouser, T. 2014. Shape2Pose: Human-centric shape analysis. ACM TOG. Google ScholarDigital Library
25. Koppula, H. S., and Saxena, A. 2013. Anticipating human activities using object affordances for reactive robotic response. RSS.Google Scholar
26. Koppula, H., Gupta, R., and Saxena, A. 2013. Learning human activities and object affordances from RGB-D videos. IJRR. Google ScholarDigital Library
27. Lee, K. H., Choi, M. G., and Lee, J. 2006. Motion patches: building blocks for virtual environments annotated with motion data. In ACM Transactions on Graphics (TOG), vol. 25, ACM, 898–906. Google ScholarDigital Library
28. Manning, C. D., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S. J., and McClosky, D. 2014. The Stanford CoreNLP natural language processing toolkit. In Association for Computational Linguistics (ACL): System Demonstrations.Google Scholar
29. Mardia, K. V., and Jupp, P. E. 2009. Directional statistics, vol. 494. John Wiley & Sons.Google Scholar
30. Min, J., and Chai, J. 2012. Motion graphs++: a compact generative model for semantic motion analysis and synthesis. ACM Transactions on Graphics (TOG) 31, 6, 153. Google ScholarDigital Library
31. Niessner, M., Zollhöfer, M., Izadi, S., and Stamminger, M. 2013. Real-time 3D reconstruction at scale using voxel hashing. ACM TOG. Google ScholarDigital Library
32. Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., and Bajcsy, R. 2013. Berkeley MHAD: A comprehensive multi-modal human action database. In Applications of Computer Vision (WACV), 2013 IEEE Workshop on, IEEE, 53–60. Google ScholarDigital Library
33. Savva, M., Chang, A. X., Hanrahan, P., Fisher, M., and Niessner, M. 2014. SceneGrok: Inferring action maps in 3D environments. ACM TOG. Google ScholarDigital Library
34. Shapiro, A. 2011. Building a character animation system. In Motion in Games. Springer, 98–109. Google ScholarDigital Library
35. Shotton, J., Sharp, T., Kipman, A., Fitzgibbon, A., Finocchio, M., Blake, A., Cook, M., and Moore, R. 2013. Real-time human pose recognition in parts from single depth images. CACM. Google ScholarDigital Library
36. Sra, S. 2012. A short note on parameter approximation for von Mises-Fisher distributions: and a fast implementation of Is(x). Computational Statistics 27, 1, 177–190. Google ScholarDigital Library
37. Stark, M., Lies, P., Zillich, M., Wyatt, J., and Schiele, B. 2008. Functional object class detection based on learned affordance cues. In Computer Vision Systems. Google ScholarDigital Library
38. Tenorth, M., Bandouch, J., and Beetz, M. 2009. The TUM kitchen data set of everyday manipulation activities for motion tracking and action recognition. In Computer Vision Workshops (ICCV Workshops), 2009 IEEE 12th International Conference on, IEEE, 1089–1096.Google Scholar
39. Wei, P., Zhao, Y., Zheng, N., and Zhu, S.-C. 2013. Modeling 4D human-object interactions for event and object recognition. In ICCV. Google ScholarDigital Library
40. Wei, P., Zheng, N., Zhao, Y., and Zhu, S.-C. 2013. Concurrent action detection with structural prediction. In ICCV. Google ScholarDigital Library
41. Xu, K., Ma, R., Zhang, H., Zhu, C., Shamir, A., Cohen-Or, D., and Huang, H. 2014. Organizing heterogeneous scene collection through contextual focal points. ACM TOG. Google ScholarDigital Library
42. Yu, L.-F., Yeung, S. K., Tang, C.-K., Terzopoulos, D., Chan, T. F., and Osher, S. 2011. Make it home: automatic optimization of furniture arrangement. ACM Transactions on Graphics 30, 4, 86. Google ScholarDigital Library
43. Yumer, M. E., Chaudhuri, S., Hodgins, J. K., and Kara, L. B. 2015. Semantic shape editing using deformation handles. ACM Transactions on Graphics (Proceedings of SIGGRAPH 2015) 34. Google ScholarDigital Library
44. Zheng, B., Zhao, Y., Yu, J. C., Ikeuchi, K., and Zhu, S.-C. 2014. Detecting potential falling objects by inferring human action and natural disturbance. In ICRA.Google Scholar