“Effective global prediction for dense light-field compression by using synthesized multi-focus images” by Sakamoto, Kodama and Hamamoto
Conference:
Type(s):
Title:
- Effective global prediction for dense light-field compression by using synthesized multi-focus images
Presenter(s)/Author(s):
Abstract:
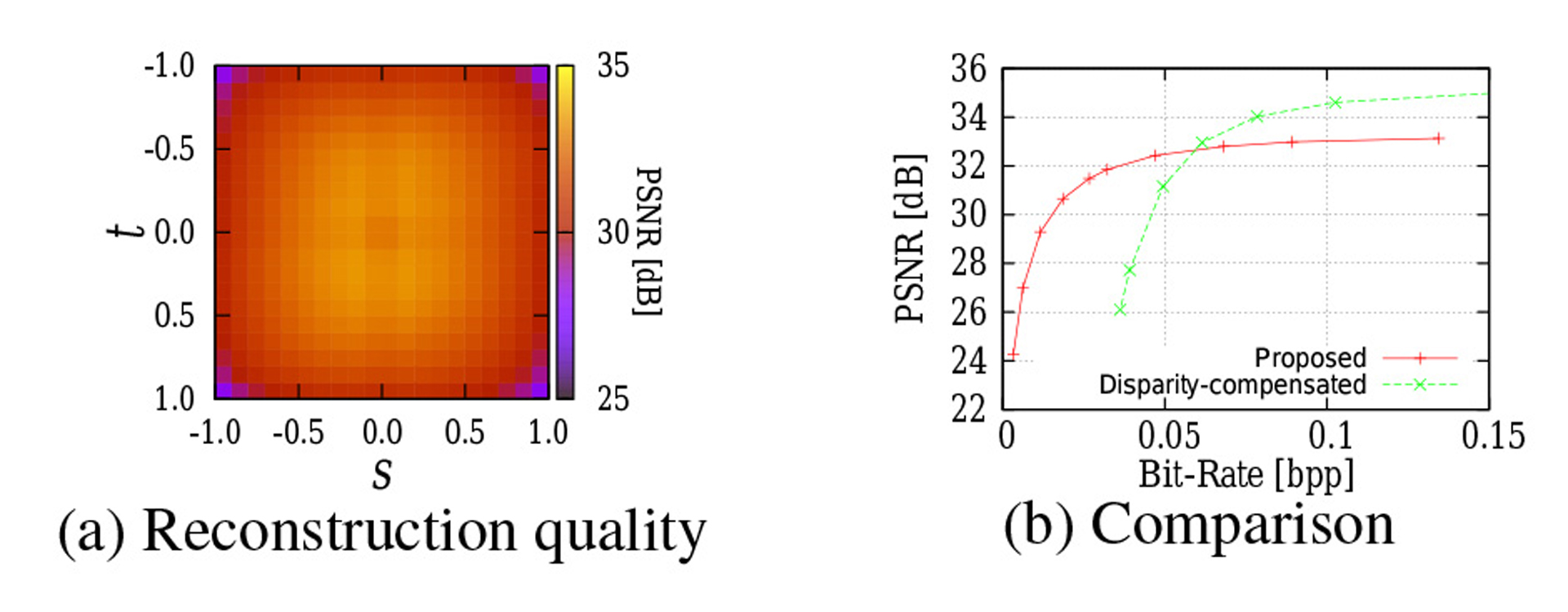
Light-Field Rendering is a promising technique generating 3-D images from multi-view images captured by dense camera arrays or lens arrays [Isaksen et al. 2000]. However, Light-Field generally consists of 4-D enormous data, that are not suitable for storing or transmitting without effective compression [Magnor and Girod 2000]. We previously derived a method of reconstructing 4-D Light-Field directly from 3-D information composed of multi-focus images without any scene estimation [Kodama et al. 2006]. On the other hand, it is easy to synthesize multi-focus images from Light-Field. Therefore, we can achieve conversion between 4-D Light-Field and 3-D multi-focus images without significant degradation. Recently, researchers in computational photography also study such interesting properties of Light-Field [Levin and Durand 2010]. In this work, based on the conversion, we propose novel global prediction for dense Light-Field compression via synthesized multi-focus images as effective representation of 3-D scenes like Figure 1.
References:
1. Isaksen, A., McMillan, L., and Gortler, S. 2000. Dynamically Reparameterized Light Fields. In Proc. ACM SIGGRAPH, 297–306.
2. Kodama, K., Mo, H., and Kubota, A. 2006. Free Viewpoint, Iris and Focus Image Generation by Using a Three-Dimensional Filtering based on Fresquency Analysis of Blurs. In Proc. IEEE ICASSP, vol. II, 625–628.
3. Kodama, K., Izawa, I., and Kubota, A. 2010. Robust Reconstruction of Arbitrarily Deformed Bokeh from Ordinary Multiple Differently Focused Images. In Proc. IEEE ICIP, 3989–3992.
4. Levin, A., and Durand, F. 2010. Linear View Synthesis Using a Dimensionality Gap Light Field Prior. In Proc. IEEE CVPR, 1831–1838.
5. Magnor, M., and Girod, B. 2000. Data Compression for Light Field Rendering. IEEE Trans. CSVT 10(3), 338–343.
6. Ota, M., Fukushima, N., Yendo, T., Tanimoto, M., and Fujii, T. 2009. Rectification of Pure Translation 2D Camera Array. In Proc. IWAIT, 0044.
7. Ou, X., Hamamoto, T., Kubota, A., and Kodama, K. 2008. Efficient free viewpoint image acquisition from multiple differently focused images. In Proc. SPIE VCIP, vol. 6822-73, 1–8.
Additional Images: