
“DeepMimic: example-guided deep reinforcement learning of physics-based character skills” by Peng, Abbeel, Levine and Panne
Conference:
Type(s):
Title:
- DeepMimic: example-guided deep reinforcement learning of physics-based character skills
Session/Category Title:
- Animation Control
Presenter(s)/Author(s):
Moderator(s):
Entry Number:
- 143
Abstract:
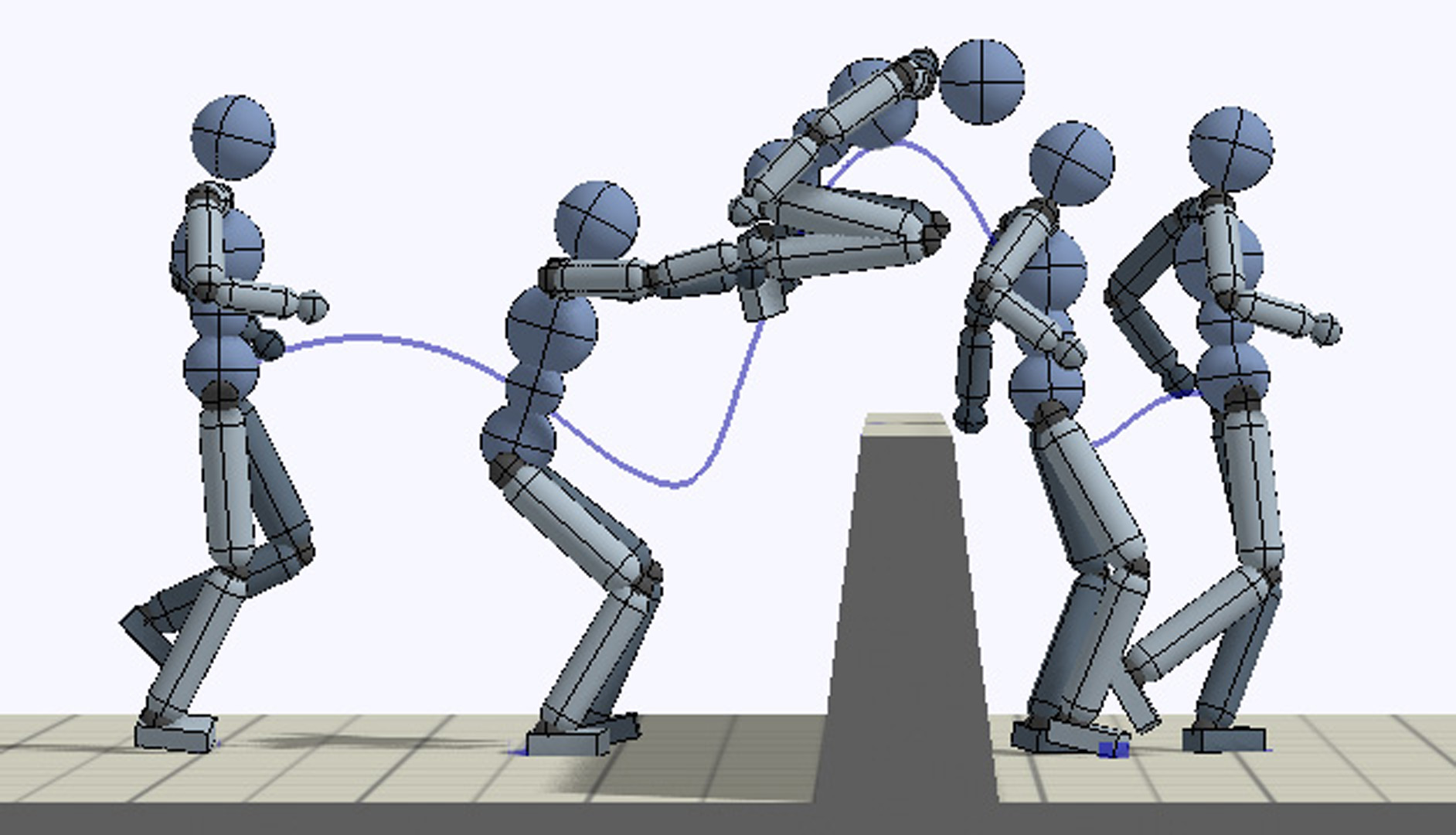
A longstanding goal in character animation is to combine data-driven specification of behavior with a system that can execute a similar behavior in a physical simulation, thus enabling realistic responses to perturbations and environmental variation. We show that well-known reinforcement learning (RL) methods can be adapted to learn robust control policies capable of imitating a broad range of example motion clips, while also learning complex recoveries, adapting to changes in morphology, and accomplishing user-specified goals. Our method handles keyframed motions, highly-dynamic actions such as motion-captured flips and spins, and retargeted motions. By combining a motion-imitation objective with a task objective, we can train characters that react intelligently in interactive settings, e.g., by walking in a desired direction or throwing a ball at a user-specified target. This approach thus combines the convenience and motion quality of using motion clips to define the desired style and appearance, with the flexibility and generality afforded by RL methods and physics-based animation. We further explore a number of methods for integrating multiple clips into the learning process to develop multi-skilled agents capable of performing a rich repertoire of diverse skills. We demonstrate results using multiple characters (human, Atlas robot, bipedal dinosaur, dragon) and a large variety of skills, including locomotion, acrobatics, and martial arts.
References:
1. Shailen Agrawal, Shuo Shen, and Michiel van de Panne. 2013. Diverse Motion Variations for Physics-based Character Animation. Symposium on Computer Animation (2013). Google ScholarDigital Library
2. Shailen Agrawal and Michiel van de Panne. 2016. Task-based Locomotion. ACM Trans. Graph. 35, 4, Article 82 (July 2016), 11 pages. Google ScholarDigital Library
3. Marc G. Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and R?mi Munos. 2016. Unifying Count-Based Exploration and Intrinsic Motivation. CoRR abs/1606.01868 (2016). arXiv:1606.01868Google Scholar
4. Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. 2016a. OpenAI Gym. CoRR abs/1606.01540 (2016). arXiv:1606.01540Google Scholar
5. Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. 2016b. OpenAI Gym. arXiv:arXiv:1606.01540Google Scholar
6. Bullet. 2015. Bullet Physics Library, http://bulletphysics.org.Google Scholar
7. Stelian Coros, Philippe Beaudoin, and Michiel van de Panne. 2009. Robust Task-based Control Policies for Physics-based Characters. ACM Trans. Graph. (Proc. SIGGRAPH Asia) 28, 5 (2009), Article 170. Google ScholarDigital Library
8. Stelian Coros, Philippe Beaudoin, and Michiel van de Panne. 2010. Generalized Biped Walking Control. ACM Transctions on Graphics 29, 4 (2010), Article 130. Google ScholarDigital Library
9. M. Da Silva, Y. Abe, and J. Popovic. 2008. Simulation of Human Motion Data using Short-Horizon Model-Predictive Control. Computer Graphics Forum (2008).Google Scholar
10. Yan Duan, Xi Chen, Rein Houthooft, John Schulman, and Pieter Abbeel. 2016. Benchmarking Deep Reinforcement Learning for Continuous Control. CoRR abs/1604.06778 (2016). arXiv:1604.06778 Google ScholarDigital Library
11. Justin Fu, John Co-Reyes, and Sergey Levine. 2017. EX2: Exploration with Exemplar Models for Deep Reinforcement Learning. In Advances in Neural Information Processing Systems 30. Curran Associates, Inc., 2574–2584.Google Scholar
12. Sehoon Ha and C Karen Liu. 2014. Iterative training of dynamic skills inspired by human coaching techniques. ACM Transactions on Graphics 34, 1 (2014). Google ScholarDigital Library
13. Perttu H?m?l?inen, Joose Rajam?ki, and C Karen Liu. 2015. Online control of simulated humanoids using particle belief propagation. ACM Transactions on Graphics (TOG) 34, 4 (2015), 81. Google ScholarDigital Library
14. Nicolas Heess, Dhruva TB, Srinivasan Sriram, Jay Lemmon, Josh Merel, Greg Wayne, Yuval Tassa, Tom Erez, Ziyu Wang, S. M. Ali Eslami, Martin A. Riedmiller, and David Silver. 2017. Emergence of Locomotion Behaviours in Rich Environments. CoRR abs/1707.02286 (2017). arXiv:1707.02286Google Scholar
15. Nicolas Heess, Gregory Wayne, Yuval Tassa, Timothy P. Lillicrap, Martin A. Riedmiller, and David Silver. 2016. Learning and Transfer of Modulated Locomotor Controllers. CoRR abs/1610.05182 (2016). arXiv:1610.05182Google Scholar
16. Jonathan Ho and Stefano Ermon. 2016. Generative Adversarial Imitation Learning. In Advances in Neural Information Processing Systems 29. Curran Associates, Inc., 4565–4573. Google ScholarDigital Library
17. Daniel Holden, Taku Komura, and Jun Saito. 2017. Phase-functioned Neural Networks for Character Control. ACM Trans. Graph. 36, 4, Article 42 (July 2017), 13 pages. Google ScholarDigital Library
18. Daniel Holden, Jun Saito, and Taku Komura. 2016. A Deep Learning Framework for Character Motion Synthesis and Editing. ACM Trans. Graph. 35, 4, Article 138 (July 2016), 11 pages. Google ScholarDigital Library
19. Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, and Pieter Abbeel. 2016. Curiosity-driven Exploration in Deep Reinforcement Learning via Bayesian Neural Networks. CoRR abs/1605.09674 (2016). arXiv:1605.09674Google ScholarDigital Library
20. Yoonsang Lee, Sungeun Kim, and Jehee Lee. 2010a. Data-driven Biped Control. In ACM SIGGRAPH 2010 Papers (SIGGRAPH ’10). ACM, New York, NY, USA, Article 129, 8 pages. Google ScholarDigital Library
21. Yoonsang Lee, Moon Seok Park, Taesoo Kwon, and Jehee Lee. 2014. Locomotion Control for Many-muscle Humanoids. ACM Trans. Graph. 33, 6, Article 218 (Nov. 2014), 11 pages. Google ScholarDigital Library
22. Yongjoon Lee, Kevin Wampler, Gilbert Bernstein, Jovan Popovi?, and Zoran Popovi?. 2010b. Motion Fields for Interactive Character Locomotion. In ACM SIGGRAPH Asia 2010 Papers (SIGGRAPH ASIA ’10). ACM, New York, NY, USA, Article 138, 8 pages. Google ScholarDigital Library
23. Sergey Levine, Jack M. Wang, Alexis Haraux, Zoran Popovi?, and Vladlen Koltun. 2012. Continuous Character Control with Low-Dimensional Embeddings. ACM Transactions on Graphics 31, 4 (2012), 28. Google ScholarDigital Library
24. Libin Liu and Jessica Hodgins. 2017. Learning to Schedule Control Fragments for Physics-Based Characters Using Deep Q-Learning. ACM Trans. Graph. 36, 3, Article 29 (June 2017), 14 pages. Google ScholarDigital Library
25. Libin Liu, Michiel van de Panne, and KangKang Yin. 2016. Guided Learning of Control Graphs for Physics-Based Characters. ACM Transactions on Graphics 35, 3 (2016). Google ScholarDigital Library
26. Libin Liu, KangKang Yin, Michiel van de Panne, Tianjia Shao, and Weiwei Xu. 2010. Sampling-based Contact-rich Motion Control. ACM Transctions on Graphics 29, 4 (2010), Article 128. Google ScholarDigital Library
27. Josh Merel, Yuval Tassa, Dhruva TB, Sriram Srinivasan, Jay Lemmon, Ziyu Wang, Greg Wayne, and Nicolas Heess. 2017. Learning human behaviors from motion capture by adversarial imitation. CoRR abs/1707.02201 (2017). arXiv:1707.02201Google Scholar
28. Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. 2015. Human-level control through deep reinforcement learning. Nature 518, 7540 (Feb. 2015), 529–533.Google ScholarCross Ref
29. Igor Mordatch, Emanuel Todorov, and Zoran Popovi?. 2012. Discovery of Complex Behaviors Through Contact-invariant Optimization. ACM Trans. Graph. 31, 4, Article 43 (July 2012), 8 pages. Google ScholarDigital Library
30. Uldarico Muico, Yongjoon Lee, Jovan Popovi?, and Zoran Popovi?. 2009. Contact-aware nonlinear control of dynamic characters. In ACM Transactions on Graphics (TOG), Vol. 28. ACM, 81. Google ScholarDigital Library
31. Ashvin Nair, Bob McGrew, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. 2017. Overcoming Exploration in Reinforcement Learning with Demonstrations. CoRR abs/1709.10089 (2017). arXiv:1709.10089Google Scholar
32. Xue Bin Peng, Glen Berseth, and Michiel van de Panne. 2015. Dynamic Terrain Traversal Skills Using Reinforcement Learning. ACM Trans. Graph. 34, 4, Article 80 (July 2015), 11 pages. Google ScholarDigital Library
33. Xue Bin Peng, Glen Berseth, and Michiel van de Panne. 2016. Terrain-Adaptive Locomotion Skills Using Deep Reinforcement Learning. ACM Transactions on Graphics (Proc. SIGGRAPH 2016) 35, 4 (2016). Google ScholarDigital Library
34. Xue Bin Peng, Glen Berseth, KangKang Yin, and Michiel van de Panne. 2017a. DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning. ACM Transactions on Graphics (Proc. SIGGRAPH 2017) 36, 4 (2017). Google ScholarDigital Library
35. Xue Bin Peng, Michiel van de Panne, and KangKang Yin. 2017b. Learning Locomotion Skills Using DeepRL: Does the Choice of Action Space Matter?. In Proc. ACM SIGGRAPH / Eurographics Symposium on Computer Animation. Google ScholarDigital Library
36. Aravind Rajeswaran, Sarvjeet Ghotra, Sergey Levine, and Balaraman Ravindran. 2016. EPOpt: Learning Robust Neural Network Policies Using Model Ensembles. CoRR abs/1610.01283 (2016). arXiv:1610.01283Google Scholar
37. Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, John Schulman, Emanuel Todorov, and Sergey Levine. 2017. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. CoRR abs/1709.10087 (2017). arXiv:1709.10087Google Scholar
38. Alla Safonova and Jessica K Hodgins. 2007. Construction and optimal search of interpolated motion graphs. In ACM Transactions on Graphics (TOG), Vol. 26. ACM, 106. Google ScholarDigital Library
39. John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. 2015a. Trust Region Policy Optimization. CoRR abs/1502.05477 (2015). arXiv:1502.05477 Google ScholarDigital Library
40. John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 2015b. High-Dimensional Continuous Control Using Generalized Advantage Estimation. CoRR abs/1506.02438 (2015). arXiv:1506.02438Google Scholar
41. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal Policy Optimization Algorithms. CoRR abs/1707.06347 (2017). arXiv:1707.06347Google Scholar
42. Dana Sharon and Michiel van de Panne. 2005. Synthesis of Controllers for Stylized Planar Bipedal Walking. In Proc. of IEEE International Conference on Robotics and Animation.Google Scholar
43. Kwang Won Sok, Manmyung Kim, and Jehee Lee. 2007. Simulating biped behaviors from human motion data. In ACM Transactions on Graphics (TOG), Vol. 26. ACM, 107. Google ScholarDigital Library
44. R. Sutton, D. Mcallester, S. Singh, and Y. Mansour. 2001. Policy Gradient Methods for Reinforcement Learning with Function Approximation. , 1057–1063 pages. Google ScholarDigital Library
45. Richard S. Sutton and Andrew G. Barto. 1998. Introduction to Reinforcement Learning (1st ed.). MIT Press, Cambridge, MA, USA. Google ScholarDigital Library
46. Jie Tan, Karen Liu, and Greg Turk. 2011. Stable Proportional-Derivative Controllers. IEEE Comput. Graph. Appl. 31, 4 (2011), 34–44. Google ScholarDigital Library
47. Yuval Tassa, Tom Erez, and Emanuel Todorov. 2012. Synthesis and stabilization of complex behaviors through online trajectory optimization. In Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ International Conference on. IEEE, 4906–4913.Google ScholarCross Ref
48. Yee Whye Teh, Victor Bapst, Wojciech Marian Czarnecki, John Quan, James Kirkpatrick, Raia Hadsell, Nicolas Heess, and Razvan Pascanu. 2017. Distral: Robust Multitask Reinforcement Learning. CoRR abs/1707.04175 (2017). arXiv:1707.04175Google Scholar
49. Kevin Wampler, Zoran Popovi?, and Jovan Popovi?. 2014. Generalizing Locomotion Style to New Animals with Inverse Optimal Regression. ACM Trans. Graph. 33, 4, Article 49 (July 2014), 11 pages. Google ScholarDigital Library
50. Jack M. Wang, Samuel R. Hamner, Scott L. Delp, Vladlen Koltun, and More Specifically. 2012. Optimizing locomotion controllers using biologically-based actuators and objectives. ACM Trans. Graph (2012). Google ScholarDigital Library
51. Ronald J. Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning 8, 3 (01 May 1992), 229–256. Google ScholarDigital Library
52. Jungdam Won, Jongho Park, Kwanyu Kim, and Jehee Lee. 2017. How to Train Your Dragon: Example-guided Control of Flapping Flight. ACM Trans. Graph. 36, 6, Article 198 (Nov. 2017), 13 pages. Google ScholarDigital Library
53. Yuting Ye and C Karen Liu. 2010a. Optimal feedback control for character animation using an abstract model. In ACM Transactions on Graphics (TOG), Vol. 29. ACM, 74. Google ScholarDigital Library
54. Yuting Ye and C. Karen Liu. 2010b. Synthesis of Responsive Motion Using a Dynamic Model. Computer Graphics Forum 29, 2 (2010), 555–562.Google ScholarCross Ref
55. KangKang Yin, Kevin Loken, and Michiel van de Panne. 2007. SIMBICON: Simple Biped Locomotion Control. ACM Trans. Graph. 26, 3 (2007), Article 105. Google ScholarDigital Library