
“DeepLoco: dynamic locomotion skills using hierarchical deep reinforcement learning” by Peng, Berseth, Yin and Panne
Conference:
Type(s):
Title:
- DeepLoco: dynamic locomotion skills using hierarchical deep reinforcement learning
Session/Category Title: Learning to Move
Presenter(s)/Author(s):
Moderator(s):
Abstract:
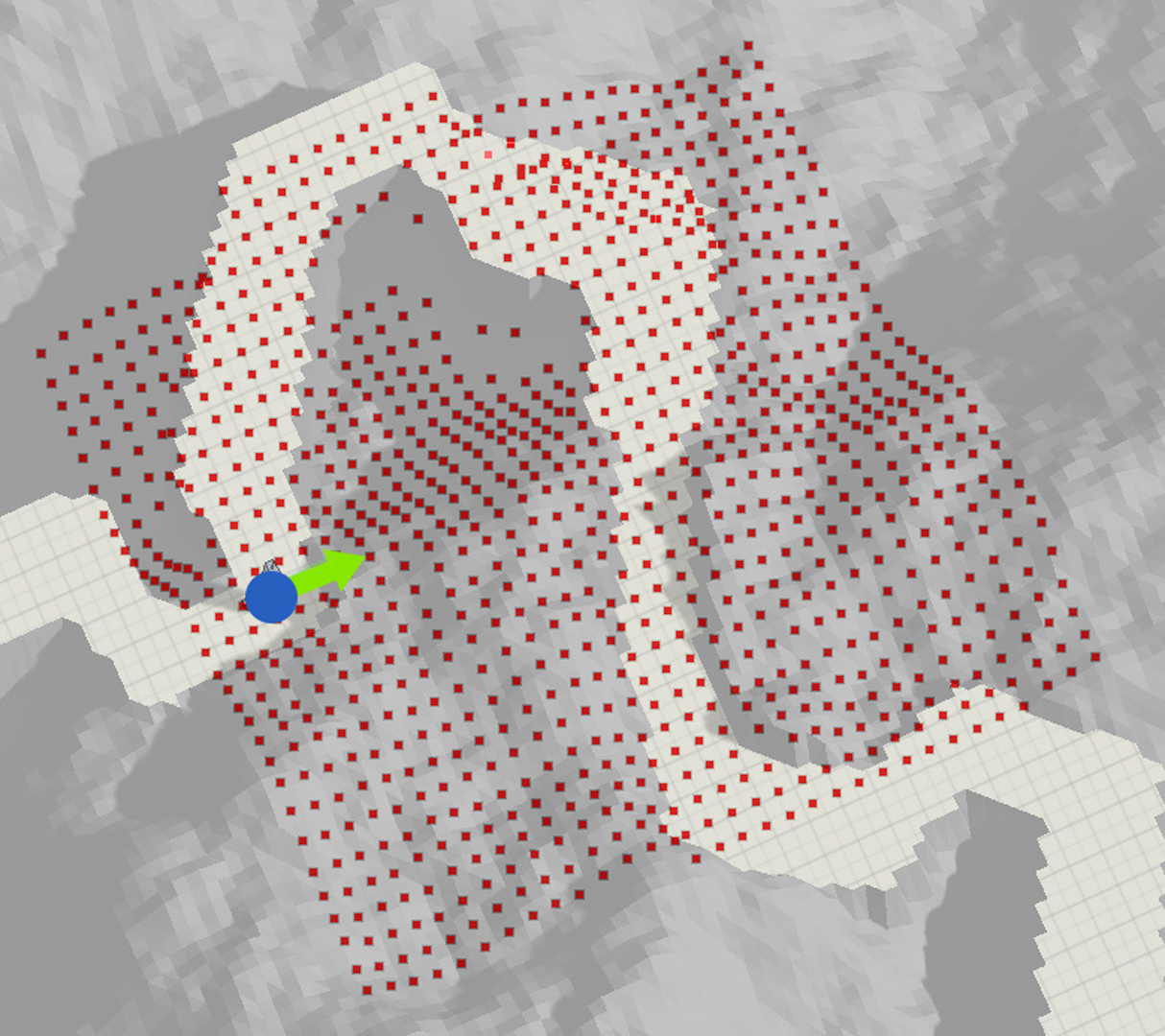
Learning physics-based locomotion skills is a difficult problem, leading to solutions that typically exploit prior knowledge of various forms. In this paper we aim to learn a variety of environment-aware locomotion skills with a limited amount of prior knowledge. We adopt a two-level hierarchical control framework. First, low-level controllers are learned that operate at a fine timescale and which achieve robust walking gaits that satisfy stepping-target and style objectives. Second, high-level controllers are then learned which plan at the timescale of steps by invoking desired step targets for the low-level controller. The high-level controller makes decisions directly based on high-dimensional inputs, including terrain maps or other suitable representations of the surroundings. Both levels of the control policy are trained using deep reinforcement learning. Results are demonstrated on a simulated 3D biped. Low-level controllers are learned for a variety of motion styles and demonstrate robustness with respect to force-based disturbances, terrain variations, and style interpolation. High-level controllers are demonstrated that are capable of following trails through terrains, dribbling a soccer ball towards a target location, and navigating through static or dynamic obstacles.
References:
1. Mazen Al Borno, Martin de Lasa, and Aaron Hertzmann. 2013. Trajectory Optimization for Full-Body Movements with Complex Contacts. TVCG 19, 8 (2013), 1405–1414. Google ScholarDigital Library
2. Yunfei Bai, Kristin Siu, and C Karen Liu. 2012. Synthesis of concurrent object manipulation tasks. ACM Transactions on Graphics (TOG) 31, 6 (2012), 156.Google ScholarDigital Library
3. Bullet. 2015. Bullet Physics Library. (2015). http://bulletphysics.org.Google Scholar
4. Joel Chestnutt, Manfred Lau, German Cheung, James Kuffner, Jessica Hodgins, and Takeo Kanade. 2005. Footstep Planning for the Honda ASIMO Humanoid. In ICRA05. 629–634.Google Scholar
5. Stelian Coros, Philippe Beaudoin, and Michiel van de Panne. 2009. Robust task-based control policies for physics-based characters. ACM Transctions on Graphics 28, 5 (2009), Article 170.Google Scholar
6. Stelian Coros, Philippe Beaudoin, and Michiel van de Panne. 2010. Generalized Biped Walking Control. ACM Transctions on Graphics 29, 4 (2010), Article 130.Google Scholar
7. Stelian Coros, Philippe Beaudoin, Kang Kang Yin, and Michiel van de Panne. 2008. Synthesis of constrained walking skills. ACM Trans. Graph. 27, 5 (2008), Article 113. Google ScholarDigital Library
8. Stelian Coros, Andrej Karpathy, Ben Jones, Lionel Reveret, and Michiel van de Panne. 2011. Locomotion Skills for Simulated Quadrupeds. ACM Transactions on Graphics 30, 4 (2011), Article 59. Google ScholarDigital Library
9. Marco da Silva, Yeuhi Abe, and Jovan Popović. 2008. Interactive simulation of stylized human locomotion. ACM Trans. Graph. 27, 3 (2008), Article 82. Google ScholarDigital Library
10. Martin de Lasa, Igor Mordatch, and Aaron Hertzmann. 2010. Feature-based locomotion controllers. In ACM Transactions on Graphics (TOG), Vol. 29. ACM, 131. Google ScholarDigital Library
11. Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. 2016. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. CoRR abs/1606.01847 (2016). http://arxiv.org/abs/1606.01847Google Scholar
12. Thomas Geijtenbeek and Nicolas Pronost. 2012. Interactive Character Animation Using Simulated Physics: A State-of-the-Art Review. In Computer Graphics Forum, Vol. 31. Wiley Online Library, 2492–2515. Google ScholarDigital Library
13. Michael X. Grey, Aaron D. Ames, and C. Karen Liu. 2016. Footstep and Motion Planning in Semi-unstructured Environments Using Possibility Graphs. CoRR abs/1610.00700 (2016). http://arxiv.org/abs/1610.00700Google Scholar
14. Radek Grzeszczuk, Demetri Terzopoulos, and Geoffrey Hinton. 1998. Neuroanimator: Fast neural network emulation and control of physics-based models. In Proceedings of the 25th annual conference on Computer graphics and interactive techniques. ACM, 9–20. Google ScholarDigital Library
15. Perttu Hämäläinen, Joose Rajamäki, and C Karen Liu. 2015. Online control of simulated humanoids using particle belief propagation. ACM Transactions on Graphics (TOG) 34, 4 (2015), 81.Google ScholarDigital Library
16. Nikolaus Hansen. 2006. The CMA Evolution Strategy: A Comparing Review. In Towards a New Evolutionary Computation. 75–102. Google ScholarCross Ref
17. Nicolas Heess, Gregory Wayne, Yuval Tassa, Timothy P. Lillicrap, Martin A. Riedmiller, and David Silver. 2016. Learning and Transfer of Modulated Locomotor Controllers. CoRR abs/1610.05182 (2016). http://arxiv.org/abs/1610.05182Google Scholar
18. J. K. Hodgins, W. L. Wooten, D. C. Brogan, and J. F. O’Brien. 1995. Animating Human Athletics. In Proceedings of SIGGRAPH 1995. 71–78. Google ScholarDigital Library
19. Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. 2014. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the ACM International Conference on Multimedia (MM ’14). ACM, 675–678. Google ScholarDigital Library
20. L. E. Kavraki, P. Svestka, J.-C. Latombe, and M. H. Overmars. 1996. Probabilistic Roadmaps for Path Planning in High-Dimensional Configuration Spaces. IEEE Transactions on Robotics & Automation 12, 4 (1996), 566–580. Google ScholarCross Ref
21. James Kuffner, Koichi Nishiwaki, Satoshi Kagami, Masayuki Inaba, and Hirochika Inoue. 2005. Motion Planning for Humanoid Robots. Springer Berlin Heidelberg, 365–374.Google Scholar
22. Manfred Lau and James Kuffner. 2005. Behavior planning for character animation. In SCA ’05: Proceedings of the 2005 ACM SIGGRAPH/Eurographics symposium on Computer animation. 271–280. Google ScholarDigital Library
23. Jehee Lee and Kang Hoon Lee. 2004. Precomputing Avatar Behavior from Human Motion Data. In Proceedings of the 2004 ACM SIGGRAPH/Eurographics Symposium on Computer Animation (SCA ’04). 79–87. Google ScholarDigital Library
24. Yoonsang Lee, Sungeun Kim, and Jehee Lee. 2010. Data-Driven Biped Control. ACM Transctions on Graphics 29, 4 (2010), Article 129.Google Scholar
25. Sergey Levine and Pieter Abbeel. 2014. Learning Neural Network Policies with Guided Policy Search under Unknown Dynamics. In Advances in Neural Information Processing Systems 27, Z. Ghahramani, M. Welling, C. Cortes, N.D. Lawrence, and K.Q. Weinberger (Eds.). Curran Associates, Inc., 1071–1079.Google ScholarDigital Library
26. Sergey Levine and Vladlen Koltun. 2013. Guided Policy Search. In ICML ’13: Proceedings of the 30th International Conference on Machine Learning.Google Scholar
27. Sergey Levine and Vladlen Koltun. 2014. Learning complex neural network policies with trajectory optimization. In Proceedings of the 31st International Conference on Machine Learning (ICML-14). 829–837.Google Scholar
28. Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2015. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971 (2015).Google Scholar
29. Libin Liu, Michiel van de Panne, and KangKang Yin. 2016. Guided Learning of Control Graphs for Physics-based Characters. ACM Trans. Graph. 35, 3 (2016), Article 29. Google ScholarDigital Library
30. Libin Liu, KangKang Yin, Michiel van de Panne, and Baining Guo. 2012. Terrain runner: control, parameterization, composition, and planning for highly dynamic motions. ACM Trans. Graph. 31, 6 (2012), 154. Google ScholarDigital Library
31. Adriano Macchietto, Victor Zordan, and Christian R. Shelton. 2009. Momentum Control for Balance. In ACM SIGGRAPH 2009 Papers (SIGGRAPH ’09). ACM, New York, NY, USA, Article 80, 8 pages. Google ScholarDigital Library
32. Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 2016. Asynchronous Methods for Deep Reinforcement Learning. CoRR abs/1602.01783 (2016). http://arxiv.org/abs/1602.01783Google Scholar
33. Igor Mordatch, Martin de Lasa, and Aaron Hertzmann. 2010. Robust physics-based locomotion using low-dimensional planning. ACM Trans. Graph. 29, 4 (2010), Article 71. Google ScholarDigital Library
34. Igor Mordatch, Kendall Lowrey Galen Andrew, Zoran Popovic, and Emanuel V Todorov. 2015. Interactive Control of Diverse Complex Characters with Neural Networks. In Advances in Neural Information Processing Systems. 3114–3122.Google Scholar
35. Igor Mordatch and Emanuel Todorov. 2014. Combining the benefits of function approximation and trajectory optimization. In Robotics: Science and Systems (RSS). Google ScholarCross Ref
36. Uldarico Muico, Yongjoon Lee, Jovan Popović, and Zoran Popović. 2009. Contact-aware nonlinear control of dynamic characters. ACM Trans. Graph. 28, 3 (2009), Article 81. Google ScholarDigital Library
37. Vinod Nair and Geoffrey E. Hinton. 2010. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Johannes FÃijrnkranz and Thorsten Joachims (Eds.). Omnipress, 807–814. http://www.icml2010.org/papers/432.pdfGoogle ScholarDigital Library
38. Xue Bin Peng, Glen Berseth, and Michiel van de Panne. 2015. Dynamic Terrain Traversal Skills Using Reinforcement Learning. ACM Transactions on Graphics 34, 4 (2015), Article 80.Google ScholarDigital Library
39. Xue Bin Peng, Glen Berseth, and Michiel van de Panne. 2016. Terrain-Adaptive Locomotion Skills Using Deep Reinforcement Learning. ACM Transactions on Graphics 35, 4 (2016), Article 81.Google ScholarDigital Library
40. Xue Bin Peng and Michiel van de Panne. 2016. Learning Locomotion Skills Using DeepRL: Does the Choice of Action Space Matter? CoRR abs/1611.01055 (2016). http://arxiv.org/abs/1611.01055Google Scholar
41. Ken Perlin. 2002. Improving Noise. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’02). ACM, New York, NY, USA, 681–682. Google ScholarDigital Library
42. Julien PettrÃl’, Jean-Paul Laumond, and Thierry SimÃl’on. 2003. 2-Stages Locomotion Planner for Digital Actors. In SCA ’03: Proceedings of the 2010 ACM SIGGRAPH/Eurographics symposium on Computer animation. 258–264.Google Scholar
43. John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. 2015. Trust Region Policy Optimization. CoRR abs/1502.05477 (2015). http://arxiv.org/abs/1502.05477Google Scholar
44. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. 2016. High-dimensional continuous control using generalized advantage estimation. In International Conference on Learning Representations (ICLR 2016).Google Scholar
45. Kwang Won Sok, Manmyung Kim, and Jehee Lee. 2007. Simulating biped behaviors from human motion data. ACM Trans. Graph. 26, 3 (2007), Article 107. Google ScholarDigital Library
46. Richard S. Sutton, David Mcallester, Satinder Singh, and Yishay Mansour. 2000. Policy gradient methods for reinforcement learning with function approximation. In In Advances in Neural Information Processing Systems 12. MIT Press, 1057–1063.Google Scholar
47. Jie Tan, Yuting Gu, C Karen Liu, and Greg Turk. 2014. Learning bicycle stunts. ACM Transactions on Graphics (TOG) 33, 4 (2014), 50.Google ScholarDigital Library
48. Jie Tan, Karen Liu, and Greg Turk. 2011. Stable proportional-derivative controllers. Computer Graphics and Applications, IEEE 31, 4 (2011), 34–44. Google ScholarDigital Library
49. Yuval Tassa, Tom Erez, and Emanuel Todorov. 2012. Synthesis and stabilization of complex behaviors through online trajectory optimization. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 4906–4913. Google ScholarCross Ref
50. Hado Van Hasselt. 2012. Reinforcement learning in continuous state and action spaces. In Reinforcement Learning. Springer, 207–251. Google ScholarCross Ref
51. Jack M. Wang, David J. Fleet, and Aaron Hertzmann. 2009. Optimizing Walking Controllers. ACM Transctions on Graphics 28, 5 (2009), Article 168.Google Scholar
52. David Wooden, Matthew Malchano, Kevin Blankespoor, Andrew Howardy, Alfred A. Rizzi, and Marc Raibert. 2010. Autonomous Navigation for BigDog. In ICRA10. 4736–4741. Google ScholarCross Ref
53. Jia-chi Wu and Zoran Popović. 2010. Terrain-adaptive bipedal locomotion control. ACM Transactions on Graphics 29, 4 (Jul. 2010), 72:1–72:10.Google Scholar
54. Katsu Yamane, James J. Kuffner, and Jessica K. Hodgins. 2004. Synthesizing animations of human manipulation tasks. ACM Trans. Graph. 23, 3 (2004), 532–539. Google ScholarDigital Library
55. Yuting Ye and C. Karen Liu. 2010. Optimal Feedback Control for Character Animation Using an Abstract Model. ACM Trans. Graph. 29, 4 (2010), Article 74. Google ScholarDigital Library
56. KangKang Yin, Stelian Coros, Philippe Beaudoin, and Michiel van de Panne. 2008. Continuation Methods for Adapting Simulated Skills. ACM Transctions on Graphics 27, 3 (2008), Article 81.Google Scholar
57. KangKang Yin, Kevin Loken, and Michiel van de Panne. 2007. SIMBICON: Simple Biped Locomotion Control. ACM Transctions on Graphics 26, 3 (2007), Article 105.Google ScholarDigital Library
58. Petr Zaytsev, S Javad Hasaneini, and Andy Ruina. 2015. Two steps is enough: no need to plan far ahead for walking balance. In 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 6295–6300. Google ScholarCross Ref