
“Automatically scheduling halide image processing pipelines”
Conference:
Type(s):
Title:
- Automatically scheduling halide image processing pipelines
Session/Category Title: OPTIMIZING IMAGE PROCESSING
Presenter(s)/Author(s):
Moderator(s):
Abstract:
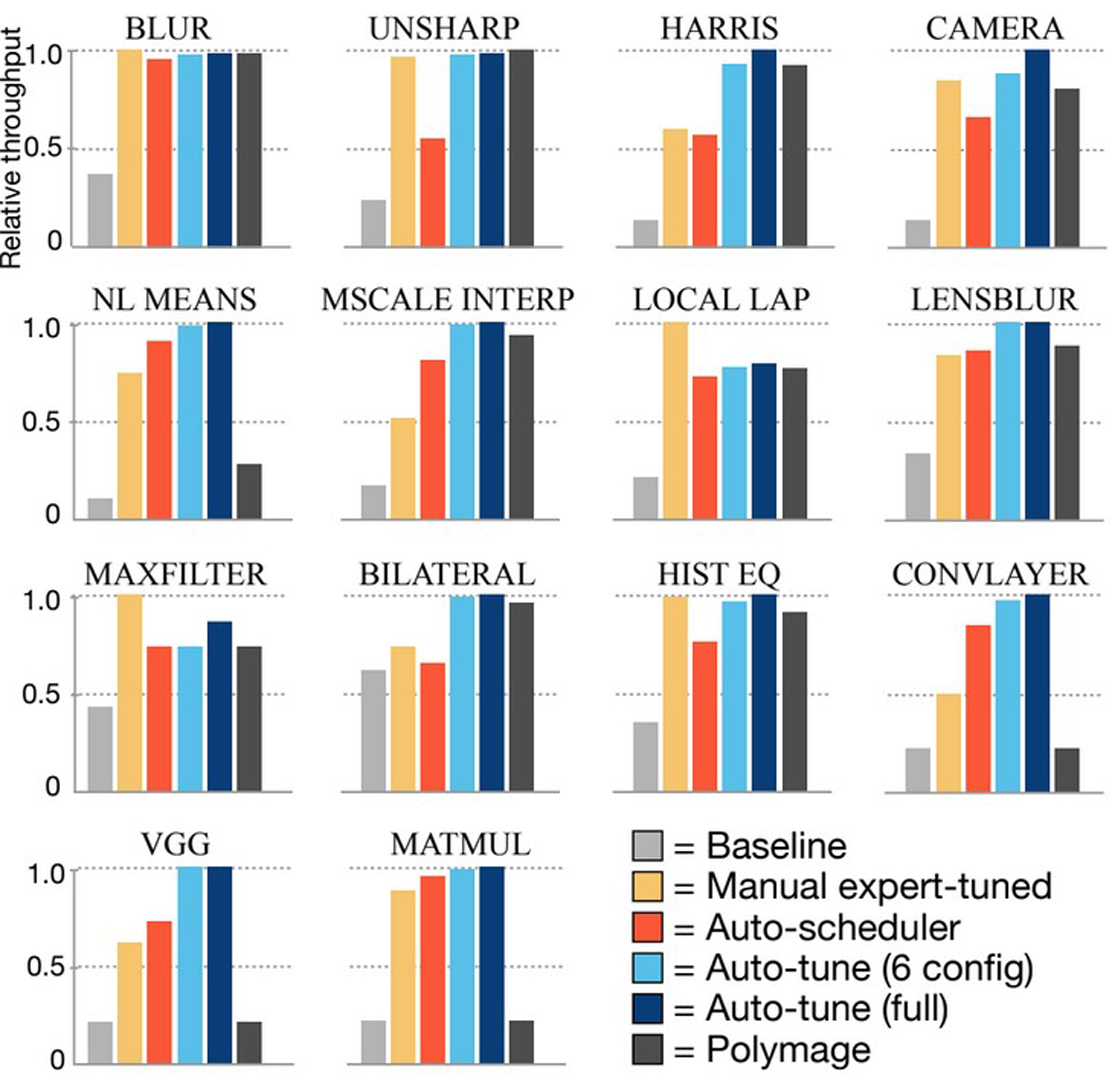
The Halide image processing language has proven to be an effective system for authoring high-performance image processing code. Halide programmers need only provide a high-level strategy for mapping an image processing pipeline to a parallel machine (a schedule), and the Halide compiler carries out the mechanical task of generating platform-specific code that implements the schedule. Unfortunately, designing high-performance schedules for complex image processing pipelines requires substantial knowledge of modern hardware architecture and code-optimization techniques. In this paper we provide an algorithm for automatically generating high-performance schedules for Halide programs. Our solution extends the function bounds analysis already present in the Halide compiler to automatically perform locality and parallelism-enhancing global program transformations typical of those employed by expert Halide developers. The algorithm does not require costly (and often impractical) auto-tuning, and, in seconds, generates schedules for a broad set of image processing benchmarks that are performance-competitive with, and often better than, schedules manually authored by expert Halide developers on server and mobile CPUs, as well as GPUs.
References:
1. Adams, A., Talvala, E.-V., Park, S. H., Jacobs, D. E., Ajdin, B., Gelfand, N., Dolson, J., Vaquero, D., Baek, J., Tico, M., Lensch, H. P. A., Matusik, W., Pulli, K., Horowitz, M., and Levoy, M. 2010. The frankencamera: An experimental platform for computational photography. ACM Transactions on Graphics 29, 4 (July), 29:1–29:12. Google ScholarDigital Library
2. Ansel, J., Kamil, S., Veeramachaneni, K., Ragan-Kelley, J., Bosboom, J., O’Reilly, U.-M., and Amarasinghe, S. 2014. OpenTuner: An extensible framework for program autotuning. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation, ACM, 303–316. Google ScholarDigital Library
3. Chen, J., Paris, S., and Durand, F. 2007. Real-time edge-aware image processing with the bilateral grid. ACM Transactions on Graphics 26, 3 (July), 103:1–103:9. Google ScholarDigital Library
4. Darbon, J., Cunha, A., Chan, T. F., Osher, S., and Jensen, G. J. 2008. Fast nonlocal filtering applied to electron cryomicroscopy. In Biomedical Imaging: From Nano to Macro, 2008. ISBI 2008. 5th IEEE International Symposium on, IEEE, 1331–1334.Google Scholar
5. Farbman, Z., Fattal, R., and Lischinski, D. 2011. Convolution pyramids. ACM Transactions on Graphics 30, 6 (Dec.), 175:1–175:8. Google ScholarDigital Library
6. Harris, C., and Stephens, M. 1988. A combined corner and edge detector. In In Proc. of Fourth Alvey Vision Conference, 147–151.Google Scholar
7. Hegarty, J., Brunhaver, J., DeVito, Z., Ragan-Kelley, J., Cohen, N., Bell, S., Vasilyev, A., Horowitz, M., and Hanrahan, P. 2014. Darkroom: compiling high-level image processing code into hardware pipelines. ACM Transactions on Graphics 33, 4 (July), 144:1–144:11. Google ScholarDigital Library
8. Hegarty, J., Daly, R., DeVito, Z., Ragan-Kelley, J., Horowitz, M., and Hanrahan, P. 2016. Rigel: Flexible multi-rate image processing hardware. ACM Transactions on Graphics 36, 4 (July). Google ScholarDigital Library
9. Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., and Darrell, T. 2014. Caffe: Convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093.Google Scholar
10. Krizhevsky, A., Sutskever, I., and Hinton, G. E. 2012. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, 1097–1105.Google Scholar
11. Mullapudi, R. T., Vasista, V., and Bondhugula, U. 2015. PolyMage: Automatic optimization for image processing pipelines. In Proceedings of the Twentieth International Conference on Architectural Support for Programming Languages and Operating Systems, 429–443. Google ScholarDigital Library
12. Paris, S., Hasinoff, S. W., and Kautz, J. 2011. Local Laplacian filters: edge-aware image processing with a Laplacian pyramid. ACM Transactions on Graphics 30, 4 (July), 68:1–68:12. Google ScholarDigital Library
13. Ragan-Kelley, J., Adams, A., Paris, S., Levoy, M., Amarasinghe, S., and Durand, F. 2012. Decoupling algorithms from schedules for easy optimization of image processing pipelines. ACM Transactions on Graphics 31, 4 (July), 32:1–32:12. Google ScholarDigital Library
14. Ragan-Kelley, J., Barnes, C., Adams, A., Paris, S., Durand, F., and Amarasinghe, S. 2013. Halide: A language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, 519–530. Google ScholarDigital Library
15. Ragan-Kelley, J., Adams, A., and Sharlet, D. 2015. An introduction to Halide. In ACM SIGGRAPH 2015 Courses, ACM, 3:1–3:160. Google ScholarDigital Library
16. Rhemann, C., Hosni, A., Bleyer, M., Rother, C., and Gelautz, M. 2011. Fast cost-volume filtering for visual correspondence and beyond. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, 3017–3024. Google ScholarDigital Library
17. Simonyan, K., and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.Google Scholar