
“Audio-driven facial animation by joint end-to-end learning of pose and emotion”
Conference:
Type(s):
Title:
- Audio-driven facial animation by joint end-to-end learning of pose and emotion
Session/Category Title: Speech and Facial Animation
Presenter(s)/Author(s):
Moderator(s):
Abstract:
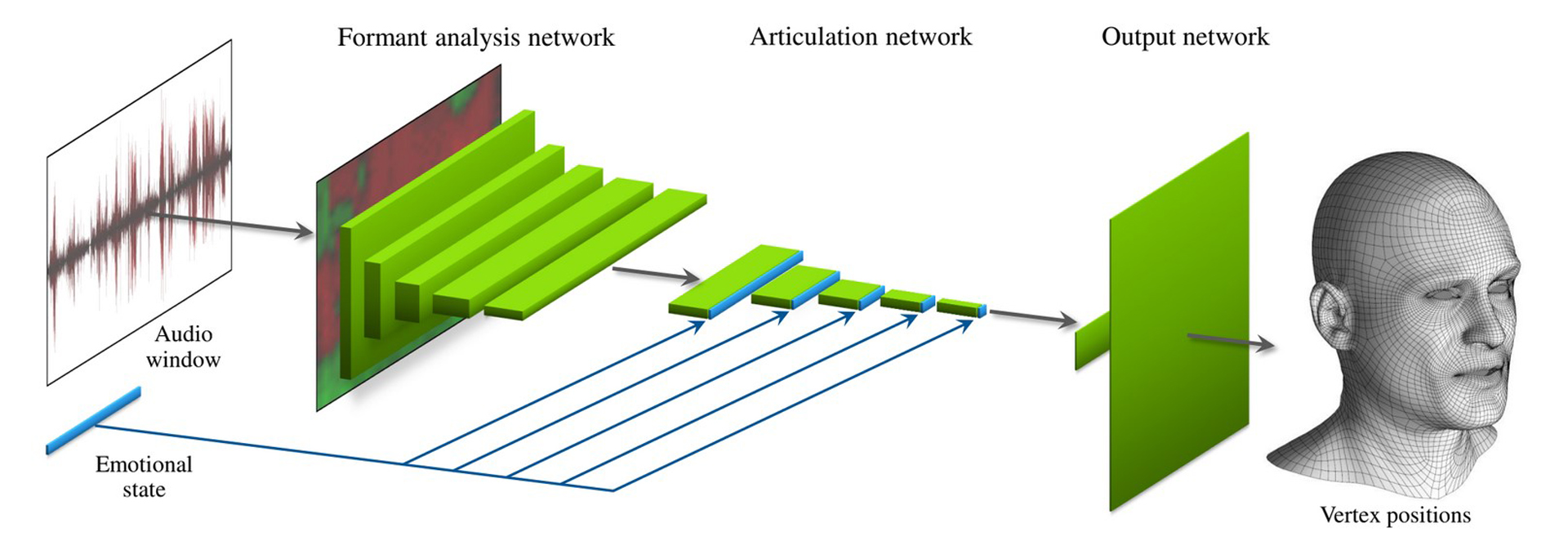
We present a machine learning technique for driving 3D facial animation by audio input in real time and with low latency. Our deep neural network learns a mapping from input waveforms to the 3D vertex coordinates of a face model, and simultaneously discovers a compact, latent code that disambiguates the variations in facial expression that cannot be explained by the audio alone. During inference, the latent code can be used as an intuitive control for the emotional state of the face puppet.We train our network with 3–5 minutes of high-quality animation data obtained using traditional, vision-based performance capture methods. Even though our primary goal is to model the speaking style of a single actor, our model yields reasonable results even when driven with audio from other speakers with different gender, accent, or language, as we demonstrate with a user study. The results are applicable to in-game dialogue, low-cost localization, virtual reality avatars, and telepresence.
References:
1. Robert Anderson, Björn Stenger, Vincent Wan, and Roberto Cipolla. 2013. Expressive visual text-to-speech using active appearance models. In Proc. CVPR. 3382–3389. Google ScholarDigital Library
2. Mohamed Benzeghiba, Renato De Mori, Olivier Deroo, Stephane Dupont, Teodora Erbes, Denis Jouvet, Luciano Fissore, Pietro Laface, Alfred Mertins, Christophe Ris, and others. 2007. Automatic speech recognition and speech variability: A review. In Speech Communication, Vol. 49. 763–786. Google ScholarDigital Library
3. Matthew Brand. 1999. Voice Puppetry. In Proc. ACM SIGGRAPH. 21–28. Google ScholarDigital Library
4. Yong Cao, Petros Faloutsos, and Frédéric Pighin. 2003. Unsupervised Learning for Speech Motion Editing. In Proc. SCA. 225–231.Google Scholar
5. Yong Cao, Wen C. Tien, Petros Faloutsos, and Frédéric Pighin. 2005. Expressive Speech-driven Facial Animation. ACM Trans. Graph. 24, 4 (2005), 1283–1302. Google ScholarDigital Library
6. Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. cuDNN: Efficient Primitives for Deep Learning. arXiv:1410.0759 (2014).Google Scholar
7. E. S. Chuang, F. Deshpande, and C. Bregler. 2002. Facial expression space learning. In Proc. Pacific Graphics. 68–76. Google ScholarCross Ref
8. Michael M. Cohen and Dominic W. Massaro. 1993. Modeling Coarticulation in Synthetic Visual Speech. In Models and Techniques in Computer Animation. 139–156.Google Scholar
9. Salil Deena and Aphrodite Galata. 2009. Speech-Driven Facial Animation Using a Shared Gaussian Process Latent Variable Model. In Proc. Symposium on Advances in Visual Computing: Part I. 89–100. Google ScholarDigital Library
10. S. Deena, S. Hou, and A. Galata. 2013. Visual Speech Synthesis Using a Variable-Order Switching Shared Gaussian Process Dynamical Model. IEEE Transactions on Multimedia 15, 8 (2013), 1755–1768. Google ScholarDigital Library
11. Zhigang Deng, Shri Narayanan, Carlos Busso, and Ulrich Neumann. 2004. Audio-based Head Motion Synthesis for Avatar-based Telepresence Systems. In Proc. Workshop on Effective Telepresence. 24–30. Google ScholarDigital Library
12. Zhigang Deng, Ulrich Neumann, J. P. Lewis, Tae-Yong Kim, Murtaza Bulut, and Shrikanth Narayanan. 2006. Expressive Facial Animation Synthesis by Learning Speech Coarticulation and Expression Spaces. IEEE TVCG 12, 6 (2006), 1523–1534.Google Scholar
13. Sander Dieleman, Jan Schlüter, Colin Raffel, Eben Olson, Søren Kaae Sønderby, and others. 2015. Lasagne: First release. (2015).Google Scholar
14. Pif Edwards, Chris Landreth, Eugene Fiume, and Karan Singh. 2016. JALI: An Animator-centric Viseme Model for Expressive Lip Synchronization. ACM Trans. Graph. 35, 4 (2016), 127:1–127:11.Google ScholarDigital Library
15. A. Elgammal and Chan-Su Lee. 2004. Separating style and content on a nonlinear manifold. In Proc. CVPR, Vol. 1. 478–485. Google ScholarCross Ref
16. Tony Ezzat, Gadi Geiger, and Tomaso Poggio. 2002. Trainable Videorealistic Speech Animation. ACM Trans. Graph. 21, 3 (2002), 388–398. Google ScholarDigital Library
17. Bo Fan, Lei Xie, Shan Yang, Lijuan Wang, and Frank K. Soong. 2016. A deep bidirectional LSTM approach for video-realistic talking head. Multimedia Tools and Applications 75, 9 (2016), 5287–5309. Google ScholarDigital Library
18. Cletus G. Fisher. 1968. Confusions Among Visually Perceived Consonants. JSLHR 11 (1968), 796–804. Google ScholarCross Ref
19. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv:1502.01852 (2015).Google Scholar
20. Gregor Hofer and Korin Richmond. 2010. Comparison of HMM and TMDN Methods for Lip Synchronisation. In Proc. Interspeech. 454–457.Google Scholar
21. Pengyu Hong, Zhen Wen, and T. S. Huang. 2002. Real-time Speech-driven Face Animation with Expressions Using Neural Networks. Trans. Neur. Netw. 13, 4 (2002), 916–927. Google ScholarDigital Library
22. Sergey Ioffe and Christian Szegedy. 2015. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv:1502.03167 (2015).Google Scholar
23. Jia Jia, Zhiyong Wu, Shen Zhang, Helen M. Meng, and Lianhong Cai. 2014. Head and facial gestures synthesis using PAD model for an expressive talking avatar. Multimedia Tools and Applications 73, 1 (2014), 439–461. Google ScholarDigital Library
24. Diederik P. Kingma and Jimmy Ba. 2014. Adam: A Method for Stochastic Optimization. arXiv:1412.6980 (2014).Google Scholar
25. S. Kshirsagar and N. Magnenat-Thalmann. 2000. Lip synchronization using linear predictive analysis. In Proc. ICME, Vol. 2. 1077–1080. Google ScholarCross Ref
26. John Lewis. 1991. Automated lip-sync: Background and techniques. The Journal of Visualization and Computer Animation 2, 4 (1991), 118–122. Google ScholarCross Ref
27. J. P. Lewis, Ken Anjyo, Taehyun Rhee, Mengjie Zhang, Fred Pighin, and Zhigang Deng. 2014. Practice and Theory of Blendshape Facial Models. In Eurographics (State of the Art Reports).Google Scholar
28. J. P. Lewis and F. I. Parke. 1987. Automated Lip-synch and Speech Synthesis for Character Animation. In Proc. SIGCHI/GI Conference on Human Factors in Computing Systems and Graphics Interface. 143–147. Google ScholarDigital Library
29. K. Liu and J. Ostermann. 2011. Realistic facial expression synthesis for an image-based talking head. In Proc. ICME. 1–6. Google ScholarDigital Library
30. M. Malcangi. 2010. Text-driven avatars based on artificial neural networks and fuzzy logic. Int. J. Comput. 4, 2 (2010), 61–69.Google Scholar
31. Stacy Marsella, Yuyu Xu, Margaux Lhommet, Andrew Feng, Stefan Scherer, and Ari Shapiro. 2013. Virtual Character Performance from Speech. In Proc. SCA. 25–35. Google ScholarDigital Library
32. D. W. Massaro, J. Beskow, M. M. Cohen, C. L. Fry, and T. Rodriguez. 1999. Picture my voice: Audio to visual speech synthesis using artificial neural networks. In Proc. AVSP. #23.Google Scholar
33. D. W. Massaro, M. M. Cohen, R. Clark, and M. Tabain. 2012. Animated speech: Research progress and applications. In Audiovisual Speech Processing. 309–345.Google Scholar
34. Wesley Mattheyses and Werner Verhelst. 2015. Audiovisual speech synthesis: An overview of the state-of-the-art. Speech Communication 66 (2 2015), 182–217.Google Scholar
35. J. Melenchon, E. Martinez, F. De La Torre, and J. A. Montero. 2009. Emphatic Visual Speech Synthesis. IEEE Transactions on Audio, Speech, and Language Processing 17, 3 (2009), 459–468. Google ScholarDigital Library
36. M. Mori. 1970. Bukimi no tani (The uncanny valley). Energy 7, 4 (1970), 33–35.Google Scholar
37. T. Öhman and G. Salvi. 1999. Using HMMs and ANNs for mapping acoustic to visual speech. IEEE Journal of Selected Topics in Signal Processing 40, 1 (1999), 45–50.Google Scholar
38. Valery A. Petrushin. 1998. How well can People and Computers Recognize Emotions in Speech?. In Proc. AAAI Fall Symp. 141–145.Google Scholar
39. D. Schabus, M. Pucher, and G. Hofer. 2014. Joint Audiovisual Hidden Semi-Markov Model-Based Speech Synthesis. IEEE Journal of Selected Topics in Signal Processing 8, 2 (2014), 336–347. Google ScholarCross Ref
40. JL Schwartz and C Savariaux. 2014. No, there is no 150 ms lead of visual speech on auditory speech, but a range of audiovisual asynchronies varying from small audio lead to large audio lag. PLoS Computational Biology 10, 7 (2014). Google ScholarCross Ref
41. Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research 15 (2014), 1929–1958.Google ScholarDigital Library
42. Robert W. Sumner and Jovan Popovic. 2004. Deformation Transfer for Triangle Meshes. ACM Trans. Graph. 23, 3 (2004), 399–405. Google ScholarDigital Library
43. Sarah Taylor, Akihiro Kato, Ben Milner, and Iain Matthews. 2016. Audio-to-Visual Speech Conversion using Deep Neural Networks. In Proc. Interspeech. 1482–1486.Google ScholarCross Ref
44. Sarah L. Taylor, Moshe Mahler, Barry-John Theobald, and Iain Matthews. 2012. Dynamic Units of Visual Speech. In Proc. SCA. 275–284.Google Scholar
45. Joshua B. Tenenbaum and William T. Freeman. 2000. Separating Style and Content with Bilinear Models. Neural Comput. 12, 6 (2000), 1247–1283. Google ScholarDigital Library
46. Theano Development Team. 2016. Theano: A Python framework for fast computation of mathematical expressions. arXiv:1605.02688 (2016).Google Scholar
47. Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. WaveNet: A Generative Model for Raw Audio. arXiv:1609.03499 (2016).Google Scholar
48. M. Alex O. Vasilescu and Demetri Terzopoulos. 2003. Multilinear Subspace Analysis of Image Ensembles. In Proc. CVPR, Vol. 2. 93–99.Google Scholar
49. Kevin Wampler, Daichi Sasaki, Li Zhang, and Zoran Popovic. 2007. Dynamic, Expressive Speech Animation from a Single Mesh. In Proc. SCA. 53–62.Google Scholar
50. Lijuan Wang and Frank K. Soong. 2015. HMM trajectory-guided sample selection for photo-realistic talking head. Multimedia Tools and Applications 74, 22 (2015), 9849–9869. Google ScholarDigital Library