
“A hardware unit for fast SAH-optimised BVH construction” by Doyle and Fowler
Conference:
Type(s):
Title:
- A hardware unit for fast SAH-optimised BVH construction
Session/Category Title:
- Hardware Rendering
Presenter(s)/Author(s):
Moderator(s):
Abstract:
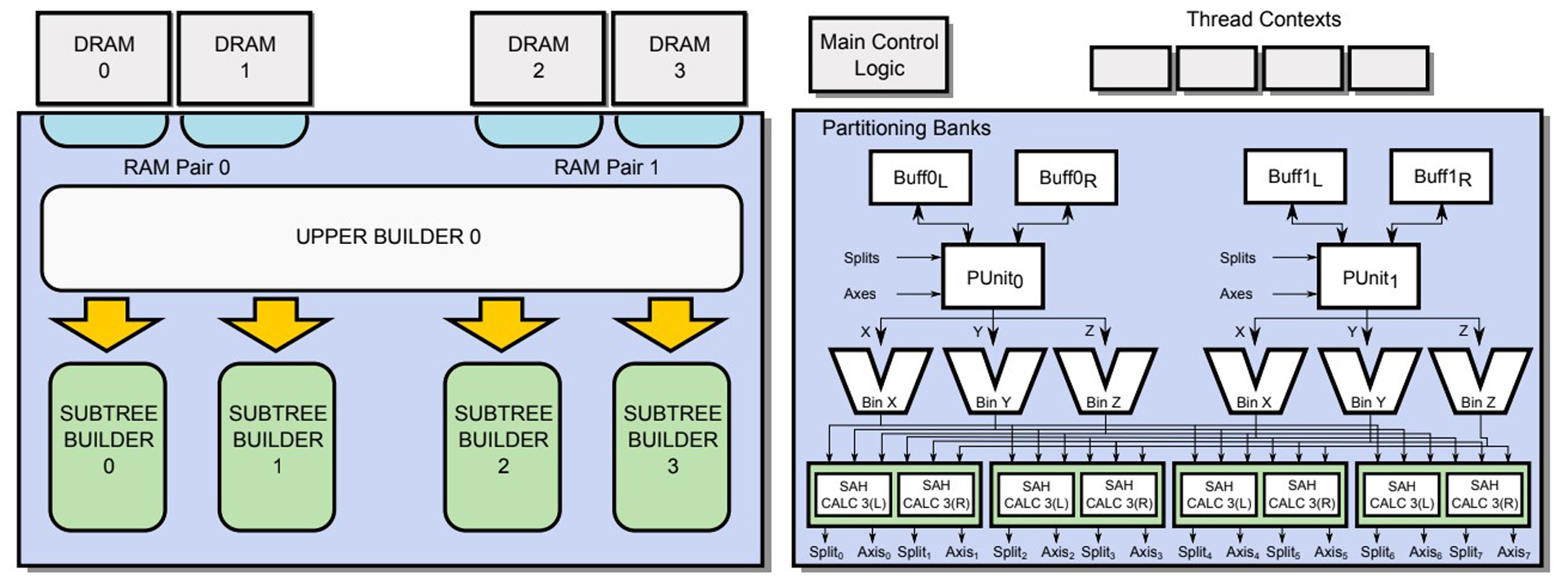
Ray-tracing algorithms are known for producing highly realistic images, but at a significant computational cost. For this reason, a large body of research exists on various techniques for accelerating these costly algorithms. One approach to achieving superior performance which has received comparatively little attention is the design of specialised ray-tracing hardware. The research that does exist on this topic has consistently demonstrated that significant performance and efficiency gains can be achieved with dedicated microarchitectures. However, previous work on hardware ray-tracing has focused almost entirely on the traversal and intersection aspects of the pipeline. As a result, the critical aspect of the management and construction of acceleration data-structures remains largely absent from the hardware literature.We propose that a specialised microarchitecture for this purpose could achieve considerable performance and efficiency improvements over programmable platforms. To this end, we have developed the first dedicated microarchitecture for the construction of binned SAH BVHs. Cycle-accurate simulations show that our design achieves significant improvements in raw performance and in the bandwidth required for construction, as well as large efficiency gains in terms of performance per clock and die area compared to manycore implementations. We conclude that such a design would be useful in the context of a heterogeneous graphics processor, and may help future graphics processor designs to reduce predicted technology-imposed utilisation limits.
References:
1. Caustic Graphics, 2012. Caustic Graphics Company Website. https://caustic.com/. {Online; accessed 15-November-2012}.Google Scholar
2. Chung, E. S., Milder, P. A., Hoe, J. C., and Mai, K. 2010. Single-chip heterogeneous computing: Does the future include custom logic, FPGAs, and GPGPUs? In MICRO-43: Proceedings of the 43th Annual IEEE/ACM International Symposium on Microarchitecture. Google ScholarDigital Library
3. Dally, B. 2009. Power efficient supercomputing (presentation). In Accelerator-based Computing and Manycore Workshop.Google Scholar
4. Dally, B. 2011. Power, programmability, and granularity: The challenges of exascale computing (keynote presentation). In Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE International. Google ScholarDigital Library
5. Doyle, M. J., Fowler, C., and Manzke, M. 2012. Hardware accelerated construction of sah-based bounding volume hierarchies for interactive ray tracing. In Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, I3D ’12, 209–209. Google ScholarDigital Library
6. Ernst, M., 2012. Embree: Photo-realistic ray tracing kernels. http://software.intel.com/en-us/articles/embree-photo-realistic-ray-tracing-kernels. {Online; accessed 29-March-2013}.Google Scholar
7. Esmaeilzadeh, H., Blem, E., St. Amant, R., Sankaralingam, K., and Burger, D. 2011. Dark silicon and the end of multicore scaling. In Proceedings of the 38th annual international symposium on Computer architecture, ISCA ’11, 365–376. Google ScholarDigital Library
8. Fabianowski, B., and Dingliana, J. 2009. Interactive global photon mapping. Computer Graphics Forum 28, 4, 1151–1159. Google ScholarDigital Library
9. Garanzha, K., Pantaleoni, J., and McAllister, D. 2011. Simpler and faster HLBVH with work queues. In Proceedings of the ACM SIGGRAPH Symposium on High Performance Graphics, HPG ’11, 59–64. Google ScholarDigital Library
10. Hall, D. 2001. The AR350: Today’s ray trace rendering processor. In Proceedings of the EUROGRAPHICS/SIGGRAPH Workshop on Graphics Hardware – Hot 3D Session.Google Scholar
11. Johnsson, B., Ganestam, P., Doggett, M., and Akenine-M?ller, T. 2012. Power efficiency for software algorithms running on graphics processors. In Proceedings of the Fourth ACM SIGGRAPH/Eurographics conference on High-Performance Graphics, EGGH-HPG’12, 67–75. Google ScholarDigital Library
12. Karras, T. 2012. Maximizing parallelism in the construction of BVHs, octrees, and k-d trees. In High Performance Graphics, 33–37. Google ScholarDigital Library
13. Kim, H.-Y., Kim, Y.-J., and Kim, L.-S. 2012. MRTP: Mobile ray tracing processor with reconfigurable stream multiprocessors for high datapath utilization. Solid-State Circuits, IEEE Journal of 47, 2 (feb.), 518–535.Google Scholar
14. Kopta, D., Ize, T., Spjut, J., Brunvand, E., Davis, A., and Kensler, A. 2012. Fast, effective BVH updates for animated scenes. In Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, I3D ’12, 197–204. Google ScholarDigital Library
15. Lauterbach, C., Yoon, S.-E., Tuft, D., and Manocha, D. 2006. RT-DEFORM: Interactive ray tracing of dynamic scenes using BVHs. In IEEE Symposium on Interactive Ray Tracing 2006, 39–46.Google ScholarCross Ref
16. Lauterbach, C., Garland, M., Sengupta, S., Luebke, D., and Manocha, D. 2009. Fast BVH construction on GPUs. Comput. Graph. Forum 28, 2, 375–384.Google ScholarCross Ref
17. Lee, W.-J., Lee, S.-H., Nah, J.-H., Kim, J.-W., Shin, Y., Lee, J., and Jung, S.-Y. 2012. SGRT: a scalable mobile GPU architecture based on ray tracing. In ACM SIGGRAPH 2012 Posters, SIGGRAPH ’12, 44:1–44:1. Google ScholarDigital Library
18. Muralimanohar, N., Balasubramonian, R., and Jouppi, N. 2007. Optimizing NUCA organizations and wiring alternatives for large caches with CACTI 6.0. In IEEE/ACM International Symposium on Microarchitecture, 3–14. Google ScholarDigital Library
19. Nah, J.-H., Park, J.-S., Park, C., Kim, J.-W., Jung, Y.-H., Park, W.-C., and Han, T.-D. 2011. T&I engine: traversal and intersection engine for hardware accelerated ray tracing. ACM Trans. Graph. 30, 6 (Dec.), 160:1–160:10. Google ScholarDigital Library
20. NVIDIA. 2010. NVIDIA GeForce GTX 480/470/465 GPU datasheet. NVIDIA Datasheet.Google Scholar
21. Pantaleoni, J., and Luebke, D. 2010. HLBVH: hierarchical LBVH construction for real-time ray tracing of dynamic geometry. In Proceedings of the Conference on High Performance Graphics, HPG ’10, 87–95. Google ScholarDigital Library
22. Parker, S. G., Bigler, J., Dietrich, A., Friedrich, H., Hoberock, J., Luebke, D., McAllister, D., McGuire, M., Morley, K., Robison, A., and Stich, M. 2010. Optix: a general purpose ray tracing engine. ACM Trans. Graph. 29, 4 (July), 66:1–66:13. Google ScholarDigital Library
23. Schmittler, J., Woop, S., Wagner, D., Paul, W. J., and Slusallek, P. 2004. Realtime ray tracing of dynamic scenes on an FPGA chip. In Proceedings of Graphics Hardware, 95–106. Google ScholarDigital Library
24. Sopin, D., Bogolepov, D., and Ulyanov, D. 2011. Real-time SAH BVH construction for ray tracing dynamic scenes. In Proceedings of the 21th International Conference on Computer Graphics and Vision (GraphiCon), 2011.Google Scholar
25. Spjut, J., Kensler, A., Kopta, D., and Brunvand, E. 2009. TRaX: a multicore hardware architecture for real-time ray tracing. Trans. Comp.-Aided Des. Integ. Cir. Sys. 28, 12 (Dec.), 1802–1815. Google ScholarDigital Library
26. Stich, M., Friedrich, H., and Dietrich, A. 2009. Spatial splits in bounding volume hierarchies. In Proceedings of the Conference on High Performance Graphics 2009, HPG ’09, 7–13. Google ScholarDigital Library
27. Venkatesh, G., Sampson, J., Goulding, N., Garcia, S., Bryksin, V., Lugo-Martinez, J., Swanson, S., and Taylor, M. B. 2010. Conservation cores: reducing the energy of mature computations. In Proceedings of the fifteenth edition of ASPLOS on Architectural support for programming languages and operating systems, ASPLOS ’10, 205–218. Google ScholarDigital Library
28. Wald, I. 2007. On fast construction of SAH-based bounding volume hierarchies. In Proceedings of the 2007 IEEE Symposium on Interactive Ray Tracing, 33–40. Google ScholarDigital Library
29. Wald, I. 2012. Fast construction of SAH BVHs on the Intel Many Integrated Core (MIC) architecture. Visualization and Computer Graphics, IEEE Transactions on 18, 1 (jan.), 47–57. Google ScholarDigital Library
30. Wittenbrink, C., Kilgariff, E., and Prabhu, A. 2011. Fermi GF100 GPU architecture. IEEE Micro 31, 5059. Google ScholarDigital Library
31. Woop, S., Schmittler, J., and Slusallek, P. 2005. RPU: a programmable ray processing unit for realtime ray tracing. ACM Trans. Graph. 24, 3 (July), 434–444. Google ScholarDigital Library
32. Woop, S., Marmitt, G., and Slusallek, P. 2006. B-kd trees for hardware accelerated ray tracing of dynamic scenes. In Proceedings of the 21st ACM SIGGRAPH/EUROGRAPHICS symposium on Graphics hardware, 67–77. Google ScholarDigital Library