
“3D human head geometry estimation from a speech” by Maejima and Morishima
Conference:
Type(s):
Title:
- 3D human head geometry estimation from a speech
Presenter(s)/Author(s):
Abstract:
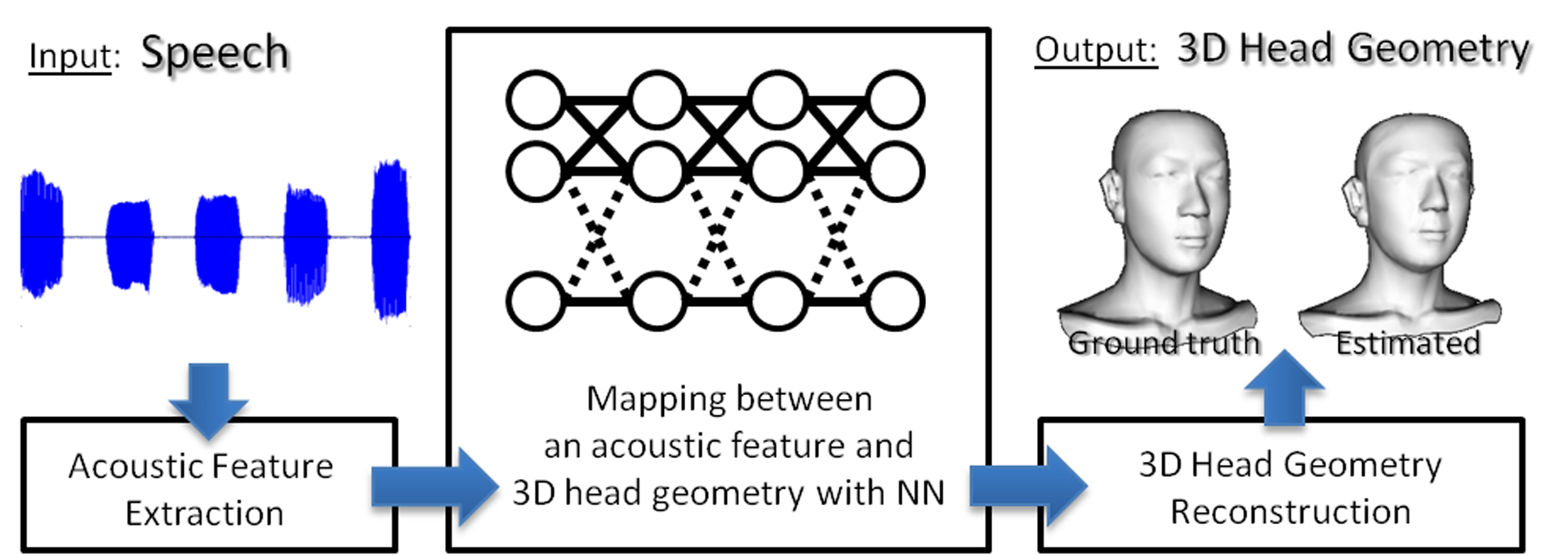
We can visualize acquaintances’ appearance by just hearing their voice if we have met them in past few years. Thus, it would appear that some relationships exist in between voice and appearance. If 3D head geometry could be estimated from a voice, we can realize some applications (e.g, avatar generation, character modeling for video game, etc.). Previously, although many researchers have been reported about a relationship between acoustic features of a voice and its corresponding dynamical visual features including lip, tongue, and jaw movements or vocal articulation during a speech, however, there have been few reports about a relationship between acoustic features and static 3D head geometry. In this paper, we focus on estimating 3D head geometry from a voice. Acoustic features vary depending on a speech context and its intonation. Therefore we restrict a context to Japanese 5 vowels. Under this assumption, to estimate 3D head geometry, we use a Feedforward Neural Network (FNN) trained by using a correspondence between an individual acoustic features extracted from a Japanese vowel and 3D head geometry generated based on a 3D range scan. The performance of our method is shown by both closed and open tests. As a result, we found that 3D head geometry which is acoustically similar to an input voice could be estimated under the limited condition.
References:
1. Amberg, B., Romdhani, S., and Vetter, T. 2007. Optimal step nonrigid icp algorithms for surface registration. In IEEE International Conference on Computer Vision and Pattern Recognition, 1–8.
2. Reynolds, D. A., and Rose, R. C. 1995. Robust text-independent speaker identification using gaussian mixture speaker models. In IEEE Trans. Acoust. Speech and Audio Processing, vol. 3, 72–83.