
“SAGNet: structure-aware generative network for 3D-shape modeling” by Wu, Wang, Lin, Lischinski, Cohen-Or, et al. …
Conference:
Type(s):
Title:
- SAGNet: structure-aware generative network for 3D-shape modeling
Session/Category Title:
- Off the Deep End
Presenter(s)/Author(s):
Abstract:
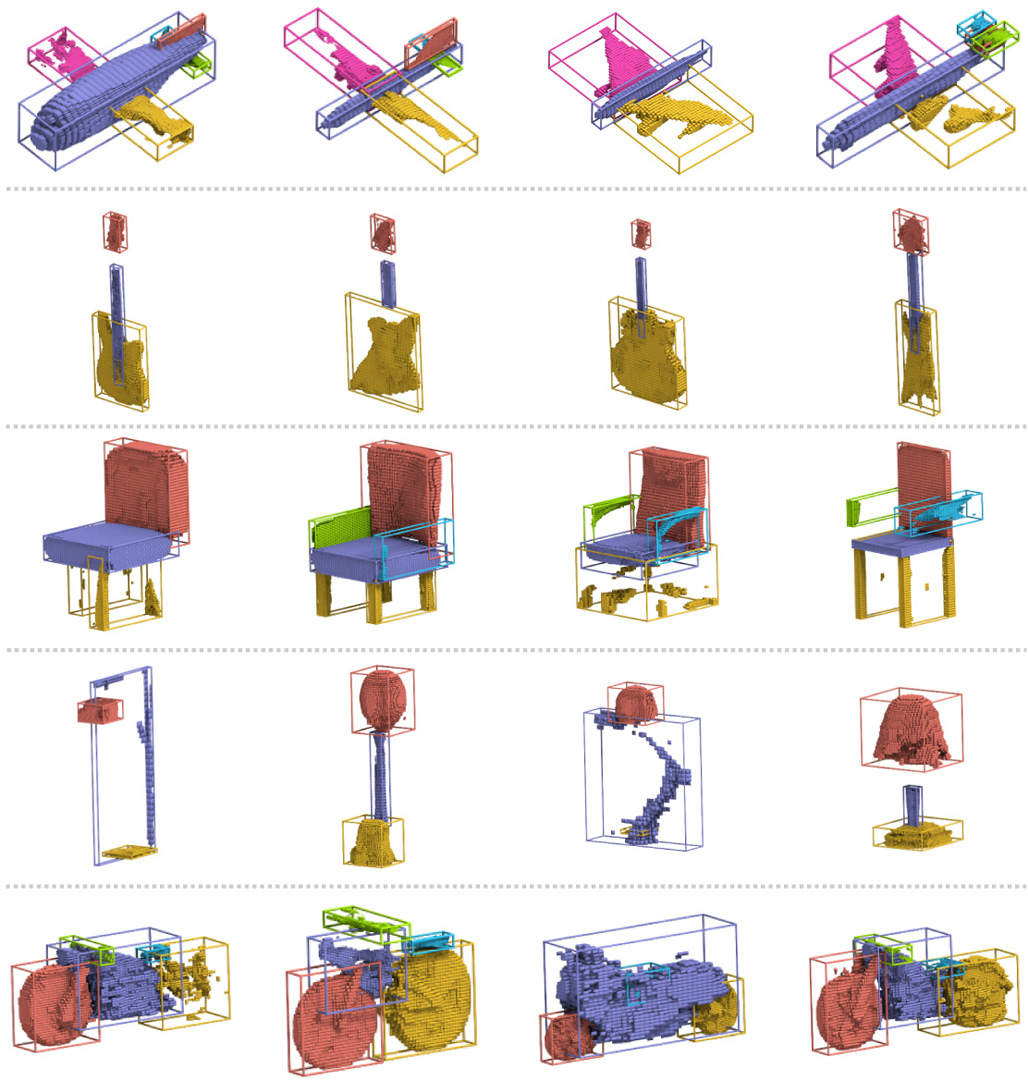
We present SAGNet, a structure-aware generative model for 3D shapes. Given a set of segmented objects of a certain class, the geometry of their parts and the pairwise relationships between them (the structure) are jointly learned and embedded in a latent space by an autoencoder. The encoder intertwines the geometry and structure features into a single latent code, while the decoder disentangles the features and reconstructs the geometry and structure of the 3D model. Our autoencoder consists of two branches, one for the structure and one for the geometry. The key idea is that during the analysis, the two branches exchange information between them, thereby learning the dependencies between structure and geometry and encoding two augmented features, which are then fused into a single latent code. This explicit intertwining of information enables separately controlling the geometry and the structure of the generated models. We evaluate the performance of our method and conduct an ablation study. We explicitly show that encoding of shapes accounts for both similarities in structure and geometry. A variety of quality results generated by SAGNet are presented.
References:
1. Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. 2016. TensorFlow: A System for Large-Scale Machine Learning.. In OSDI, Vol. 16. 265–283. Google ScholarDigital Library
2. Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. 2017. Learning Representations and Generative Models for 3D Point Clouds. arXiv preprint arXiv:1707.02392 (2017).Google Scholar
3. Ibraheem Alhashim, Honghua Li, Kai Xu, Junjie Cao, Rui Ma, and Hao Zhang. 2014. Topology-varying 3D shape creation via structural blending. ACM Trans. on Graphics 33 (2014), 158:1–158:10. Google ScholarDigital Library
4. Samuel R Bowman, Luke Vilnis, Oriol Vinyals, Andrew M Dai, Rafal Jozefowicz, and Samy Bengio. 2016. Generating Sentences from a Continuous Space. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning. 10–21.Google ScholarCross Ref
5. Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. 2014. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. (2014), 103–111.Google Scholar
6. Christopher B Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, and Silvio Savarese. 2016. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In Proc. Euro. Conf. on Computer Vision. 628–644.Google ScholarCross Ref
7. Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014). Google ScholarDigital Library
8. Noa Fish, Melinos Averkiou, Oliver van Kaick, Olga Sorkine-Hornung, Daniel Cohen-Or, and Niloy J. Mitra. 2014. Meta-representation of Shape Families. ACM Trans. on Graphics (Proc. of SIGGRAPH) 33, 4 (2014), 34:1–34:11. Google ScholarDigital Library
9. Rohit Girdhar, David F Fouhey, Mikel Rodriguez, and Abhinav Gupta. 2016. Learning a predictable and generative vector representation for objects. In Proc. Euro. Conf. on Computer Vision. 484–499.Google ScholarCross Ref
10. Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, and Daan Wierstra. 2015. DRAW: A recurrent neural network for image generation. (2015), 1462–1471. Google ScholarDigital Library
11. JunYoung Gwak, Christopher B Choy, Manmohan Chandraker, Animesh Garg, and Silvio Savarese. 2017. Weakly supervised 3d reconstruction with adversarial constraint. In 3D Vision (3DV), 2017 International Conference on. IEEE, 263–272.Google Scholar
12. Haibin Huang, Evangelos Kalogerakis, and Benjamin M. Marlin. 2015. Analysis and synthesis of 3D shape families via deep-learned generative models of surfaces. Computer Graphics Forum 34 (2015), 25–38.Google ScholarCross Ref
13. Zhaoyin Jia, Andrew Gallagher, Ashutosh Saxena, and Tsuhan Chen. 2013. 3D-based reasoning with blocks, support, and stability. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 1–8. Google ScholarDigital Library
14. Andrew Kae, Kihyuk Sohn, Honglak Lee, and Erik Learned-Miller. 2013. Augmenting CRFs with Boltzmann machine shape priors for image labeling. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 2019–2026. Google ScholarDigital Library
15. Diederik P. Kingma and Max Welling. 2014. Auto-Encoding variational bayes. In Proc. Int. Conf. on Learning Representations.Google Scholar
16. Jiaxin Li, Ben M Chen, and Gim Hee Lee. 2018. So-net: Self-organizing network for point cloud analysis. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 9397–9406.Google ScholarCross Ref
17. Jun Li, Kai Xu, Siddhartha Chaudhuri, Ersin Yumer, Hao Zhang, and Leonidas Guibas. 2017. GRASS: Generative Recursive Autoencoders for Shape Structures. ACM Trans. on Graphics (Proc. of SIGGRAPH) 36, 4 (2017), 52:1–52:14. Google ScholarDigital Library
18. Yangyan Li, Hao Su, Charles Ruizhongtai Qi, Noa Fish, Daniel Cohen-Or, and Leonidas J Guibas. 2015. Joint embeddings of shapes and images via CNN image purification. ACM Trans. on Graphics (Proc. of SIGGRAPH Asia) 34, 6 (2015), 234:1–234:12. Google ScholarDigital Library
19. Ming-Yu Liu, Thomas Breuel, and Jan Kautz. 2017. Unsupervised image-to-image translation networks. In Proc. Int. Conf. on Neural Information Processing Systems. 700–708. Google ScholarDigital Library
20. Ming-Yu Liu and Oncel Tuzel. 2016. Coupled generative adversarial networks. In Proc. Int. Conf. on Neural Information Processing Systems. 469–477. Google ScholarDigital Library
21. Niloy J. Mitra, Michael Wand, Hao Zhang, Daniel Cohen-Or, Vladimir Kim, and Qi-Xing Huang. 2014. Structure-aware Shape Processing. In ACM SIGGRAPH Courses. 13:1–13:21. Google ScholarDigital Library
22. Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, Subarna Tripathi, Leonidas J Guibas, and Hao Su. 2018. PartNet: A Large-scale Benchmark for Fine-grained and Hierarchical Part-level 3D Object Understanding. arXiv preprint arXiv:1812.02713 (2018).Google Scholar
23. Charlie Nash and Chris KI Williams. 2017. The shape variational autoencoder: A deep generative model of part-segmented 3D objects. In Computer Graphics Forum, Vol. 36. 1–12. Google ScholarDigital Library
24. Aaron van den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. 2016. Pixel recurrent neural networks. (2016), 1747–1756. Google ScholarDigital Library
25. Danilo Jimenez Rezende, SM Ali Eslami, Shakir Mohamed, Peter Battaglia, Max Jaderberg, and Nicolas Heess. 2016. Unsupervised learning of 3D structure from images. In Proc. Int. Conf. on Neural Information Processing Systems. 4996–5004. Google ScholarDigital Library
26. Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. 2014. Stochastic backpropagation and approximate inference in deep generative models. (2014), 1278–1286. Google ScholarDigital Library
27. Adam Roberts, Jesse Engel, and Douglas Eck. 2017. Hierarchical variational autoencoders for music. (2017).Google Scholar
28. Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016. Improved techniques for training gans. In Proc. Int. Conf. on Neural Information Processing Systems. 2234–2242. Google ScholarDigital Library
29. Nadav Schor, Oren Katzir, Hao Zhang, and Daniel Cohen-Or. 2018. Learning to Generate the” Unseen” via Part Synthesis and Composition. arXiv preprint arXiv:1811.07441 (2018).Google Scholar
30. Xiaoyu Shen, Hui Su, Shuzi Niu, and Vera Demberg. 2018. Improving Variational Encoder-Decoders in Dialogue Generation. (2018).Google Scholar
31. Ayan Sinha, Asim Unmesh, Qi-Xing Huang, and Karthik Ramani. 2017. SurfNet: Generating 3D Shape Surfaces Using Deep Residual Networks. Proc. IEEE Conf. on Computer Vision & Pattern Recognition (2017), 791–800.Google ScholarCross Ref
32. Richard Socher, Brody Huval, Bharath Bath, Christopher D Manning, and Andrew Y Ng. 2012. Convolutional-recursive deep learning for 3D object classification. In Proc. Int. Conf. on Neural Information Processing Systems. 656–664. Google ScholarDigital Library
33. Richard Socher, Cliff C Lin, Chris Manning, and Andrew Y Ng. 2011. Parsing natural scenes and natural language with recursive neural networks. In Proc. Int. Conf. on Machine Learning. 129–136. Google ScholarDigital Library
34. Maxim Tatarchenko, Alexey Dosovitskiy, and Thomas Brox. 2017. Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs. Proc. Int. Conf. on Computer Vision (2017), 2107–2115.Google ScholarCross Ref
35. Shubham Tulsiani, Hao Su, Leonidas J. Guibas, Alexei A. Efros, and Jitendra Malik. 2017. Learning Shape Abstractions by Assembling Volumetric Primitives. Proc. IEEE Conf. on Computer Vision & Pattern Recognition (2017), 1466–1474.Google ScholarCross Ref
36. Hao Wang, Nadav Schor, Ruizhen Hu, Haibin Huang, Daniel Cohen-Or, and Hui Huang. 2018. Global-to-Local Generative Model for 3D Shapes. ACM Trans. on Graphics (Proc. of SIGGRAPH Asia) 37, 6 (2018), 214:1–214:10. Google ScholarDigital Library
37. Jiajun Wu, Chengkai Zhang, Tianfan Xue, Bill Freeman, and Josh Tenenbaum. 2016. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In Proc. Int. Conf. on Neural Information Processing Systems. 82–90. Google ScholarDigital Library
38. Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 2015. 3D shapenets: A deep representation for volumetric shapes. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 1912–1920.Google Scholar
39. Danfei Xu, Yuke Zhu, Christopher B Choy, and Li Fei-Fei. 2017. Scene graph generation by iterative message passing. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition, Vol. 2. 3097–3106.Google ScholarCross Ref
40. Xinchen Yan, Jimei Yang, Ersin Yumer, Yijie Guo, and Honglak Lee. 2016. Perspective transformer nets: Learning single-view 3D object reconstruction without 3d supervision. In Proc. Int. Conf. on Neural Information Processing Systems. 1696–1704. Google ScholarDigital Library
41. Yaoqing Yang, Cheng Feng, Yiru Shen, and Dong Tian. 2018. FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 206–215.Google ScholarCross Ref
42. Li Yi, Vladimir G Kim, Duygu Ceylan, I Shen, Mengyan Yan, Hao Su, Cewu Lu, Qixing Huang, Alla Sheffer, Leonidas Guibas, et al. 2016. A scalable active framework for region annotation in 3D shape collections. ACM Trans. on Graphics (Proc. of SIGGRAPH Asia) 35, 6 (2016), 210:1–210:12. Google ScholarDigital Library
43. Bo Zheng, Yibiao Zhao, Joey Yu, Katsushi Ikeuchi, and Song-Chun Zhu. 2015. Scene understanding by reasoning stability and safety. Int. J. Computer Vision 112, 2 (2015), 221–238. Google ScholarDigital Library
44. Chuhang Zou, Ersin Yumer, Jimei Yang, Duygu Ceylan, and Derek Hoiem. 2017. 3D-PRNN: Generating shape primitives with recurrent neural networks. In Proc. Int. Conf. on Computer Vision. 900–909.Google ScholarCross Ref