
“Volume: 3D Reconstruction of History for Immersive Platforms” by Fleisher and Anlen


Conference:
Type(s):
Entry Number: 54
Title:
- Volume: 3D Reconstruction of History for Immersive Platforms
Presenter(s)/Author(s):
Abstract:
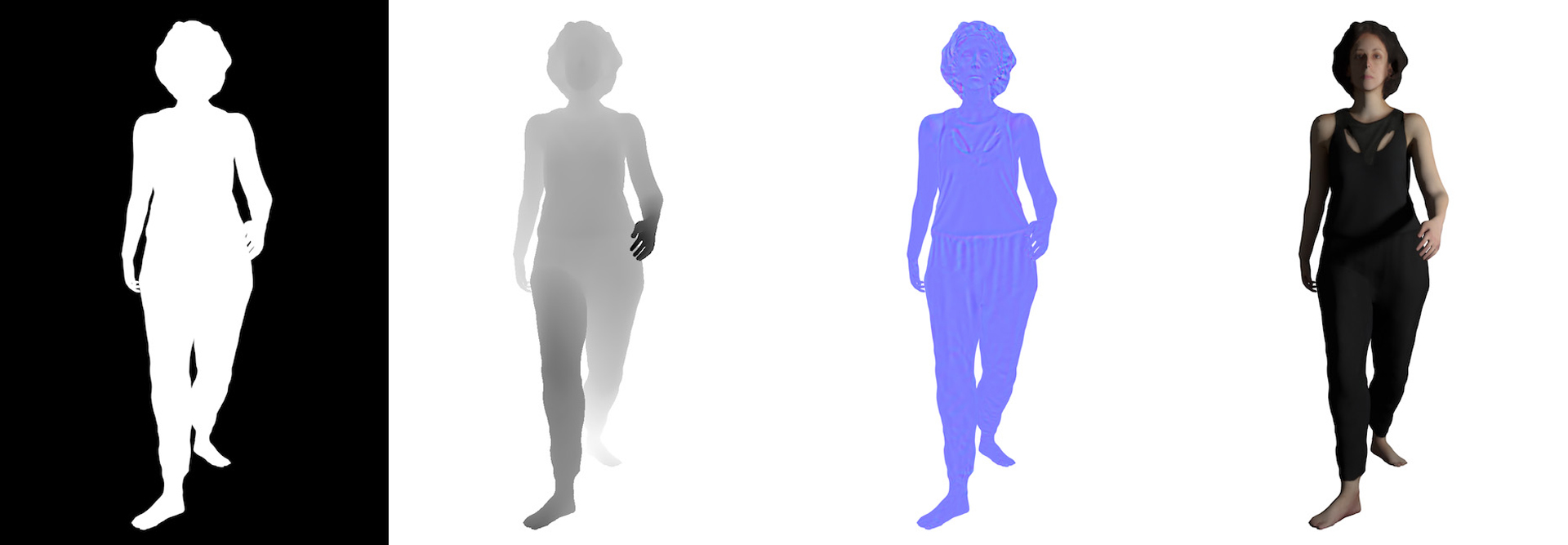
This paper presents Volume, a software toolkit that enables users to experiment with expressive reconstructions of archival and/or historical materials as volumetric renderings. Making use of contemporary deep learning methods, Volume re-imagines 2D images as volumetric 3D assets. These assets can then be incorporated into virtual, augmented and mixed reality experiences.
References:
- T. Chen, Z. Zhu, A. Shamir, S.-M. Hu, and D. Cohen-Or. 2013. 3-sweep: Extracting editable objects from a single photo. ACM Transactions on Graphics (TOG) 32, 6 (2013), 195:1–195:10.
- D. Eigen and R. Fergus. 2015. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2650–2658.
- O. Fleisher and s. anlen. 2018a. Inside Pulp Fiction. http://goo.gl/iPV4jy
- O. Fleisher and s. anlen. 2018b. Volume Website. https://volume.gl
- K. He, G. Gkioxari, P. Dollár, and R. Girshick. 2017. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2980–2988.
- L. Laina, C. Rupprecht, V. Belagiannis, F. Tombari, and N. Navab. 2016. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the IEEE International Conference on 3D Vision (3DV). 239–248.
- L. Patil, Y. Arora, and T. Nguyen. 2016. Fully Convolutional Network for Depth Estimation and Semantic Segmentation. https://github.com/iapatil/ depth-semantic-fully-conv
- Simile, Inc. 2017. DepthKit. http://www.depthkit.tv.
Keyword(s):
Acknowledgements:
This research was mentored by Ken Perlin, Professor of Computer Science and Head of the Future Reality Lab at New York University. We would like to thank Angus Forbes, Assistant Professor in the Computational Media Department at University of California, Santa Cruz, for help in editing this research.