
“Unsupervised Learning of Visual Representations by Solving Shuffled Long Video-Frames Temporal Order Prediction” by Siar, Gheibi and Mohades


Conference:
Type(s):
Entry Number: 52
Title:
- Unsupervised Learning of Visual Representations by Solving Shuffled Long Video-Frames Temporal Order Prediction
Presenter(s)/Author(s):
Abstract:
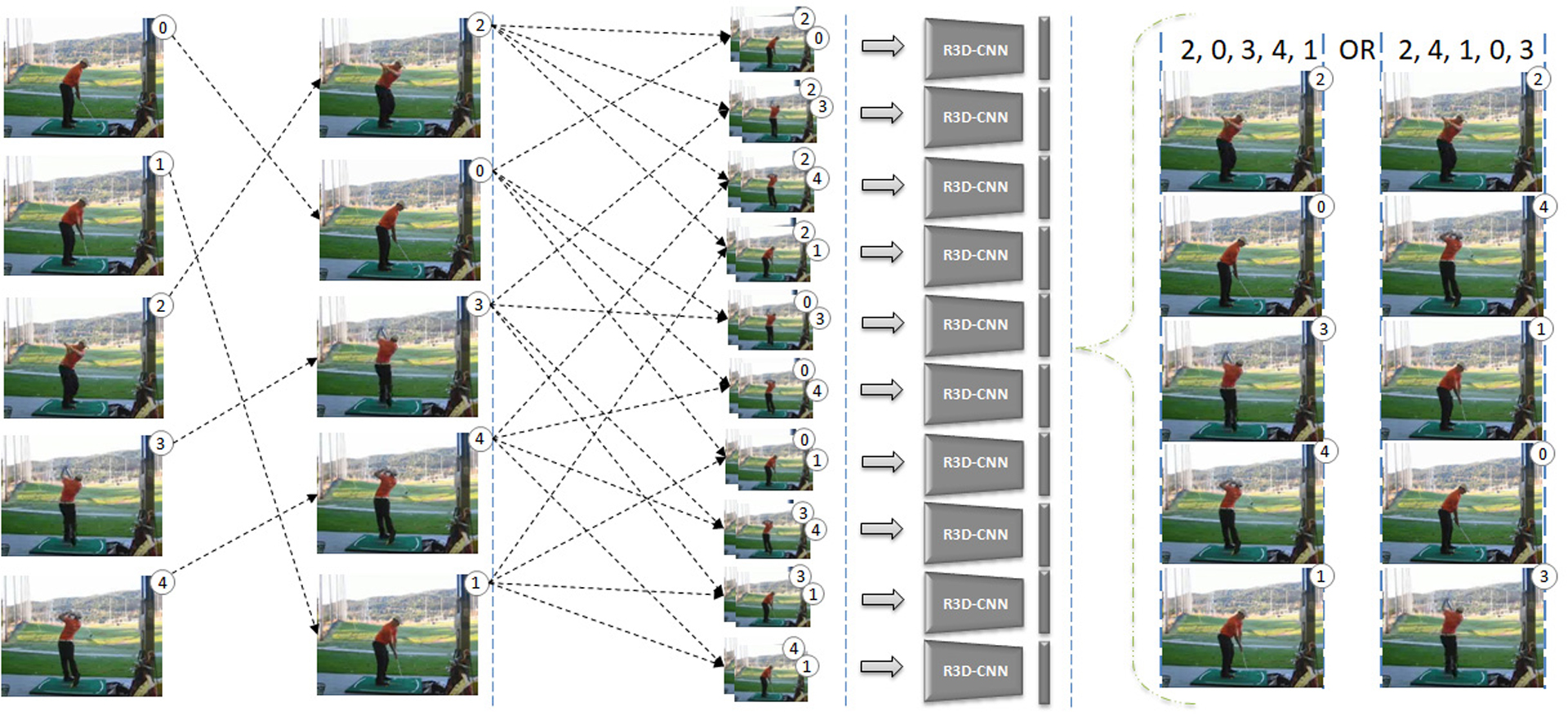
There is lots of hidden information behind the sequential data and their sequences. We proposed a model for learning visual representation by solving order prediction task. We concatenated the frame pairs, instead of concatenating the feature pairs. This concatenation makes it possible to apply a 3D-CNN to extract features from the frame pairs. Also, we proposed a new grouping, which have achieved 80 percent accuracy on average. We have modified the shuffled video clips order prediction task to the shuffled frame order prediction, by selecting a frame from each clip, by random. Then this task was solved by applying our model.