“TEXTure: Text-Guided Texturing of 3D Shapes” by Richardson, Metzer, Alaluf, Giryes and Cohen-Or
Conference:
Type(s):
Title:
- TEXTure: Text-Guided Texturing of 3D Shapes
Session/Category Title: Text-Guided Generation
Presenter(s)/Author(s):
Moderator(s):
Abstract:
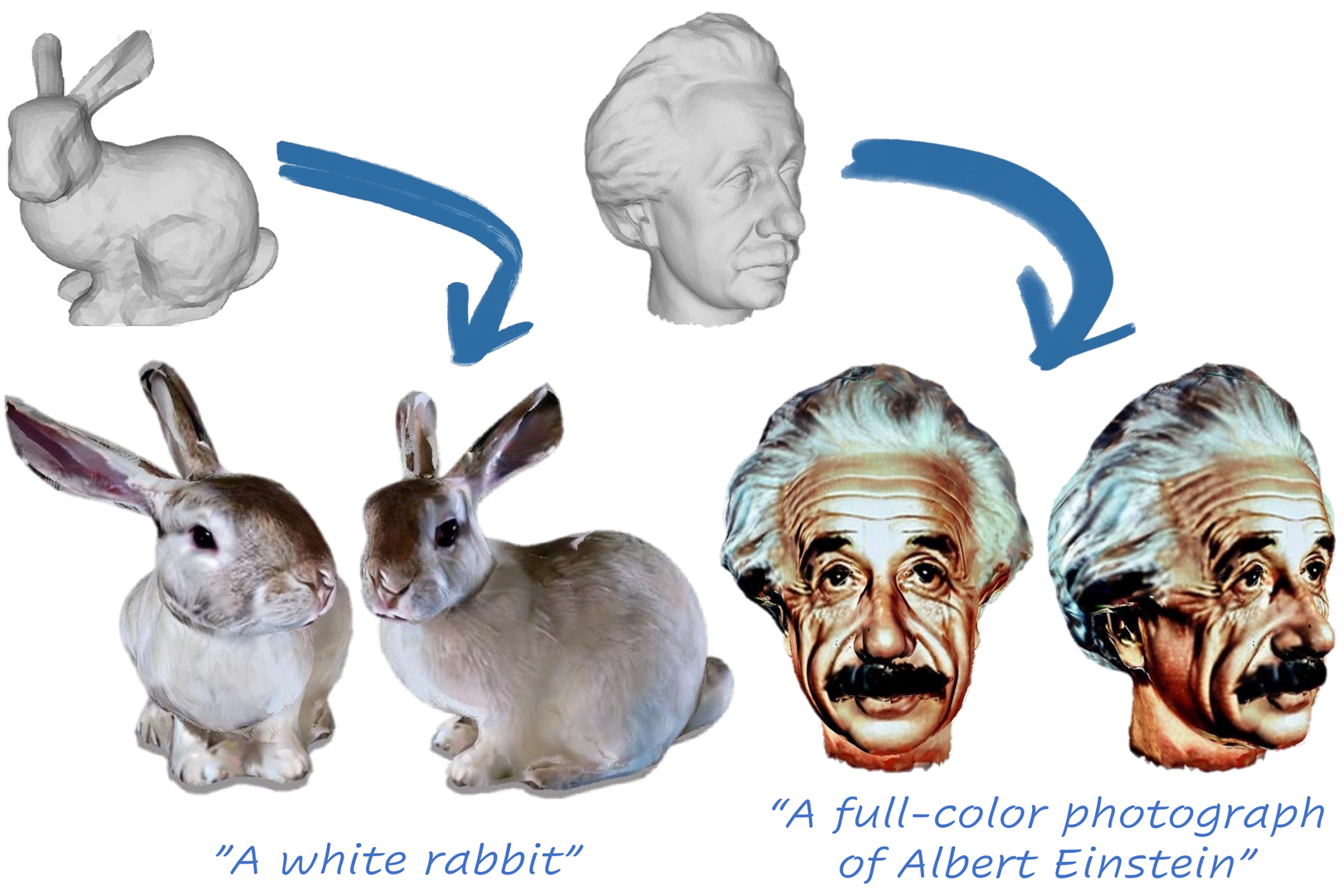
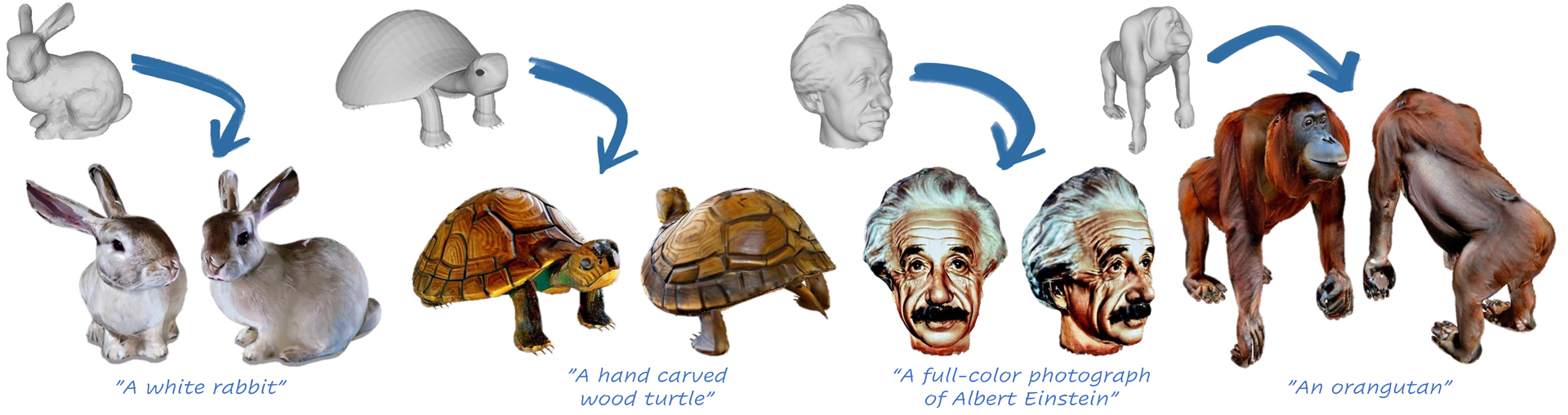
In this paper, we present TEXTure, a novel method for text-guided generation, editing, and transfer of textures for 3D shapes. Leveraging a pretrained depth-to-image diffusion model, TEXTure applies an iterative scheme that paints a 3D model from different viewpoints. Yet, while depth-to-image models can create plausible textures from a single viewpoint, the stochastic nature of the generation process can cause many inconsistencies when texturing an entire 3D object. To tackle these problems, we dynamically define a trimap partitioning of the rendered image into three progression states, and present a novel elaborated diffusion sampling process that uses this trimap representation to generate seamless textures from different views. We then show that one can transfer the generated texture maps to new 3D geometries without requiring explicit surface-to-surface mapping, as well as extract semantic textures from a set of images without requiring any explicit reconstruction. Finally, we show that TEXTure can be used to not only generate new textures but also edit and refine existing textures using either a text prompt or user-provided scribbles. We demonstrate that our TEXTuring method excels at generating, transferring, and editing textures through extensive evaluation, and further close the gap between 2D image generation and 3D texturing. Code is available via our project page: https://texturepaper.github.io/TEXTurePaper/.
References:
1. 2012. Three D Scans. https://threedscans.com/.
2. 2022. The Stanford 3D Scanning Repository. http://graphics.stanford.edu/data/3Dscanrep/.
3. Omri Avrahami, Ohad Fried, and Dani Lischinski. 2022a. Blended Latent Diffusion. arXiv preprint arXiv:2206.02779 (2022).
4. Omri Avrahami, Ohad Fried, and Dani Lischinski. 2022b. Blended Latent Diffusion. arXiv preprint arXiv:2206.02779 (2022).
5. behnam.aftab. 2021. Free 3D Turtle Model. https://3dexport.com/free-3dmodel-free-3d-turtle-model-355284.htm. Item ID: 355284.
6. Sema Berkiten, Maciej Halber, Justin Solomon, Chongyang Ma, Hao Li, and Szymon Rusinkiewicz. 2017. Learning detail transfer based on geometric features. In Computer Graphics Forum, Vol. 36. Wiley Online Library, 361–373.
7. Toby P Breckon and Robert B Fisher. 2012. A hierarchical extension to 3D non-parametric surface relief completion. Pattern Recognition 45, 1 (2012), 172–185.
8. RAMIRO CASTRO. 2020. Elephant Natural History Museum. https://www.cgtrader.com/free-3d-print-models/miniatures/other/elephant-natural-history-museum-1. Model ID: 2773650.
9. Xiaobai Chen, Tom Funkhouser, Dan B Goldman, and Eli Shechtman. 2012. Non-parametric texture transfer using meshmatch. Technical Report Technical Report 2012-2 (2012).
10. Yongwei Chen, Rui Chen, Jiabao Lei, Yabin Zhang, and Kui Jia. 2022. TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition. arXiv preprint arXiv:2210.11277 (2022).
11. Keenan Crane. 2022. Keenan’s 3D Model Repository. https://www.cs.cmu.edu/ kmcrane/Projects/ModelRepository/.
12. Jeremy S De Bonet. 1997. Multiresolution sampling procedure for analysis and synthesis of texture images. In Proceedings of the 24th annual conference on Computer graphics and interactive techniques. 361–368.
13. Alexei A Efros and Thomas K Leung. 1999. Texture synthesis by non-parametric sampling. In Proceedings of the seventh IEEE international conference on computer vision, Vol. 2. IEEE, 1033–1038.
14. Anna Frühstück, Ibraheem Alhashim, and Peter Wonka. 2019. TileGAN: Synthesis of Large-Scale Non-Homogeneous Textures. ACM Trans. Graph. 38 (2019), 58:1–58:11.
15. Clement Fuji Tsang, Maria Shugrina, Jean Francois Lafleche, Towaki Takikawa, Jiehan Wang, Charles Loop, Wenzheng Chen, Krishna Murthy Jatavallabhula, Edward Smith, Artem Rozantsev, Or Perel, Tianchang Shen, Jun Gao, Sanja Fidler, Gavriel State, Jason Gorski, Tommy Xiang, Jianing Li, Michael Li, and Rev Lebaredian. 2022. Kaolin: A Pytorch Library for Accelerating 3D Deep Learning Research. https://github.com/NVIDIAGameWorks/kaolin.
16. Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2022. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618 (2022).
17. Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. 2022. GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images. arXiv preprint arXiv:2209.11163 (2022).
18. Aleksey Golovinskiy, Wojciech Matusik, Hanspeter Pfister, Szymon Rusinkiewicz, and Thomas Funkhouser. 2006. A statistical model for synthesis of detailed facial geometry. ACM Transactions on Graphics (TOG) 25, 3 (2006), 1025–1034.
19. David J Heeger and James R Bergen. 1995. Pyramid-based texture analysis/synthesis. In Proceedings of the 22nd annual conference on Computer graphics and interactive techniques. 229–238.
20. Amir Hertz, Rana Hanocka, Raja Giryes, and Daniel Cohen-Or. 2020. Deep Geometric Texture Synthesis. ACM Trans. Graph. 39, 4, Article 108 (2020). https://doi.org/10.1145/3386569.3392471
21. Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022).
22. Dong Huk Park, Grace Luo, Clayton Toste, Samaneh Azadi, Xihui Liu, Maka Karalashvili, Anna Rohrbach, and Trevor Darrell. 2022. Shape-Guided Diffusion with Inside-Outside Attention. arXiv e-prints (2022), arXiv–2212.
23. Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. 2022. Imagic: Text-based real image editing with diffusion models. arXiv preprint arXiv:2210.09276 (2022).
24. Kentung3D. 2022. Pikachu 3D Sculpt Free Free 3D model. https://www.cgtrader.com/free-3d-models/character/child/pikachu-3d-model-free.
25. Nasir Mohammad Khalid, Tianhao Xie, Eugene Belilovsky, and Popa Tiberiu. 2022. CLIP-Mesh: Generating textured meshes from text using pretrained image-text models. SIGGRAPH Asia 2022 Conference Papers (2022).
26. Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2022. Magic3D: High-Resolution Text-to-3D Content Creation. arXiv preprint arXiv:2211.10440 (2022).
27. Jianye Lu, Athinodoros S Georghiades, Andreas Glaser, Hongzhi Wu, Li-Yi Wei, Baining Guo, Julie Dorsey, and Holly Rushmeier. 2007. Context-aware textures. ACM Transactions on Graphics (TOG) 26, 1 (2007), 3–es.
28. Tom Mertens, Jan Kautz, Jiawen Chen, Philippe Bekaert, and Frédo Durand. 2006. Texture Transfer Using Geometry Correlation.Rendering Techniques 273, 10.2312 (2006), 273–284.
29. Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. 2022. Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures. arXiv preprint arXiv:2211.07600 (2022).
30. Mark Meyer, Mathieu Desbrun, Peter Schröder, and Alan H Barr. 2003. Discrete differential-geometry operators for triangulated 2-manifolds. In Visualization and mathematics III. Springer, 35–57.
31. Oscar Michel, Roi Bar-On, Richard Liu, Sagie Benaim, and Rana Hanocka. 2022. Text2mesh: Text-driven neural stylization for meshes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13492–13502.
32. Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021).
33. paffin. 2019. Teddy bear Free 3D model. https://www.cgtrader.com/free-3d-models/animals/other/teddy-bear-715514f6-a1ab-4aae-98d0-80b5f55902bd. Model ID: 2034275.
34. Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. 2022. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022).
35. Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar R Zaiane, and Martin Jagersand. 2020. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern recognition 106 (2020), 107404.
36. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning. PMLR, 8748–8763.
37. Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022).
38. René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. 2021. Vision Transformers for Dense Prediction. ICCV (2021).
39. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models., 10684–10695 pages.
40. Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2022. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. arXiv preprint arXiv:2208.12242 (2022).
41. Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. 2022. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. https://doi.org/10.48550/ARXIV.2205.11487
42. Laura Salas. 2016. Klein Bottle 2. https://sketchfab.com/3d-models/klein-bottle-2-eecfee26bbe54bfc9cb8e1904f33c0b7.
43. savagerus. 2019. Orangutan Free 3D model. https://www.cgtrader.com/free-3d-models/animals/mammal/orangutan-fe49896d-8c60-46d8-9ecb-36afa9af49f6. Model ID: 2142893.
44. Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, 2022. Laion-5b: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402 (2022).
45. Matan Sela, Yonathan Aflalo, and Ron Kimmel. 2015. Computational caricaturization of surfaces. Computer Vision and Image Understanding 141 (2015), 1–17.
46. Omry Sendik and Daniel Cohen-Or. 2017. Deep Correlations for Texture Synthesis. ACM Transactions on Graphics (TOG) 36 (2017), 1 – 15.
47. Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. 2021. Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis. In Advances in Neural Information Processing Systems (NeurIPS).
48. Yizhi Song, Zhifei Zhang, Zhe Lin, Scott Cohen, Brian Price, Jianming Zhang, Soo Ye Kim, and Daniel Aliaga. 2022. ObjectStitch: Generative Object Compositing. arXiv preprint arXiv:2212.00932 (2022).
49. Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. 2022. Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation. arXiv preprint arXiv:2211.12572 (2022).
50. Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 2015. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1912–1920.
51. Wenqi Xian, Patsorn Sangkloy, Jingwan Lu, Chen Fang, Fisher Yu, and James Hays. 2017. TextureGAN: Controlling Deep Image Synthesis with Texture Patches. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (2017), 8456–8465.
52. Jiale Xu, Xintao Wang, Weihao Cheng, Yan-Pei Cao, Ying Shan, Xiaohu Qie, and Shenghua Gao. 2022. Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models. arXiv preprint arXiv:2212.14704 (2022).
53. Jonathan Young. 2022. XAtlas: Mesh parameterization / UV unwrapping library. https://github.com/jpcy/xatlas.
54. Yang Zhou, Zhen Zhu, Xiang Bai, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. 2018. Non-stationary texture synthesis by adversarial expansion. arXiv preprint arXiv:1805.04487 (2018).
55. Song Chun Zhu, Yingnian Wu, and David Mumford. 1998. Filters, random fields and maximum entropy (FRAME): Towards a unified theory for texture modeling. International Journal of Computer Vision 27, 2 (1998), 107–126.
Additional Images: