
“RSGAN: Face Swapping and Editing using Face and Hair Representation in Latent Spaces” by Natsume, Yatagawa and Morishima

Conference:
Type(s):
Entry Number: 69
Title:
- RSGAN: Face Swapping and Editing using Face and Hair Representation in Latent Spaces
Presenter(s)/Author(s):
Abstract:
INTRODUCTION
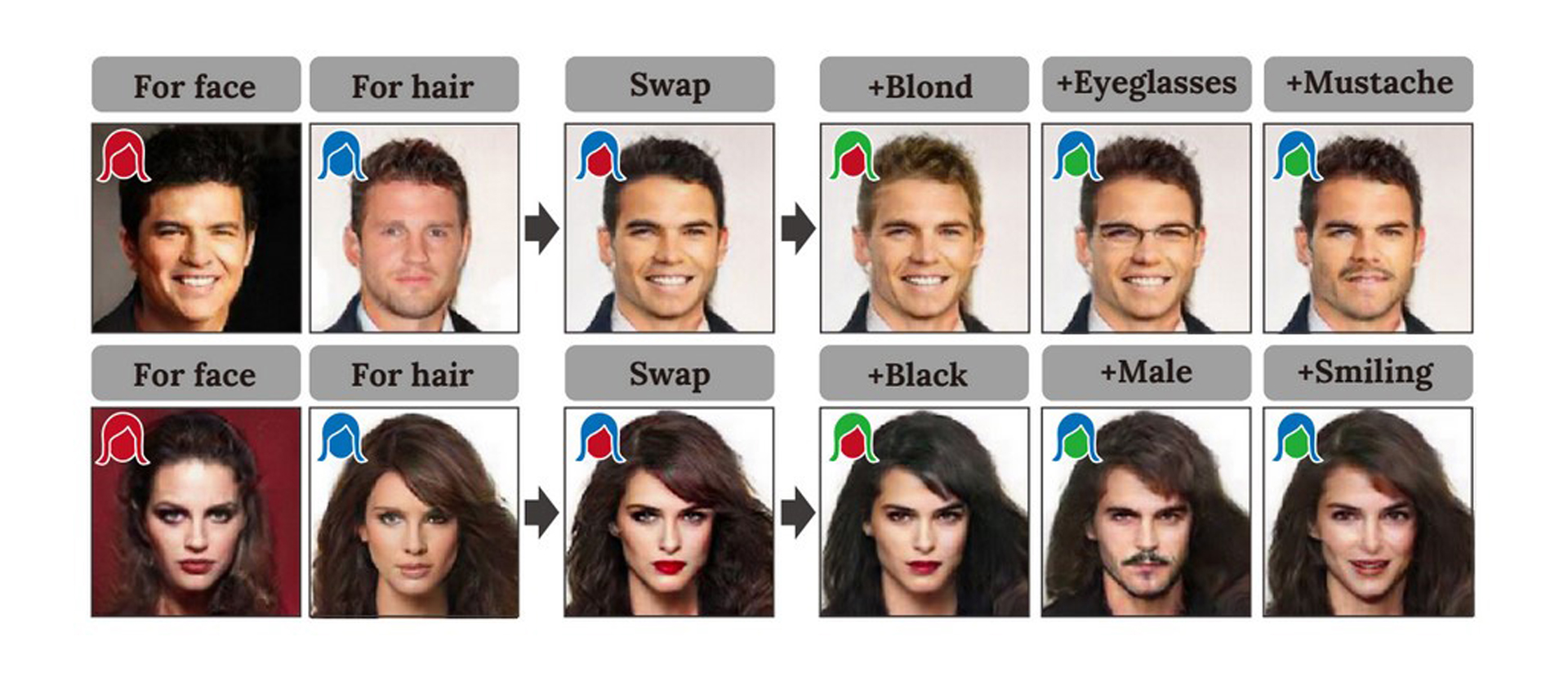
This abstract introduces a generative neural network for face swapping and editing face images. We refer to this network as “regionseparative generative adversarial network (RSGAN)”. In existing deep generative models such as Variational autoencoder (VAE) and Generative adversarial network (GAN), training data must represent what the generative models synthesize. For example, image inpainting is achieved by training images with and without holes. However, it is difficult or even impossible to prepare a dataset which includes face images both before and after face swapping because faces of real people cannot be swapped without surgical operations. We tackle this problem by training the network so that it synthesizes synthesize a natural face image from an arbitrary pair of face and hair appearances. In addition to face swapping, the proposed network can be applied to other editing applications, such as visual attribute editing and random face parts synthesis.
References:
- Ira Kemelmacher-Shlizerman. 2016. Transguring portraits. TOG 35, 4 (2016), 94:1–94:8. https://doi.org/10.1145/2897824.2925871
- Anat Levin, Assaf Zomet, Shmuel Peleg, and Yair Weiss. 2004. Seamless image stitching in the gradient domain. In Proc. of European Conference on Computer Vision (ECCV). 377–389. https://doi.org/10.1007/978-3-540-24673-2_31
- Yuval Nirkin, Iacopo Masi, Anh Tuan Tran, Tal Hassner, and Gérard Medioni. 2018. On Face Segmentation, Face Swapping, and Face Perception. In Proc. of IEEE Conference on Automatic Face and Gesture Recognition.
Keyword(s):
Acknowledgements:
This study was granted in part by the Strategic Basic Research Program ACCEL of the Japan Science and Technology Agency (JPMJAC1602). Tatsuya Yatagawa was supported by a Research Fellowship for Young Researchers of Japan’s Society for the Promotion of Science (16J02280). Shigeo Morishima was supported by a Grantin-Aid from Waseda Institute of Advanced Science and Engineering. The authors would like to acknowledge NVIDIA Corporation for providing their GPUs in the academic GPU Grant Program.