
“Organizing heterogeneous scene collections through contextual focal points” by Xu, Ma, Zhu, Shamir, Cohen-Or, et al. …
Conference:
Type(s):
Title:
- Organizing heterogeneous scene collections through contextual focal points
Session/Category Title: Shape Collection
Presenter(s)/Author(s):
Moderator(s):
Abstract:
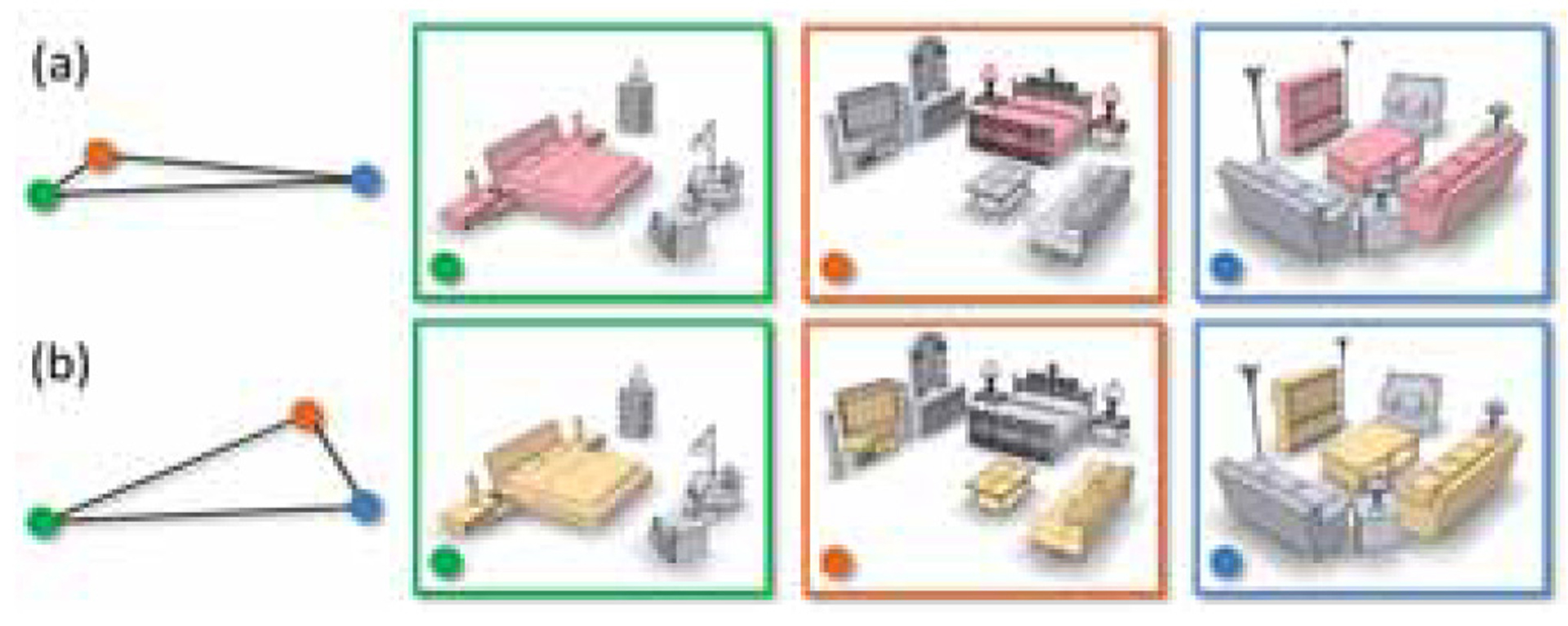
We introduce focal points for characterizing, comparing, and organizing collections of complex and heterogeneous data and apply the concepts and algorithms developed to collections of 3D indoor scenes. We represent each scene by a graph of its constituent objects and define focal points as representative substructures in a scene collection. To organize a heterogeneous scene collection, we cluster the scenes based on a set of extracted focal points: scenes in a cluster are closely connected when viewed from the perspective of the representative focal points of that cluster. The key concept of representativity requires that the focal points occur frequently in the cluster and that they result in a compact cluster. Hence, the problem of focal point extraction is intermixed with the problem of clustering groups of scenes based on their representative focal points. We present a co-analysis algorithm which interleaves frequent pattern mining and subspace clustering to extract a set of contextual focal points which guide the clustering of the scene collection. We demonstrate advantages of focal-centric scene comparison and organization over existing approaches, particularly in dealing with hybrid scenes, scenes consisting of elements which suggest membership in different semantic categories.
References:
1. Biberman, Y. 1994. A context similarity measure. Machine Learning 784, 49–63. Google ScholarDigital Library
2. Cheng, M.-M., Mitra, N. J., Huang, X., and Hu, S.-M. 2014. SalientShape: group saliency in image collections. The Visual Computer 30, 4, 443–453. Google ScholarDigital Library
3. Doersch, C., Singh, S., Gupta, A., Sivic, J., and Efros, A. A. 2012. What makes paris look like Paris? ACM Trans. on Graph (Proc. of SIGGRAPH) 31, 4, 101: 1–9. Google ScholarDigital Library
4. Fisher, M., and Hanrahan, P. 2010. Context-based search for 3D models. ACM Trans. on Graph (Proc. of SIGGRAPH Asia) 29, 6, 182: 1–10. Google ScholarDigital Library
5. Fisher, M., Savva, M., and Hanrahan, P. 2011. Characterizing structural relationships in scenes using graph kernels. ACM Trans. on Graph (Proc. of SIGGRAPH) 30, 4, 34: 1–11. Google ScholarDigital Library
6. Fisher, M., Ritchie, D., Savva, M., Funkhouser, T., and Hanrahan, P. 2012. Example-based synthesis of 3D object arrangements. ACM Trans. on Graph 31, 6, 135: 1–11. Google ScholarDigital Library
7. Han, J., Cheng, H., Xin, D., and Yan, X. 2007. Frequent pattern mining: current status and future directions. Data Mining and Knowledge Discovery 15, 1, 55–86. Google ScholarDigital Library
8. Huang, Q., Zhang, G., Gao, L., Hu, S., Bustcher, A., and Guibas, L. 2012. An optimization approach for extracting and encoding consistent maps in a shape collection. ACM Trans. on Graph (Proc. of SIGGRAPH Asia) 31, 6, 167: 1–11. Google ScholarDigital Library
9. Huang, Q., Su, H., and Guibas, L. 2013. Fine-grained semi-supervised labeling of large shape collections. ACM Trans. on Graph (Proc. of SIGGRAPH Asia) 32, 6, 190: 1–10. Google ScholarDigital Library
10. Huang, S.-S., Shamir, A., Shen, C.-H., Zhang, H., Sheffer, A., Hu, S.-M., and Cohen-Or, D. 2013. Qualitative organization of collections of shapes via quartet analysis. ACM Trans. on Graph (Proc. of SIGGRAPH) 32, 4, 71: 1–10. Google ScholarDigital Library
11. Jain, A., Thormählen, T., Ritschel, T., and Seidel, H.-P. 2012. Exploring shape variations by 3D-model decomposition and part-based recombination. Computer Graphics Forum (Special Issue of Eurographics) 31, 2, 631–640. Google ScholarDigital Library
12. Jeh, G., and Widom, J. 2002. SimRank: a measure of structural-context similarity. In Proc. of ACM SIGKDD, 538–543. Google ScholarDigital Library
13. Juneja, M., Vedaldi, A., Jawahar, C. V., and Zisserman, A. 2013. Blocks that shout: Distinctive parts for scene classification. In Proc. IEEE Conf. on Comp. Vis. and Pat. Rec., 923–930. Google ScholarDigital Library
14. Kim, V. G., Li, W., Mitra, N., DiVerdi, S., and Funkhouser, T. 2012. Exploring collections of 3D models using fuzzy correspondences. ACM Trans. on Graph (Proc. of SIGGRAPH) 31, 54: 1–11. Google ScholarDigital Library
15. Ovsjanikov, M., Li, W., Guibas, L., and Mitra, N. J. 2011. Exploration of continuous variability in collections of 3D shapes. ACM Trans. on Graph (Proc. of SIGGRAPH) 30, 4, 33: 1–10. Google ScholarDigital Library
16. Quattoni, A., and Torralba, A. 2009. Recognizing indoor scenes. In Proc. IEEE Conf. on Comp. Vis. and Pat. Rec., 413–420.Google Scholar
17. Rasiwasia, N., and Vasconcelos, N. 2008. Scene classification with low-dimensional semantic spaces and weak supervision. In Proc. IEEE Conf. on Comp. Vis. and Pat. Rec., 1–6.Google Scholar
18. Riesen, K., Jiang, X., and Bunke, H. 2010. Exact and inexact graph matching: Methodology and applications. Managing and Mining Graph Data 40, 217–247.Google Scholar
19. Rosch, E. 1975. Cognitive reference points. Cognitive Psychology 7, 4, 532–547.Google ScholarCross Ref
20. Shapira, L., Shalom, S., Shamir, A., Cohen-Or, D., and Zhang, H. 2009. Contextual part analogies in 3D objects. Int. J. Comp. Vis. 89, 2–3, 309–326. Google ScholarDigital Library
21. Shilane, P., and Funkhouser, T. 2007. Distinctive regions of 3D surfaces. ACM Trans. on Graph 26, 2, 7: 1–15. Google ScholarDigital Library
22. Singh, S., Gupta, A., and Efros, A. 2012. Unsupervised discovery of mid-level discriminative patches. In Proc. Euro. Conf. on Comp. Vis., 73–86. Google ScholarDigital Library
23. Tsuda, K., and Kudo, T. 2006. Clustering graphs by weighted substructure mining. In Proc. Intl Conf on Machine Learning (ICML), 953–960. Google ScholarDigital Library
24. Tversky, A. 1977. Features of similarity. Psychological Review 84, 4, 327–352.Google ScholarCross Ref
25. van Kaick, O., Xu, K., Zhang, H., Wang, Y., Sun, S., Shamir, A., and Cohen-Or, D. 2013. Co-hierarchical analysis of shape structures. ACM Trans. on Graph (Proc. of SIGGRAPH) 32, 4, 69: 1–10. Google ScholarDigital Library
26. Vidal, R. 2011. Subspace clustering. IEEE Signal Processing Magazine 28, 3, 52–68.Google ScholarCross Ref
27. Wang, S., Yuan, X., Yao, T., Yan, S., and Shen, J. 2011. Efficient subspace segmentation via quadratic programming. In AAAI, 519–524.Google Scholar
28. Wang, Y., Xu, K., Li, J., Zhang, H., Shamir, A., Liu, L., Cheng, Z., and Xiong, Y. 2011. Symmetry hierarchy of man-made objects. Computer Graphics Forum (Special Issue of Eurographics) 30, 2, 287–296.Google ScholarCross Ref
29. Wittgenstein, L. 1953. Philosophical investigations. New York: Macmillan.Google Scholar
30. Xu, K., Zhang, H., Cohen-Or, D., and Chen, B. 2012. Fit and diverse: Set evolution for inspiring 3D shape galleries. ACM Trans. on Graph (Proc. of SIGGRAPH) 31, 4, 57: 1–10. Google ScholarDigital Library
31. Xu, K., Chen, K., Fu, H., Sun, W.-L., and Hu, S.-M. 2013. Sketch2Scene: Sketch-based co-retrieval and co-placement of 3D models. ACM Transactions on Graphics 32, 4, 123: 1–10. Google ScholarDigital Library
32. Yan, X., and Han, J. 2002. gSpan: graph-based substructure pattern mining. In Proc. Int. Conf. on Data Mining, 721–724. Google ScholarDigital Library
33. Zelnik-Manor, L., and Perona, P. 2004. Self-tuning spectral clustering. In Proc. Advances in Neural Information Processing Systems (NIPS), vol. 17, 1601–1608.Google Scholar
34. Zhao, X., Wang, H., and Komura, T. 2014. Indexing 3d scenes using the interaction bisector surface. ACM Trans. on Graph, to appear. Google ScholarDigital Library
35. Zheng, Y., Cohen-Or, D., and Mitra, N. J. 2013. Smart variations: Functional substructures for part compatibility. Computer Graphics Forum (Special Issue of Eurographics) 32, 2, 195–204.Google ScholarCross Ref