
“JALI: an animator-centric viseme model for expressive lip synchronization” by Edwards, Landreth, Fiume and Singh
Conference:
Type(s):
Title:
- JALI: an animator-centric viseme model for expressive lip synchronization
Session/Category Title: FACES & PORTRAITS
Presenter(s)/Author(s):
Moderator(s):
Abstract:
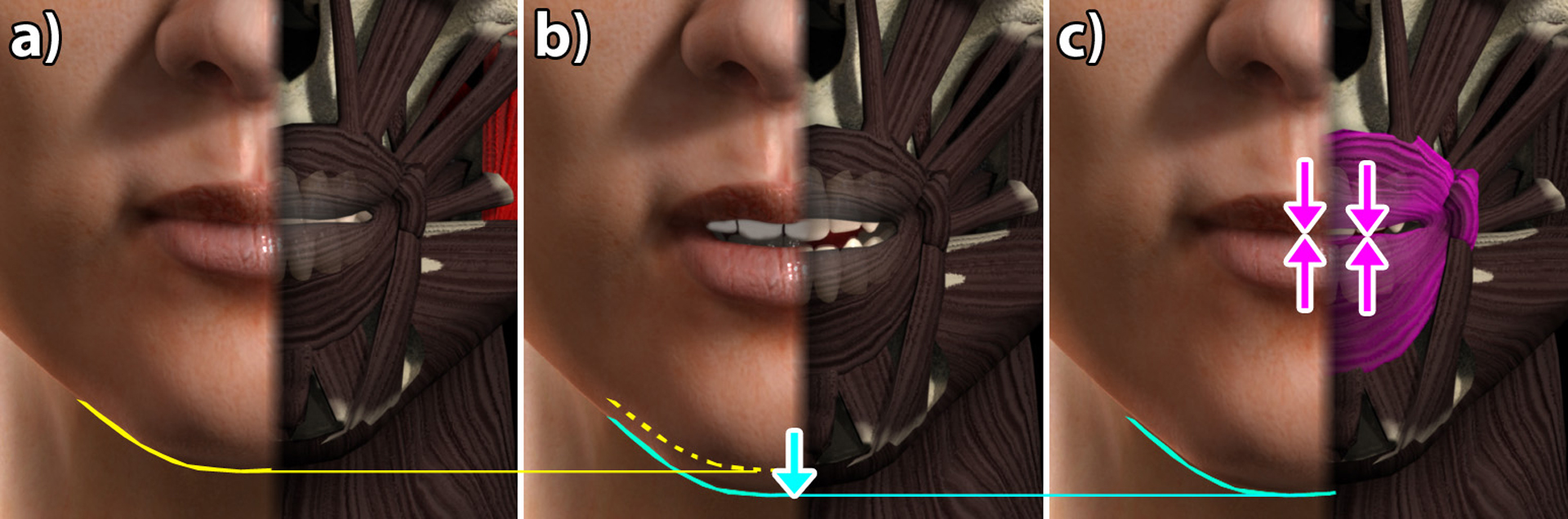
The rich signals we extract from facial expressions imposes high expectations for the science and art of facial animation. While the advent of high-resolution performance capture has greatly improved realism, the utility of procedural animation warrants a prominent place in facial animation workflow. We present a system that, given an input audio soundtrack and speech transcript, automatically generates expressive lip-synchronized facial animation that is amenable to further artistic refinement, and that is comparable with both performance capture and professional animator output. Because of the diversity of ways we produce sound, the mapping from phonemes to visual depictions as visemes is many-valued. We draw from psycholinguistics to capture this variation using two visually distinct anatomical actions: Jaw and Lip, wheresound is primarily controlled by jaw articulation and lower-face muscles, respectively. We describe the construction of a transferable template jali 3D facial rig, built upon the popular facial muscle action unit representation facs. We show that acoustic properties in a speech signal map naturally to the dynamic degree of jaw and lip in visual speech. We provide an array of compelling animation clips, compare against performance capture and existing procedural animation, and report on a brief user study.
References:
1. Albrecht, I., Schröder, M., Haber, J., and Seidel, H.-P. 2005. Mixed feelings: expression of non-basic emotions in a muscle-based talking head. Virtual Reality 8, 4 (Aug.), 201–212. Google ScholarDigital Library
2. Anderson, R., Stenger, B., Wan, V., and Cipolla, R. 2013. Expressive Visual Text-to-Speech Using Active Appearance Models. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 3382–3389. Google ScholarDigital Library
3. Bachorowski, J.-A. 1999. Vocal Expression and Perception of Emotion. Current Directions in Psychological Science 8, 2, 53–57.Google ScholarCross Ref
4. Badin, P., Bailly, G., Revret, L., Baciu, M., Segebarth, C., and Savariaux, C. 2002. Three-dimensional linear articulatory modeling of tongue, lips and face, based on {MRI} and video images. Journal of Phonetics 30, 3, 533–553.Google ScholarCross Ref
5. Bailly, G., Govokhina, O., Elisei, F., and Breton, G. 2009. Lip-Synching Using Speaker-Specific Articulation, Shape and Appearance Models. EURASIP Journal on Audio, Speech, and Music Processing 2009, 1, 1–11. Google ScholarDigital Library
6. Bailly, G., Perrier, P., and Vatikiotis-Bateson, E., Eds. 2012. Audiovisual Speech Processing. Cambridge University Press. Cambridge Books Online.Google Scholar
7. Bailly, G. 1997. Learning to Speak. Sensori-Motor Control of Speech Movements. Speech Communication 22, 2-3 (Aug.), 251–267. Google ScholarDigital Library
8. Banse, R., and Scherer, K. R. 1996. Acoustic Profiles in Vocal Emotion Expression. Journal of Personality and Social Psychology 70, 3 (Mar.), 614–636.Google ScholarCross Ref
9. Bevacqua, E., and Pelachaud, C. 2004. Expressive Audio-Visual Speech. Computer Animation and Virtual Worlds 15, 3-4, 297–304. Google ScholarDigital Library
10. Black, A. W., Taylor, P., and Caley, R. 2001. The Festival Speech Synthesis System: System Documentation Festival version 1.4, 1.4.2 ed.Google Scholar
11. Blair, P. 1947. Advanced Animation: Learn how to draw animated cartoons. Walter T. Foster.Google Scholar
12. Boersma, P., and Weenink, D., 2014. Praat: doing phonetics by computer {Computer Program}. Version 5.4.04, retrieved 28 December 2014 from http://www.praat.org/.Google Scholar
13. Brand, M. 1999. Voice Puppetry. In SIGGRAPH ’99: Proceedings of the 26th annual conference on Computer graphics and interactive techniques, ACM Press, Los Angeles, 21–28. Google ScholarDigital Library
14. Bregler, C., Covell, M., and Slaney, M. 1997. Video rewrite: Driving visual speech with audio. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques, ACM Press/Addison-Wesley Publishing Co., New York, NY, USA, SIGGRAPH ’97, 353–360. Google ScholarDigital Library
15. Brugnara, F., Falavigna, D., and Omologo, M. 1993. Automatic segmentation and labeling of speech based on hidden markov models. Speech Commun. 12, 4 (Aug.), 357–370. Google ScholarDigital Library
16. Cao, Y., Tien, W. C., Faloutsos, P., and Pighin, F. 2005. Expressive Speech-Driven Facial Animation. ACM Transactions on Graphics (TOG) 24, 4, 1283–1302. Google ScholarDigital Library
17. Carnegie Mellon University, 2014. CMU Sphinx: Open Source Toolkit for Speech Recognition {Computer Program}. Version 4, retrieved 28 December 2014 from http://cmusphinx.sourceforge.net/.Google Scholar
18. Chandrasekaran, C., Trubanova, A., Stillittano, S., Caplier, A., and Ghazanfar, A. A. 2009. The Natural Statistics of Audiovisual Speech. PLoS Computational Biology 5, 7 (July), 1–18.Google ScholarCross Ref
19. Cohen, M. M., and Massaro, D. W. 1993. Modeling Coarticulation in Synthetic Visual Speech. Models and Techniques in Computer Animation, 139–156.Google Scholar
20. Cosi, P., Caldognetto, E. M., Perin, G., and Zmarich, C. 2002. Labial Coarticulation Modeling for Realistic Facial Animation. In ICMI’02: IEEE International Conference on Multimodal Interfaces, IEEE Computer Society, 505–510. Google ScholarDigital Library
21. Deng, Z., Neumann, U., Lewis, J. P., Kim, T.-Y., Bulut, M., and Narayanan, S. 2006. Expressive Facial Animation Synthesis by Learning Speech Coarticulation and Expression Spaces. IEEE Transactions on Visualization and Computer Graphics 12, 6 (Nov.), 1523–1534. Google ScholarDigital Library
22. Ekman, P., and Friesen, W. V. 1978. Facial Action Coding System: A Technique for the Measurement of Facial Movement, 1 ed. Consulting Psychologists Press, Palo Alto, California, Aug.Google Scholar
23. Ezzat, T., Geiger, G., and Poggio, T. 2002. Trainable vide-orealistic speech animation. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, ACM, New York, NY, USA, SIGGRAPH ’02, 388–398. Google ScholarDigital Library
24. Fisher, C. G. 1968. Confusions among visually perceived consonants. Journal of Speech, Language, and Hearing Research 11, 4, 796–804.Google ScholarCross Ref
25. Hill, H. C. H., Troje, N. F., and Johnston, A. 2005. Range- and Domain-Specific Exaggeration of Facial Speech. Journal of Vision 5, 10 (Nov.), 4–4.Google ScholarCross Ref
26. Ito, T., Murano, E. Z., and Gomi, H. 2004. Fast Force-Generation Dynamics of Human Articulatory Muscles. Journal of Applied Physiology 96, 6 (June), 2318–2324.Google ScholarCross Ref
27. Jurafsky, D., and Martin, J. H. 2008. Speech and language processing: an introduction to natural language processing, computational linguistics, and speech recognition, 2 ed. Prentice Hall. Google ScholarDigital Library
28. Kent, R. D., and Minifie, F. D. 1977. Coarticulation in Recent Speech Production Models. Journal of Phonetics 5, 2, 115–133.Google ScholarCross Ref
29. King, S. A., and Parent, R. E. 2005. Creating Speech-Synchronized Animation. IEEE Transactions on Visualization and Computer Graphics 11, 3 (May), 341–352. Google ScholarDigital Library
30. Lasseter, J. 1987. Principles of Traditional Animation Applied to 3D Computer Animation. SIGGRAPH Computer Graphics 21, 4, 35–44. Google ScholarDigital Library
31. Li, H., Yu, J., Ye, Y., and Bregler, C. 2013. Realtime Facial Animation with on-the-Fly Correctives. ACM Transactions on Graphics (TOG) 32, 4, 42. Google ScholarDigital Library
32. LibriVox, 2014. LibriVox—free public domain audiobooks. Retrieved 28 December 2014 from https://librivox.org/.Google Scholar
33. Liu, Y., Xu, F., Chai, J., Tong, X., Wang, L., and Huo, Q. 2015. Video-Audio Driven Real-Time Facial Animation. ACM Transactions on Graphics (TOG) 34, 6 (Nov.), 182. Google ScholarDigital Library
34. Ma, X., and Deng, Z. 2012. A Statistical Quality Model for Data-Driven Speech Animation. IEEE Transactions on Visualization and Computer Graphics 18, 11, 1915–1927. Google ScholarDigital Library
35. Ma, J., Cole, R., Pellom, B., Ward, W., and Wise, B. 2006. Accurate visible speech synthesis based on concatenating variable length motion capture data. Visualization and Computer Graphics, IEEE Transactions on 12, 2 (March), 266–276. Google ScholarDigital Library
36. Maniwa, K., Jongman, A., and Wade, T. 2009. Acoustic Characteristics of Clearly Spoken English Fricatives. Journal of the Acoustical Society of America 125, 6, 3962.Google ScholarCross Ref
37. Massaro, D. W., Cohen, M. M., Tabain, M., Beskow, J., and Clark, R. 2012. Animated speech: research progress and applications. In Audiovisual Speech Processing, G. Bailly, P. Perrier, and E. Vatikiotis-Bateson, Eds. Cambridge University Press, Cambridge, 309–345.Google Scholar
38. Mattheyses, W., and Verhelst, W. 2015. Audiovisual Speech Synthesis: An Overview of the State-of-the-Art. Speech Communication 66, C (Feb.), 182–217. Google ScholarDigital Library
39. Metzner, J., Schmittfull, M., and Schnell, K. 2006. Substitute sounds for ventriloquism and speech disorders. In INTERSPEECH 2006 – ICSLP, Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, September 17–21, 2006.Google Scholar
40. Mori, M. 1970. The Uncanny Valley (aka. ‘Bukimi no tani’). Energy 7, 4, 33–35.Google Scholar
41. Orvalho, V., Bastos, P., Parke, F. I., Oliveira, B., and Alvarez, X. 2012. A Facial Rigging Survey. Eurographics 2012 – STAR — State of The Art Report, 183–204.Google Scholar
42. Osipa, J. 2010. Stop staring: facial modeling and animation done right. John Wiley & Sons. Google ScholarDigital Library
43. Pandzic, I. S., and Forchheimer, R., Eds. 2002. MPEG-4 Facial Animation, 1 ed. The Standard, Implementation and Applications. John Wiley & Sons, West Sussex. Google ScholarDigital Library
44. Parke, F. I., and Waters, K. 1996. Computer Facial Animation. A. K. Peters. Google ScholarDigital Library
45. Parke, F. I. 1972. Computer generated animation of faces. In Proceedings of the ACM Annual Conference – Volume 1, ACM, New York, NY, USA, ACM ’72, 451–457. Google ScholarDigital Library
46. Pelachaud, C., Badler, N. I., and Steedman, M. 1996. Generating Facial Expressions for Speech. Cognitive Science 20, 1, 1–46.Google ScholarCross Ref
47. Rossion, B., Hanseeuw, B., and Dricot, L. 2012. Defining face perception areas in the human brain: A large-scale factorial fmri face localizer analysis. Brain and Cognition 79, 2, 138–157.Google ScholarCross Ref
48. Schwartz, J.-L., and Savariaux, C. 2014. No, There Is No 150 ms Lead of Visual Speech on Auditory Speech, but a Range of Audiovisual Asynchronies Varying from Small Audio Lead to Large Audio Lag. PLoS Computational Biology (PLOSCB) 10(7) 10, 7, 1–10.Google Scholar
49. Sifakis, E., Selle, A., Robinson-Mosher, A., and Fedkiw, R. 2006. Simulating Speech With A Physics-Based Facial Muscle Model. In SCA ’06: Proceedings of the 2006 ACM SIGGRAPH/Eurographics symposium on Computer animation, Eurographics Association, Vienna, 261–270. Google ScholarDigital Library
50. Taylor, S. L., Mahler, M., Theobald, B.-J., and Matthews, I. 2012. Dynamic units of visual speech. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Eurographics Association, Aire-la-Ville, Switzerland, Switzerland, SCA ’12, 275–284. Google ScholarDigital Library
51. Taylor, S. L., Theobald, B. J., and Matthews, I. 2014. The Effect of Speaking Rate on Audio and Visual Speech. In Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on, IEEE, Disney Research, Pittsburgh, PA, 3037–3041.Google Scholar
52. Wang, A., Emmi, M., and Faloutsos, P. 2007. Assembling an Expressive Facial Animation System. In Sandbox ’07: Proceedings of the 2007 ACM SIGGRAPH symposium on Video games, ACM. Google ScholarDigital Library
53. Wang, L., Han, W., and Soong, F. K. 2012. High Quality Lip-Sync Animation for 3D Photo-Realistic Talking Head. In ICASSP 2012: IEEE International Conference on Acoustics, Speech and Signal Processing, 4529–4532. Google ScholarDigital Library
54. Weise, T., Li, H., Van Gool, L., and Pauly, M. 2009. Face/Off: live facial puppetry. In SCA ’09: Proceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, ACM Request Permissions, 7–16. Google ScholarDigital Library
55. Weise, T., Bouaziz, S., Li, H., and Pauly, M. 2011. Realtime performance-based facial animation. SIGGRAPH ’11: SIGGRAPH 2011 papers (Aug.). Google ScholarDigital Library
56. Williams, L. 1990. Performance-driven facial animation. In Proceedings of the 17th Annual Conference on Computer Graphics and Interactive Techniques, ACM, New York, NY, USA, SIGGRAPH ’90, 235–242. Google ScholarDigital Library
57. Xu, Y., Feng, A. W., Marsella, S., and Shapiro, A. 2013. A Practical and Configurable Lip Sync Method for Games. In Proceedings – Motion in Games 2013, MIG 2013, USC Institute for Creative Technologies, 109–118. Google ScholarDigital Library
58. Young, S. J., and Young, S. 1993. The HTK Hidden Markov Model Toolkit: Design and Philosophy. University of Cambridge, Department of Engineering.Google Scholar