
“Autoencoding Blade Runner: Reconstructing Films with Artificial Neural Networks” by Broad and Grierson
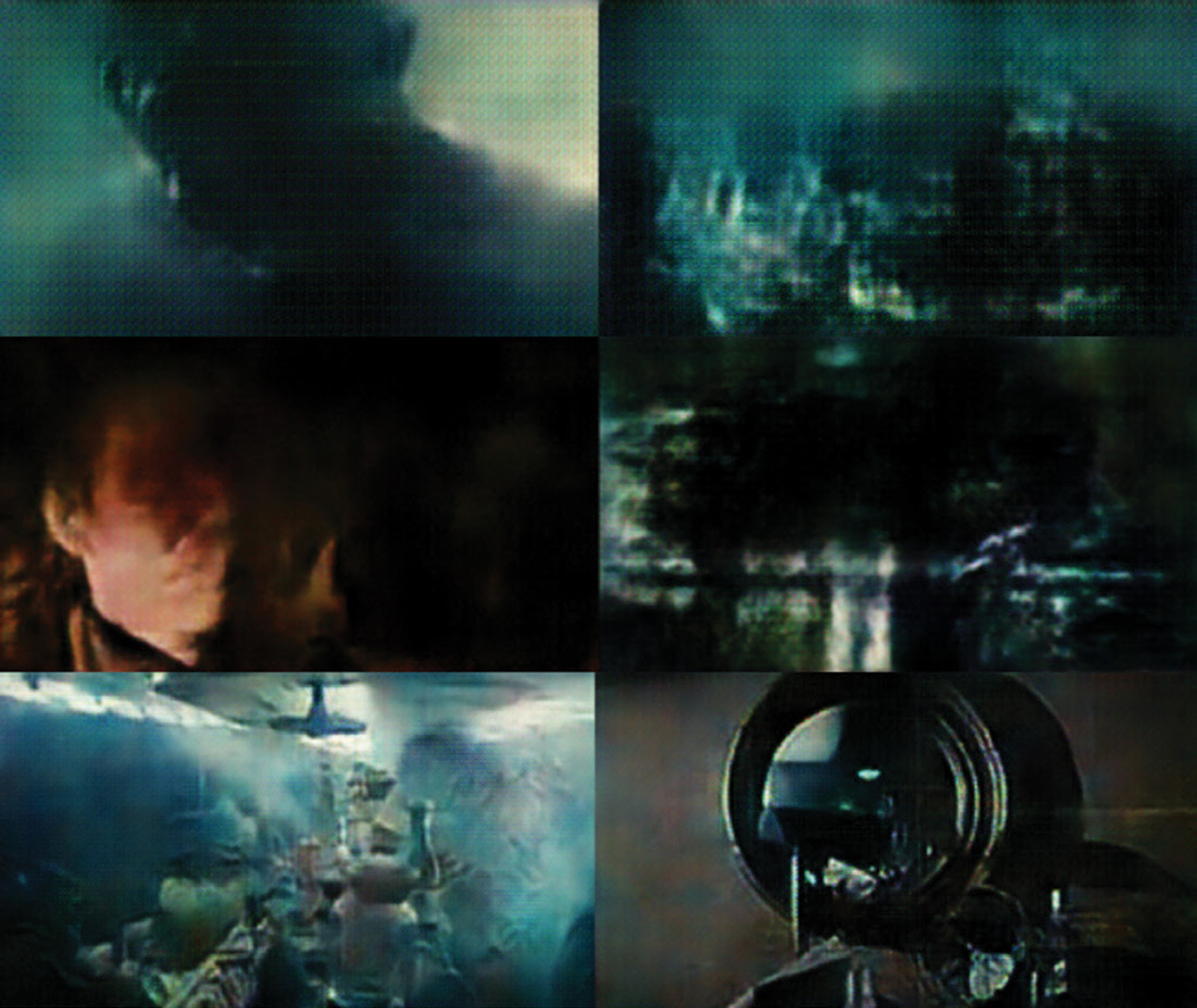
Conference:
Type(s):
Title:
- Autoencoding Blade Runner: Reconstructing Films with Artificial Neural Networks
Presenter(s)/Author(s):
Abstract:
In this paper, the authors explain how they created Blade Runner—Autoencoded, a film made by training an autoencoder—a type of generative neural network—to recreate frames from the film Blade Runner. The autoencoder is made to reinterpret every individual frame, reconstructing it based on its memory of the film. The result is a hazy, dreamlike version of the original film. The authors discuss how the project explores the aesthetic qualities of the disembodied gaze of the neural network and describe how the autoencoder is also capable of reinterpreting films it has not been trained on, transferring the visual style it has learned from watching Blade Runner (1982).
References:
1. M. Casey and M. Grierson, “Soundspotter/remix-tv: fast approximate matching for audio and video performance,” Proceedings of the International Computer Music Conference (2007).
2. M. Grierson, “Plundermatics: real-time interactive media segmentation for audiovisual analysis, composition and performance,” Proceedings of Electronic Visualisation and the Arts Conference, Computer Arts Society, London (2009).
3. P.K. Mital, M. Grierson, and T.J. Smith, “Corpus-based visual synthesis: an approach for artistic stylization,” Proceedings of the ACM Symposium on Applied Perception (2013) pp. 51–58.
4. P.K. Mital, YouTube Smash Up (2014), <http://pkmital.com/home/youtube-smash-up/>.
5. S. Nishimoto, et al., “Reconstructing visual experiences from brain activity evoked by natural movies,” Current Biology 21, No. 19, 1641–1646 (2011).
6. A. Krizhevsky, I. Sutskever, and G.E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in Neural Information Processing Systems (2012) pp. 1097–1105.
7. C. Szegedy, et al., “Intriguing properties of neural networks,” The International Conference on Learning Representations (2014).
8. D.P. Kingma and M. Welling, “Auto-encoding variational Bayes,” The International Conference on Learning Representations (2014).
9. D.J. Rezende, S. Mohamed, and D. Wierstra, “Stochastic backpropagation and approximate inference in deep generative models,” The International Conference on Machine Learning (2014) pp. 1278–1286.
10. I. Goodfellow, et al., “Generative Adversarial Nets,” Advances in Neural Information Processing Systems (2014) pp. 2672–2680.
11. A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” The International Conference on Learning Representations (2016).
12. A.B. Larsen, S.K. Sønderby, and O. Winther, “Autoencoding beyond pixels using a learned similarity metric,” The International Conference on Machine Learning (2016) pp. 1558–1566.
13. The original source code for this project is available at <https://github.com/terrybroad/ Learned-Sim-Autoencoder-For-Video-Frames>.
14. Wikipedia article for the MNIST handwritten digits dataset is available at <https://en.wikipedia.org/ wiki/ MNIST_database>.
15. The CelebFaces dataset was created and first discussed by the authors of this paper: Z. Liu, et al., “Deep learning face attributes in the wild,” Proceedings of the IEEE International Conference on Computer Vision (2015) pp. 3730–3738.
16. T. Broad and M. Grierson, “Autoencoding Video Frames,” Technical Report (London: Goldsmiths, 2016), available at <http://research.gold.ac.uk/19559/>.
17. A side-by-side comparison of Man with a Movie Camera and its reconstruction using the Blade Runner model, as well as other films such as A Scanner Darkly and Koyaanisqatsi are available to watch online at the following YouTube playlist: <https://www.youtube.com/ playlist?list=PLJME4hivCPY_B_ MqOyQQGC_kuYUz518-C>.
18. P. Isola, J. Zhu, T. Zhou, and A. Efros, “Image-to-image translation with conditional adversarial networks,” arXiv preprint arXiv:1611.07004 (2016).
19. P.K. Dick, Do Androids Dream of Electric Sheep? (New York: Random House USA, 1982).
20. J. Brandt, “What defines human?” (2000), <http://www.br-insight.com/what-defines-human>.
21. A. Romano, “A guy trained a machine to ‘watch’ Blade Runner. Then things got seriously sci-fi” (2016), available at <http://www.vox.com/2016/6/1/11787262/blade-runner-neural-network-encoding>.
22. C. Iles, “The Cyborg and the Sensorium,” Dreamlands: Immersive Cinema and Art, 1905–2016 (New Haven: Yale University Press, 2016) p. 121.
23. C. Iles, personal communication, 2017.
24. H. Steyerl, “In Free Fall: A Thought Experiment on Vertical Perspective,” The Wretched of the Screen (Berlin: Sternberg Press, 2012) p. 24.
25. L. Lek, “Geomancer” (2017), available at https://vimeo.com/208910806/5e2e08b486.