
“Mixture of volumetric primitives for efficient neural rendering” by Lombardi, Simon, Schwartz, Zollhoefer, Sheikh, et al. …
Conference:
Type(s):
Title:
- Mixture of volumetric primitives for efficient neural rendering
Presenter(s)/Author(s):
Abstract:
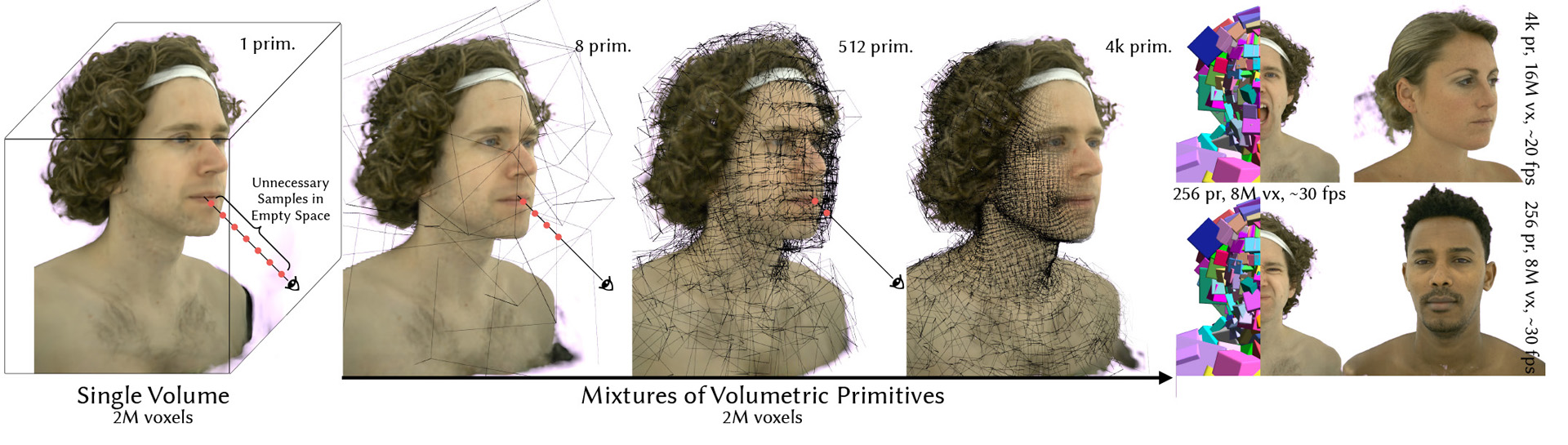
Real-time rendering and animation of humans is a core function in games, movies, and telepresence applications. Existing methods have a number of drawbacks we aim to address with our work. Triangle meshes have difficulty modeling thin structures like hair, volumetric representations like Neural Volumes are too low-resolution given a reasonable memory budget, and high-resolution implicit representations like Neural Radiance Fields are too slow for use in real-time applications. We present Mixture of Volumetric Primitives (MVP), a representation for rendering dynamic 3D content that combines the completeness of volumetric representations with the efficiency of primitive-based rendering, e.g., point-based or mesh-based methods. Our approach achieves this by leveraging spatially shared computation with a convolutional architecture and by minimizing computation in empty regions of space with volumetric primitives that can move to cover only occupied regions. Our parameterization supports the integration of correspondence and tracking constraints, while being robust to areas where classical tracking fails, such as around thin or translucent structures and areas with large topological variability. MVP is a hybrid that generalizes both volumetric and primitive-based representations. Through a series of extensive experiments we demonstrate that it inherits the strengths of each, while avoiding many of their limitations. We also compare our approach to several state-of-the-art methods and demonstrate that MVP produces superior results in terms of quality and runtime performance.
References:
1. Rameen Abdal, Yipeng Qin, and Peter Wonka. 2019. Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).Google ScholarCross Ref
2. Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, and Victor Lempitsky. 2019. Neural point-based graphics. arXiv preprint arXiv:1906.08240 (2019).Google Scholar
3. Benjamin Attal, Selena Ling, Aaron Gokaslan, Christian Richardt, and James Tompkin. 2020. MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images. arXiv preprint arXiv:2008.06534 (2020).Google Scholar
4. Michael Broxton, John Flynn, Ryan Overbeck, Daniel Erickson, Peter Hedman, Matthew Duvall, Jason Dourgarian, Jay Busch, Matt Whalen, and Paul Debevec. 2020. Immersive Light Field Video with a Layered Mesh Representation. ACM Trans. Graph. 39, 4, Article 86 (July 2020), 15 pages. Google ScholarDigital Library
5. Rohan Chabra, Jan Eric Lenssen, Eddy Ilg, Tanner Schmidt, Julian Straub, Steven Lovegrove, and Richard Newcombe. 2020. Deep Local Shapes: Learning Local SDF Priors for Detailed 3D Reconstruction. arXiv preprint arXiv:2003.10983 (2020).Google Scholar
6. Wenzheng Chen, Huan Ling, Jun Gao, Edward Smith, Jaakko Lehtinen, Alec Jacobson, and Sanja Fidler. 2019. Learning to predict 3d objects with an interpolation-based differentiable renderer. In Advances in Neural Information Processing Systems. 9609–9619.Google Scholar
7. Christopher B Choy, Danfei Xu, Jun Young Gwak, Kevin Chen, and Silvio Savarese. 2016. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In European conference on computer vision. Springer, 628–644.Google ScholarCross Ref
8. Yilun Du, Yinan Zhang, Hong-Xing Yu, Joshua B. Tenenbaum, and Jiajun Wu. 2020. Neural Radiance Flow for 4D View Synthesis and Video Processing. arXiv preprint arXiv:2012.09790 (2020).Google Scholar
9. Guy Gafni, Justus Thies, Michael Zollh?fer, and Matthias Nie?ner. 2020. Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction. https://arxiv.org/abs/2012.03065 (2020).Google Scholar
10. Chen Gao, Yichang Shih, Wei-Sheng Lai, Chia-Kai Liang, and Jia-Bin Huang. 2020. Portrait Neural Radiance Fields from a Single Image. https://arxiv.org/abs/2012.05903 (2020).Google Scholar
11. Kyle Genova, Forrester Cole, Aaron Maschinot, Aaron Sarna, Daniel Vlasic, and William T Freeman. 2018. Unsupervised training for 3d morphable model regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 8377–8386.Google ScholarCross Ref
12. Kyle Genova, Forrester Cole, Avneesh Sud, Aaron Sarna, and Thomas Funkhouser. 2020. Local Deep Implicit Functions for 3D Shape. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4857–4866.Google ScholarCross Ref
13. Eldar Insafutdinov and Alexey Dosovitskiy. 2018. Unsupervised Learning of Shape and Pose with Differentiable Point Clouds. In Advances in Neural Information Processing Systems 31 (NIPS 2018), S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.). Curran Associates, Montr?al, Canada, 2804–2814.Google Scholar
14. Chiyu Jiang, Avneesh Sud, Ameesh Makadia, Jingwei Huang, Matthias Nie?ner, and Thomas Funkhouser. 2020. Local implicit grid representations for 3d scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6001–6010.Google ScholarCross Ref
15. Abhishek Kar, Christian H?ne, and Jitendra Malik. 2017. Learning a multi-view stereo machine. In Advances in neural information processing systems. 365–376.Google Scholar
16. Tero Karras and Timo Aila. 2013. Fast Parallel Construction of High-Quality Bounding Volume Hierarchies. In Proceedings of the 5th High-Performance Graphics Conference (Anaheim, California) (HPG ’13). Association for Computing Machinery, New York, NY, USA, 89–99. Google ScholarDigital Library
17. Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and Improving the Image Quality of StyleGAN. In Proc. CVPR.Google ScholarCross Ref
18. Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. 2018. Neural 3d mesh renderer. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Google ScholarCross Ref
19. Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1412.6980Google Scholar
20. Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013).Google Scholar
21. Maria Kolos, Artem Sevastopolsky, and Victor Lempitsky. 2020. TRANSPR: Transparency Ray-Accumulating Neural 3D Scene Point Renderer. arXiv:2009.02819Google Scholar
22. Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. 2020. Modular Primitives for High-Performance Differentiable Rendering. ACM Transactions on Graphics 39, 6 (2020).Google ScholarDigital Library
23. Christoph Lassner and Michael Zollh?fer. 2020. Pulsar: Efficient Sphere-based Neural Rendering. arXiv:2004.07484 [cs.GR]Google Scholar
24. Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. 2020. Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes. https://arxiv.org/abs/2011.13084 (2020).Google Scholar
25. Chen-Hsuan Lin, Chen Kong, and Simon Lucey. 2018. Learning efficient point cloud generation for dense 3d object reconstruction. In Thirty-Second AAAI Conference on Artificial Intelligence.Google ScholarCross Ref
26. Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. 2020. Neural Sparse Voxel Fields. arXiv:2007.11571Google Scholar
27. Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. 2019. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE International Conference on Computer Vision. 7708–7717.Google ScholarCross Ref
28. Stephen Lombardi, Jason Saragih, Tomas Simon, and Yaser Sheikh. 2018. Deep Appearance Models for Face Rendering. ACM Trans. Graph. 37, 4, Article 68 (July 2018), 13 pages. Google ScholarDigital Library
29. Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. 2019. Neural Volumes: Learning Dynamic Renderable Volumes from Images. ACM Trans. Graph. 38, 4, Article 65 (July 2019), 14 pages. Google ScholarDigital Library
30. Matthew M Loper and Michael J Black. 2014. OpenDR: An approximate differentiable renderer. In European Conference on Computer Vision. Springer, 154–169.Google ScholarCross Ref
31. Feng Liu Xiaoming Liu Luan Tran. 2019. Towards High-fidelity Nonlinear 3D Face Morphoable Model. In IEEE Computer Vision and Pattern Recognition (CVPR).Google Scholar
32. Ricardo Martin-Brualla, Noha Radwan, Mehdi Sajjadi, Jonathan Barron, Alexey Dosovitskiy, and Daniel Duckworth. 2020. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. https://arxiv.org/abs/2008.02268 (2020).Google Scholar
33. Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. 2019. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Conference on Computer Vision and Pattern Recognition (CVPR).Google ScholarCross Ref
34. Moustafa Meshry, Dan B Goldman, Sameh Khamis, Hugues Hoppe, Rohit Pandey, Noah Snavely, and Ricardo Martin-Brualla. 2019. Neural rerendering in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6878–6887.Google ScholarCross Ref
35. Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. 2019. Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines. ACM Transactions on Graphics (TOG) (2019).Google Scholar
36. Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. Nerf: Representing scenes as neural radiance fields for view synthesis. arXiv preprint arXiv:2003.08934 (2020).Google Scholar
37. Sergio Orts-Escolano, Christoph Rhemann, SeanFanello, Wayne Chang, Adarsh Kowdle, Yury Degtyarev, David Kim, Philip L. Davidson, Sameh Khamis, Mingsong Dou, Vladimir Tankovich, Charles Loop, Qin Cai, Philip A. Chou, Sarah Mennicken, Julien Valentin, Vivek Pradeep, Shenlong Wang, Sing Bing Kang, Pushmeet Kohli, Yuliya Lutchyn, Cem Keskin, and Shahram Izadi. 2016. Holoportation: Virtual 3D Teleportation in Real-Time. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology (Tokyo, Japan) (UIST ’16). Association for Computing Machinery, New York, NY, USA, 741–754.Google ScholarDigital Library
38. Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Love-grove. 2019. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 165–174.Google ScholarCross Ref
39. Keunhong Park, Utkarsh Sinha, Jonathan Barron, Sofien Bouaziz, Dan Goldman, Steven Seitz, and Ricardo Martin-Brualla. 2020. Deformable Neural Radiance Fields. https://arxiv.org/abs/2011.12948 (2020).Google Scholar
40. Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. 2020. Convolutional Occupancy Networks. In European Conference on Computer Vision (ECCV).Google Scholar
41. Felix Petersen, Amit H Bermano, Oliver Deussen, and Daniel Cohen-Or. 2019. Pix2vex: Image-to-geometry reconstruction using a smooth differentiable renderer. arXiv preprint arXiv:1903.11149 (2019).Google Scholar
42. Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. 2020. PyTorch3D. https://github.com/facebookresearch/pytorch3d.Google Scholar
43. Daniel Rebain, Wei Jiang, Soroosh Yazdani, Ke Li, Kwang Moo Yi, and Andrea Tagliasacchi. 2020. DeRF: Decomposed Radiance Fields. https://arxiv.org/abs/2011.12490 (2020).Google Scholar
44. O. Ronneberger, P. Fischer, and T. Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI) (LNCS, Vol. 9351). Springer, 234–241.Google Scholar
45. Riccardo Roveri, Lukas Rahmann, Cengiz Oztireli, and Markus Gross. 2018. A network architecture for point cloud classification via automatic depth images generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4176–4184.Google ScholarCross Ref
46. Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. 2019a. PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization. https://arxiv.org/abs/1905.05172 (2019).Google Scholar
47. Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. 2019b. PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization. In Proceedings of the IEEE International Conference on Computer Vision. 2304–2314.Google ScholarCross Ref
48. Johannes Lutz Sch?nberger and Jan-Michael Frahm. 2016. Structure-from-Motion Revisited. In Conference on Computer Vision and Pattern Recognition (CVPR).Google Scholar
49. Johannes Lutz Sch?nberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. 2016. Pixelwise View Selection for Unstructured Multi-View Stereo. In European Conference on Computer Vision (ECCV).Google Scholar
50. Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. 2020. GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis. arXiv:2007.02442 [cs.CV]Google Scholar
51. V. Sitzmann, J. Thies, F. Heide, M. Nie?ner, G. Wetzstein, and M. Zollh?fer. 2019a. DeepVoxels: Learning Persistent 3D Feature Embeddings. In Proceedings of Computer Vision and Pattern Recognition (CVPR 2019).Google Scholar
52. Vincent Sitzmann, Michael Zollh?fer, and Gordon Wetzstein. 2019b. Scene representation networks: Continuous 3d-structure-aware neural scene representations. In Advances in Neural Information Processing Systems. 1121–1132.Google Scholar
53. Pratul Srinivasan, Boyang Deng, Xiuming Zhang, Matthew Tancik, Ben Mildenhall, and Jonathan Barron. 2020. NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis. https://arxiv.org/abs/2012.03927 (2020).Google Scholar
54. Pratul P. Srinivasan, Richard Tucker, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng, and Noah Snavely. 2019. Pushing the Boundaries of View Extrapolation With Multiplane Images. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR. 175–184.Google Scholar
55. Matthew Tancik, Ben Mildenhall, Terrence Wang, Divi Schmidt, Pratul Srinivasan, Jonathan Barron, and Ren Ng. 2020. Learned Initializations for Optimizing Coordinate-Based Neural Representations. https://arxiv.org/abs/2012.02189 (2020).Google Scholar
56. A. Tewari, O. Fried, J. Thies, V. Sitzmann, S. Lombardi, K. Sunkavalli, R. Martin-Brualla, T. Simon, J. Saragih, M. Nie?ner, R. Pandey, S. Fanello, G. Wetzstein, J.-Y. Zhu, C. Theobalt, M. Agrawala, E. Shechtman, D. B Goldman, and M. Zollh?fer. 2020. State of the Art on Neural Rendering. Computer Graphics Forum (EG STAR 2020) (2020).Google Scholar
57. Ayush Tewari, Michael Zollh?fer, Pablo Garrido, Florian Bernard, Hyeongwoo Kim, Patrick P?rez, and Christian Theobalt. 2018. Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Google ScholarCross Ref
58. Justus Thies, Michael Zollh?fer, and Matthias Nie?ner. 2019. Deferred Neural Rendering: Image Synthesis using Neural Textures. ACM Transactions on Graphics 2019 (TOG) (2019).Google ScholarDigital Library
59. Edgar Tretschk, Ayush Tewari, Vladislav Golyanik, Michael Zollh?fer, Christoph Lassner, and Christian Theobalt. 2020. Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Deforming Scene from Monocular Video. arXiv:2012.12247 [cs.CV]Google Scholar
60. Alex Trevithick and Bo Yang. 2020. GRF: Learning a General Radiance Field for 3D Scene Representation and Rendering. https://arxiv.org/abs/2010.04595 (2020).Google Scholar
61. Richard Tucker and Noah Snavely. 2020. Single-view View Synthesis with Multiplane Images. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Google Scholar
62. Shubham Tulsiani, Tinghui Zhou, Alexei A Efros, and Jitendra Malik. 2017. Multi-view supervision for single-view reconstruction via differentiable ray consistency. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2626–2634.Google ScholarCross Ref
63. Julien Valentin, Cem Keskin, Pavel Pidlypenskyi, Ameesh Makadia, Avneesh Sud, and Sofien Bouaziz. 2019. TensorFlow Graphics: Computer Graphics Meets Deep Learning.Google Scholar
64. Shih-En Wei, Jason Saragih, Tomas Simon, Adam W. Harley, Stephen Lombardi, Michal Perdoch, Alexander Hypes, Dawei Wang, Hernan Badino, and Yaser Sheikh. 2019. VR Facial Animation via Multiview Image Translation. ACM Trans. Graph. 38, 4, Article 67 (July 2019), 16 pages.Google ScholarDigital Library
65. Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. 2020. Synsin: End-to-end view synthesis from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7467–7477.Google ScholarCross Ref
66. Chenglei Wu, Takaaki Shiratori, and Yaser Sheikh. 2018. Deep Incremental Learning for Efficient High-Fidelity Face Tracking. ACM Trans. Graph. 37, 6, Article 234 (Dec. 2018), 12 pages. Google ScholarDigital Library
67. Jiajun Wu, Chengkai Zhang, Tianfan Xue, Bill Freeman, and Josh Tenenbaum. 2016. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Advances in neural information processing systems. 82–90.Google Scholar
68. Wenqi Xian, Jia-Bin Huang, Johannes Kopf, and Changil Kim. 2020. Space-time Neural Irradiance Fields for Free-Viewpoint Video. https://arxiv.org/abs/2011.12950 (2020).Google Scholar
69. Wang Yifan, Felice Serena, Shihao Wu, Cengiz ?ztireli, and Olga Sorkine-Hornung. 2019. Differentiable surface splatting for point-based geometry processing. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1–14.Google ScholarDigital Library
70. Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. 2020. pixelNeRF: Neural Radiance Fields from One or Few Images. https://arxiv.org/abs/2012.02190 (2020).Google Scholar
71. Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. 2018. Stereo magnification: Learning view synthesis using multiplane images. arXiv preprint arXiv:1805.09817 (2018).Google Scholar