
“Depth Assisted Full Resolution Network for Single Image-based View Synthesis” by Cun, Xu, Pun and Gao


Conference:
Type(s):
Title:
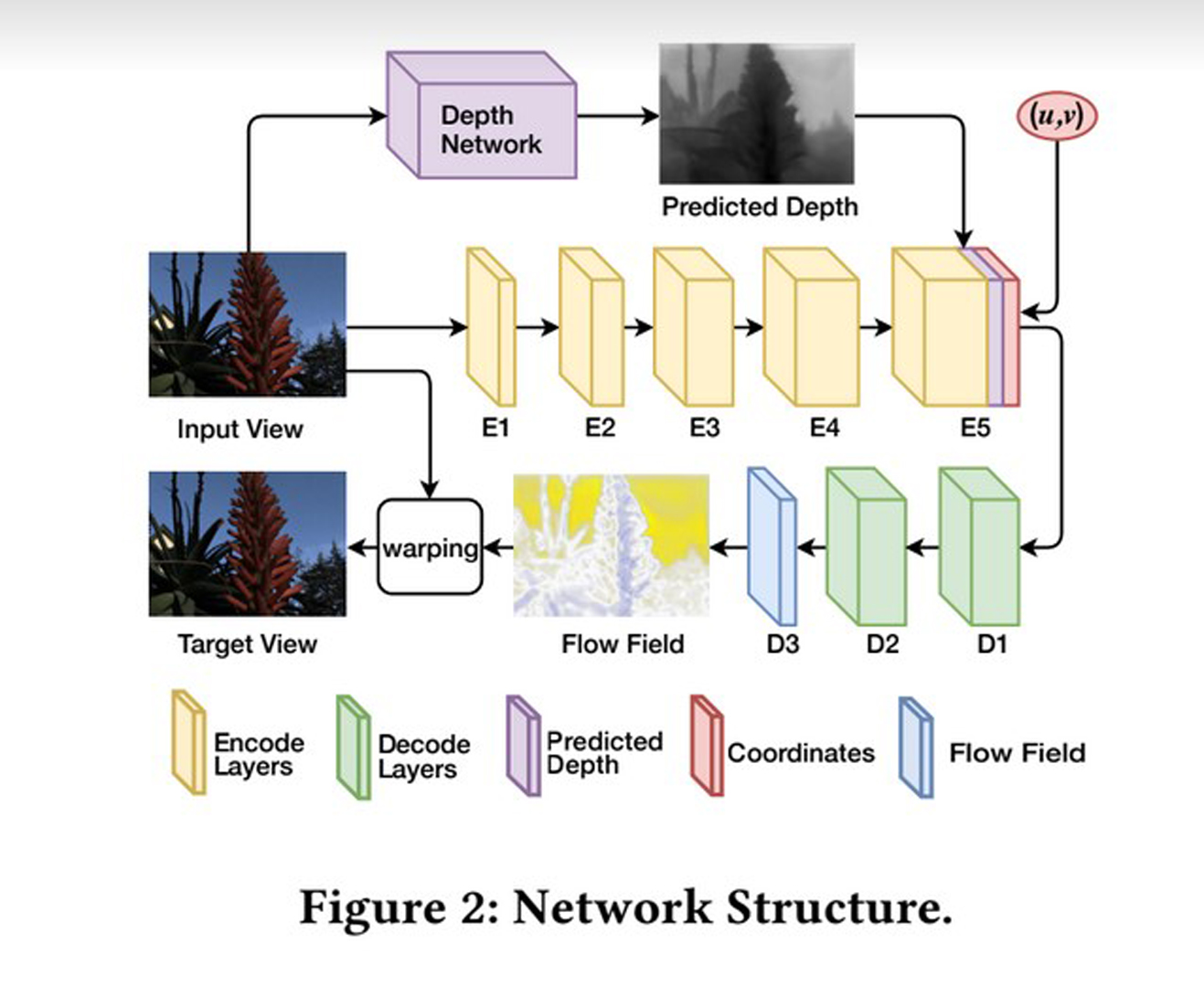
- Depth Assisted Full Resolution Network for Single Image-based View Synthesis
Presenter(s)/Author(s):
Entry Number:
- 59
Abstract:
INTRODUCTION
Synthesizing images of novel viewpoints is widely investigated in computer vision and graphics. Most works in this topic focus on using multi-view images to synthesize viewpoints in-between. In this paper, we consider extrapolation, and we take a step further to do extrapolation from one single input image. This task is very challenging for two major reasons. First, some parts of the scene may not be observed in the input viewpoint but are required for novel ones. Second, 3D information is lacking for single view input but is crucial to determine pixel movements between viewpoints. Although very challenging, we observe that human brains are always able to imagine novel viewpoints. The reason is that human brains have learned in our daily lives to understand the depth order of objects in a scene [Chen et al. 2016] and infer what the scene looks like when viewing from another viewpoint.
References:
- Weifeng Chen, Zhao Fu, Dawei Yang, and Jia Deng. 2016. Single-Image Depth Perception in the Wild. In NIPS. 730–738. http://papers.nips.cc/paper/ 6489-single-image-depth-perception-in-the-wild.pdf
- Nima Khademi Kalantari, Ting-Chun Wang, and Ravi Ramamoorthi. 2016. LearningBased View Synthesis for Light Field Cameras. ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2016) 35, 6 (2016).
- Pratul P. Srinivasan, Tongzhou Wang, Ashwin Sreelal, Ravi Ramamoorthi, and Ren Ng. 2017. Learning to Synthesize a 4D RGBD Light Field from a Single Image. International Conference on Computer Vision (ICCV) (2017).
- Junyuan Xie, Ross Girshick, and Ali Farhadi. 2016. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In ECCV. Springer, 842–857.
- Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Malik, and Alexei A Efros. 2016. View Synthesis by Appearance Flow. In ECCV
Keyword(s):
Additional Images:
-

- 2018 Posters: Cun_Depth Assisted Full Resolution Network for Single Image-based View Synthesis

Acknowledgements:
This work was supported in part by the Science and Technology Development Fund of Macau SAR under Grants 093/2014/A2 and 041/2017/A1.