
“COFS: COntrollable Furniture layout Synthesis” by Para, Guerrero, Mitra and Wonka
Conference:
Type(s):
Title:
- COFS: COntrollable Furniture layout Synthesis
Session/Category Title:
- Diffusion For Geometry
Presenter(s)/Author(s):
Moderator(s):
Abstract:
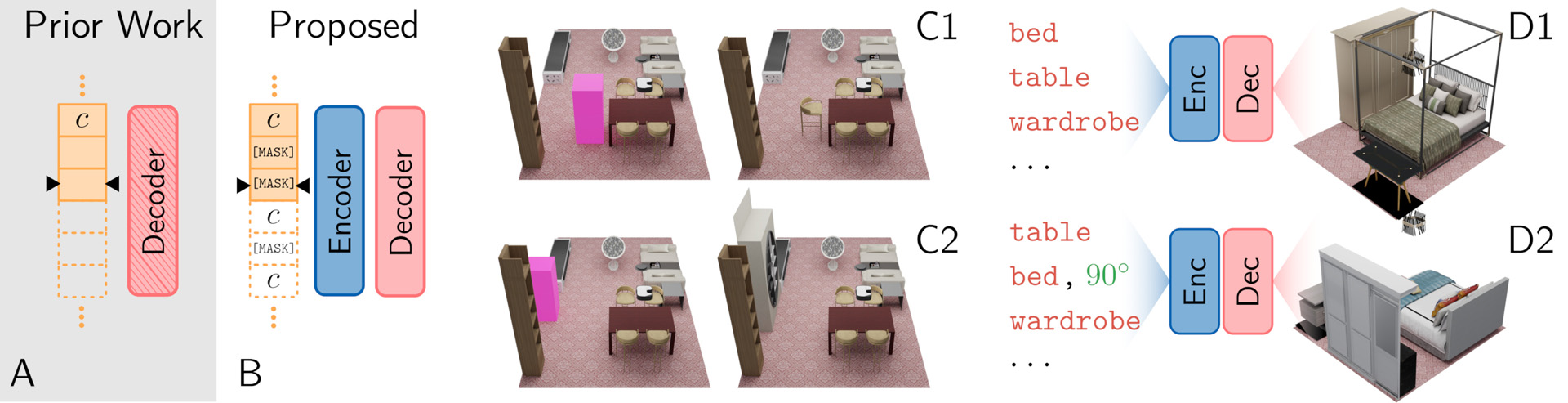
Realistic, scalable, and controllable generation of furniture layouts is essential for many applications in virtual reality, augmented reality, game development and synthetic data generation. The most successful current methods tackle this problem as a sequence generation problem which imposes a specific ordering on the elements of the layout, making it hard to exert fine-grained control over the attributes of a generated scene. Existing methods provide control through object-level conditioning, or scene completion, where generation can be conditioned on an arbitrary subset of furniture objects. However, attribute-level conditioning, where generation can be conditioned on an arbitrary subset of object attributes, is not supported. We propose COFS, a method to generate furniture layouts that enables fine-grained control through attribute-level conditioning. For example, COFS allows specifying only the scale and type of objects that should be placed in the scene and the generator chooses their positions and orientations; or the position that should be occupied by objects can be specified and the generator chooses their type, scale, orientation, etc. Our results show both qualitatively and quantitatively that we significantly outperform existing methods on attribute-level conditioning.
References:
1. Tom?B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel?M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. (2020). arxiv:2005.14165?[cs.CL]
2. Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-End Object Detection with Transformers. In ECCV.
3. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William?T. Freeman. 2022. MaskGIT: Masked Generative Image Transformer. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
4. R.?Qi Charles, Hao Su, Mo Kaichun, and Leonidas?J. Guibas. 2017. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 77?85. https://doi.org/10.1109/CVPR.2017.16
5. Shuai?Li Chenhang?He, Ruihuang?Li and Lei Zhang. 2022. Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
6. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 4171?4186. https://doi.org/10.18653/v1/N19-1423
7. Patrick Esser, Robin Rombach, and Bj?rn Ommer. 2021. Taming Transformers for High-Resolution Image Synthesis. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12868?12878. https://doi.org/10.1109/CVPR46437.2021.01268
8. Matthew Fisher, Daniel Ritchie, Manolis Savva, Thomas Funkhouser, and Pat Hanrahan. 2012. Example-Based Synthesis of 3D Object Arrangements. ACM Trans. Graph. 31, 6, Article 135 (Nov 2012), 11?pages. https://doi.org/10.1145/2366145.2366154
9. Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, and Hao Zhang. 2021. 3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 10913?10922. https://doi.org/10.1109/ICCV48922.2021.01075
10. James Gentle. 2000. Monte Carlo Statistical Methods by C. P. Robert; G. Casella. Journal of the Royal Statistical Society. Series D (The Statistician) 49 (01 2000), 632?633. https://doi.org/10.2307/2681053
11. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770?778. https://doi.org/10.1109/CVPR.2016.90
12. Thibaut Issenhuth, Ugo Tanielian, J?r?mie Mary, and David Picard. 2021. EdiBERT, a generative model for image editing. arXiv preprint arXiv:2111.15264 (2021).
13. Xiang Kong, Lu Jiang, Huiwen Chang, Han Zhang, Yuan Hao, Haifeng Gong, and Irfan Essa. 2022. BLT: Bidirectional Layout Transformer For Controllable Layout Generation. In Computer Vision ? ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23?27, 2022, Proceedings, Part XVII (Tel Aviv, Israel). Springer-Verlag, Berlin, Heidelberg, 474?490. https://doi.org/10.1007/978-3-031-19790-1_29
14. Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee?Whye Teh. 2019. Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. In Proceedings of the 36th International Conference on Machine Learning. 3744?3753.
15. Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 7871?7880. https://doi.org/10.18653/v1/2020.acl-main.703
16. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
17. Elman Mansimov, Alex Wang, and Kyunghyun Cho. 2020. A Generalized Framework of Sequence Generation with Application to Undirected Sequence Models. https://openreview.net/forum?id=BJlbo6VtDH
18. Dror Moran, Hodaya Koslowsky, Yoni Kasten, Haggai Maron, Meirav Galun, and Ronen Basri. 2021. Deep Permutation Equivariant Structure from Motion. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 5956?5966. https://doi.org/10.1109/ICCV48922.2021.00592
19. Wamiq Para, Paul Guerrero, Tom Kelly, Leonidas Guibas, and Peter Wonka. 2021. Generative Layout Modeling using Constraint Graphs. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 6670?6680. https://doi.org/10.1109/ICCV48922.2021.00662
20. Despoina Paschalidou, Amlan Kar, Maria Shugrina, Karsten Kreis, Andreas Geiger, and Sanja Fidler. 2021. ATISS: Autoregressive Transformers for Indoor Scene Synthesis. In Advances in Neural Information Processing Systems (NeurIPS).
21. Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. (2019).
22. Siamak Ravanbakhsh, Jeff Schneider, and Barnabas Poczos. 2016. Deep learning with sets and point clouds. arXiv preprint arXiv:1611.04500 (2016).
23. Daniel Ritchie, Kai Wang, and Yu-An Lin. 2019. Fast and Flexible Indoor Scene Synthesis via Deep Convolutional Generative Models. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6175?6183. https://doi.org/10.1109/CVPR.2019.00634
24. Julian Salazar, Davis Liang, Toan?Q. Nguyen, and Katrin Kirchhoff. 2020. Masked Language Model Scoring. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 2699?2712. https://doi.org/10.18653/v1/2020.acl-main.240
25. Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik?P. Kingma. 2017. PixelCNN++: A PixelCNN Implementation with Discretized Logistic Mixture Likelihood and Other Modifications. In ICLR.
26. Nicolas Ugrinovic, Adria Ruiz, Antonio Agudo, Alberto Sanfeliu, and Francesc Moreno-Noguer. 2022. Permutation-Invariant Relational Network for Multi-person 3D Pose Estimation. arXiv preprint arXiv:2204.04913 (2022).
27. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan?N. Gomez, ?ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (Long Beach, California, USA) (NIPS?17). Curran Associates Inc., Red Hook, NY, USA, 6000?6010.
28. Alex Wang and Kyunghyun Cho. 2019. Bert has a mouth, and it must speak: Bert as a markov random field language model. arXiv preprint arXiv:1902.04094 (2019).
29. Kai Wang, Yu-An Lin, Ben Weissmann, Manolis Savva, Angel?X. Chang, and Daniel Ritchie. 2019. PlanIT: Planning and Instantiating Indoor Scenes with Relation Graph and Spatial Prior Networks. ACM Trans. Graph. 38, 4, Article 132 (jul 2019), 15?pages. https://doi.org/10.1145/3306346.3322941
30. Xinpeng Wang, Chandan Yeshwanth, and Matthias Nie?ner. 2021. Sceneformer: Indoor scene generation with transformers. In 2021 International Conference on 3D Vision (3DV). IEEE, 106?115.
31. Tomer Weiss, Alan Litteneker, Noah Duncan, Masaki Nakada, Chenfanfu Jiang, Lap-Fai Yu, and Demetri Terzopoulos. 2019. Fast and Scalable Position-Based Layout Synthesis. IEEE Transactions on Visualization and Computer Graphics 25, 12 (2019), 3231?3243. https://doi.org/10.1109/TVCG.2018.2866436
32. Lap-Fai Yu, Sai-Kit Yeung, Chi-Keung Tang, Demetri Terzopoulos, Tony?F. Chan, and Stanley?J. Osher. 2011. Make It Home: Automatic Optimization of Furniture Arrangement. ACM Trans. Graph. 30, 4, Article 86 (Jul 2011), 12?pages. https://doi.org/10.1145/2010324.1964981
33. Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Ruslan?R Salakhutdinov, and Alexander?J Smola. 2017. Deep Sets. In Advances in Neural Information Processing Systems 30, I.?Guyon, U.?V. Luxburg, S.?Bengio, H.?Wallach, R.?Fergus, S.?Vishwanathan, and R.?Garnett (Eds.). Curran Associates, Inc., 3391?3401. http://papers.nips.cc/paper/6931-deep-sets.pdf