
“Carnival: a modular framework for automated facial animation” by Berger, Hofer and Shimodaira
Conference:
Type(s):
Title:
- Carnival: a modular framework for automated facial animation
Presenter(s)/Author(s):
Entry Number:
- 5
Abstract:
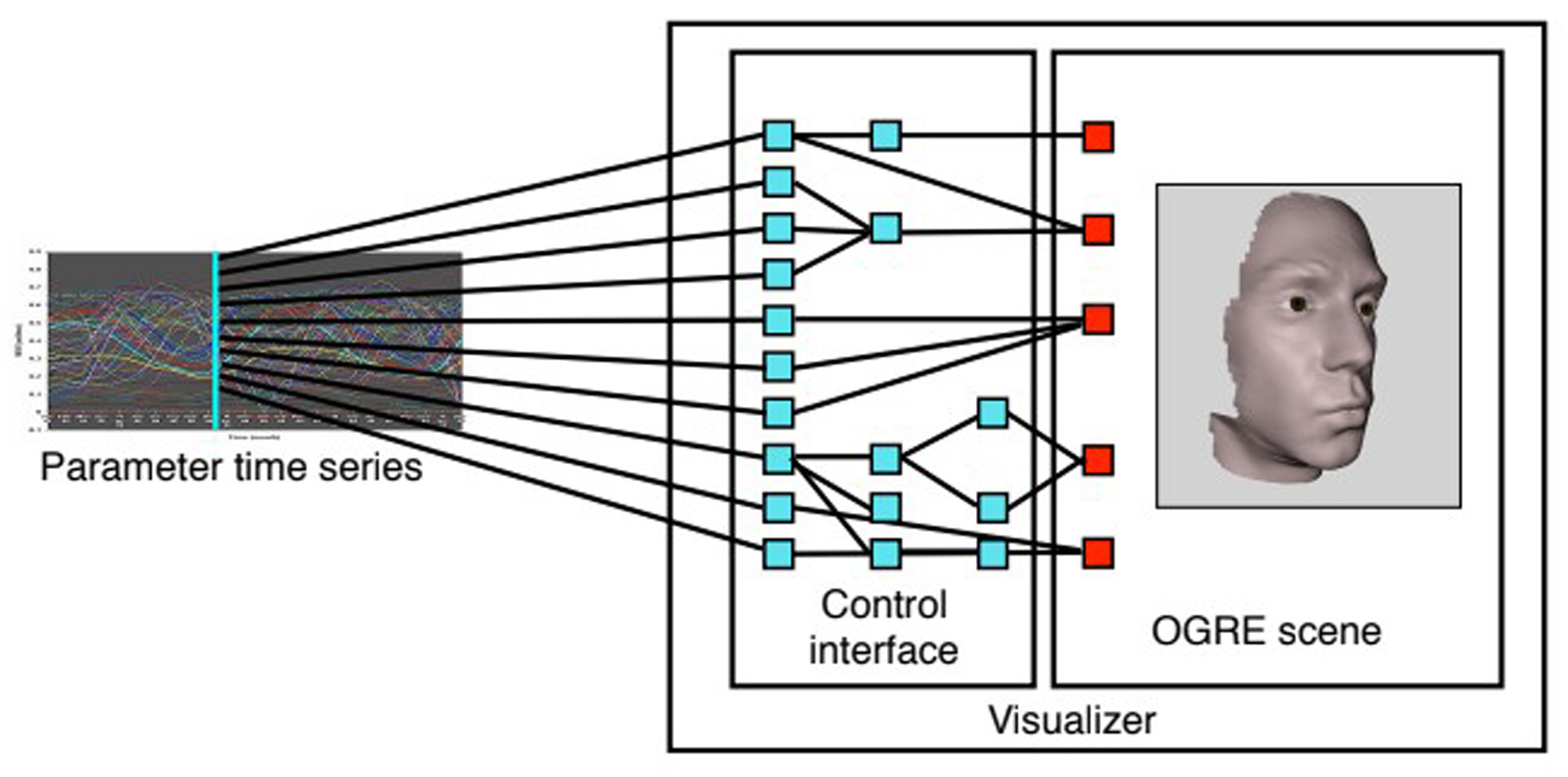
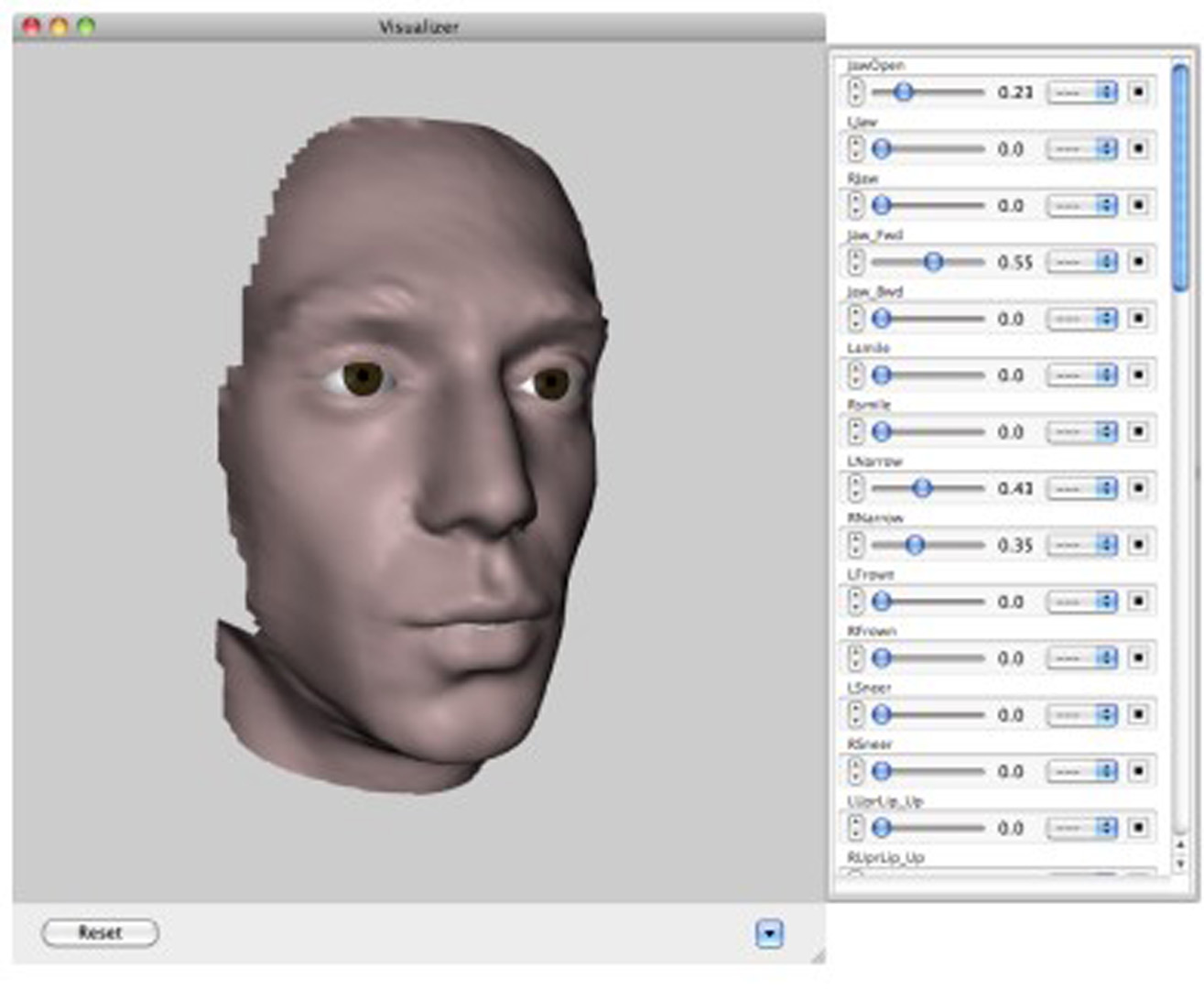
Facial animation is difficult to do convincingly. The movements of the face are complex and subtle, and we are innately attuned to faces. It is particularly difficult and labor-intensive to accurately synchronize faces with speech. A technology-based solution to this problem is automated facial animation. There are various ways to automate facial animation, each of which drives a face from some input sequence. In performance-driven animation, the input sequence may be either facial motion capture or video of a face. In automatic lip-syncing, the input is audio (and possibly a text transcript), resulting in facial animation synchronized with that audio. In audio-visual text-to-speech synthesis (AVTTS), only text is input, and synchronous auditory and visual speech are synthesized.
References:
Streeting, S., 2010. Ogre: Object-oriented graphics rendering engine. http:://www.ogre3d.org.Google Scholar