
“An algorithm for extracting text strings from comic strips” by Guo, Kato, Sato and Hoshino
Conference:
Type(s):
Title:
- An algorithm for extracting text strings from comic strips
Presenter(s)/Author(s):
Abstract:
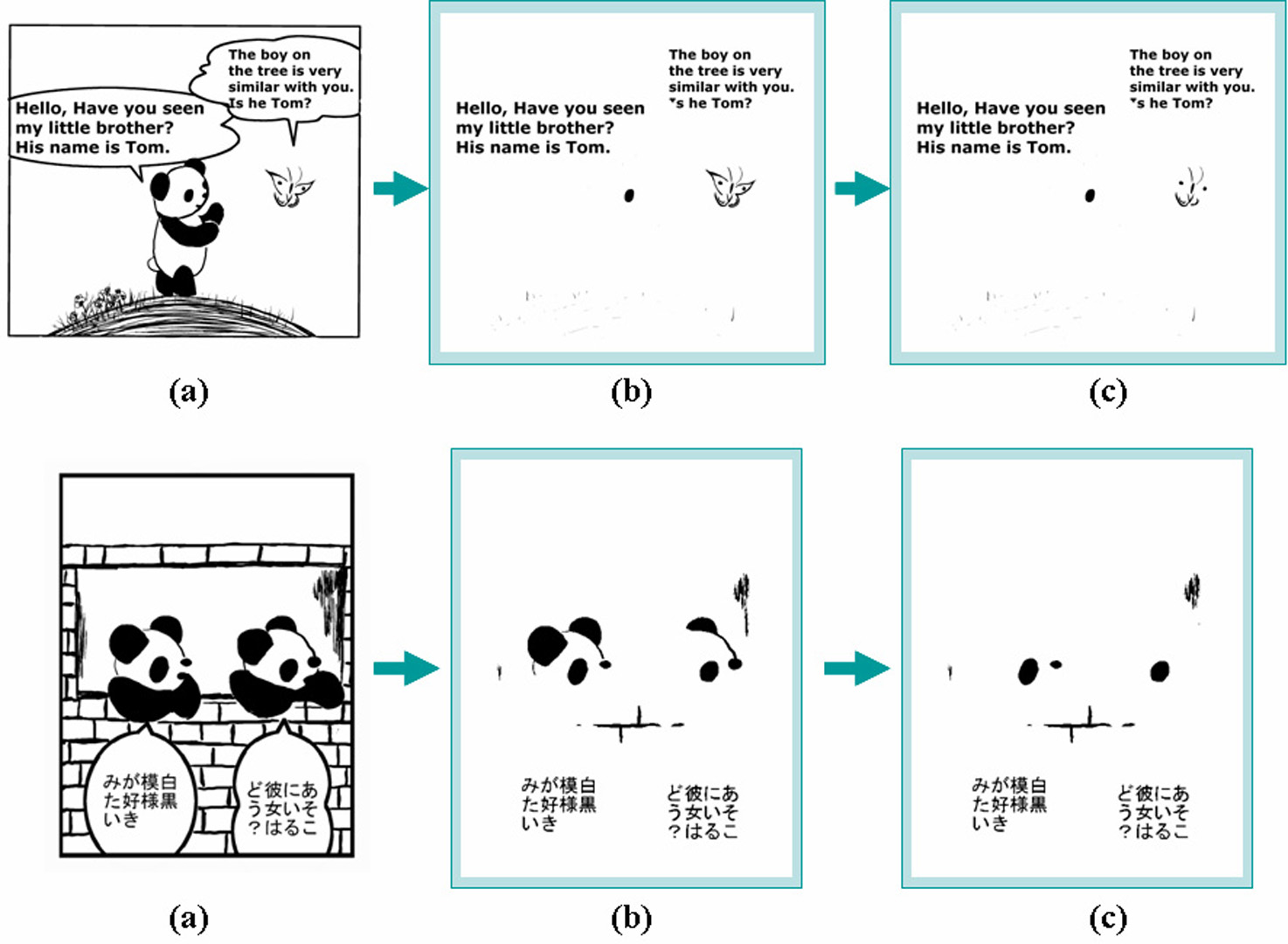
In recent years it becomes possible to download comic strips and read them on cell phones. Japanese companies such as SONY have started to deliver digitalized comic strips to cell phone users. The market is attractive and promising since cartoons are popular in Japan across generations, while there are plenty of the well-drawn/well-written classical comic strips. Using a cell phone today, it is possible to store a hundred of comic books and display their images one after another in screen like a slid show. For providing the users with more satisfactory service, however, there are still technical problems to be solved. A major problem is the small screen size, which is limited to 2~2.4 inches (320×480 pixels), for the conveneince of portabilities. When a panel of comic strips is displayed on the screen, its text strings are usually too small to recognize. Reading the text strings in voice is a desirable solution to solve the small screen problem, and doing this automatically is a pioneering work.
References:
1. H. Bunke and P. S. P. Wang (eds.), Handbook of Character Recognition and Document Image Analysis, Singapole: World Scientific, 1997.