
“Write-a-video: computational video montage from themed text” by Wang, Yang, Hu, Yau and Shamir
Conference:
Type(s):
Title:
- Write-a-video: computational video montage from themed text
Session/Category Title:
- Learning from Video
Presenter(s)/Author(s):
Moderator(s):
Abstract:
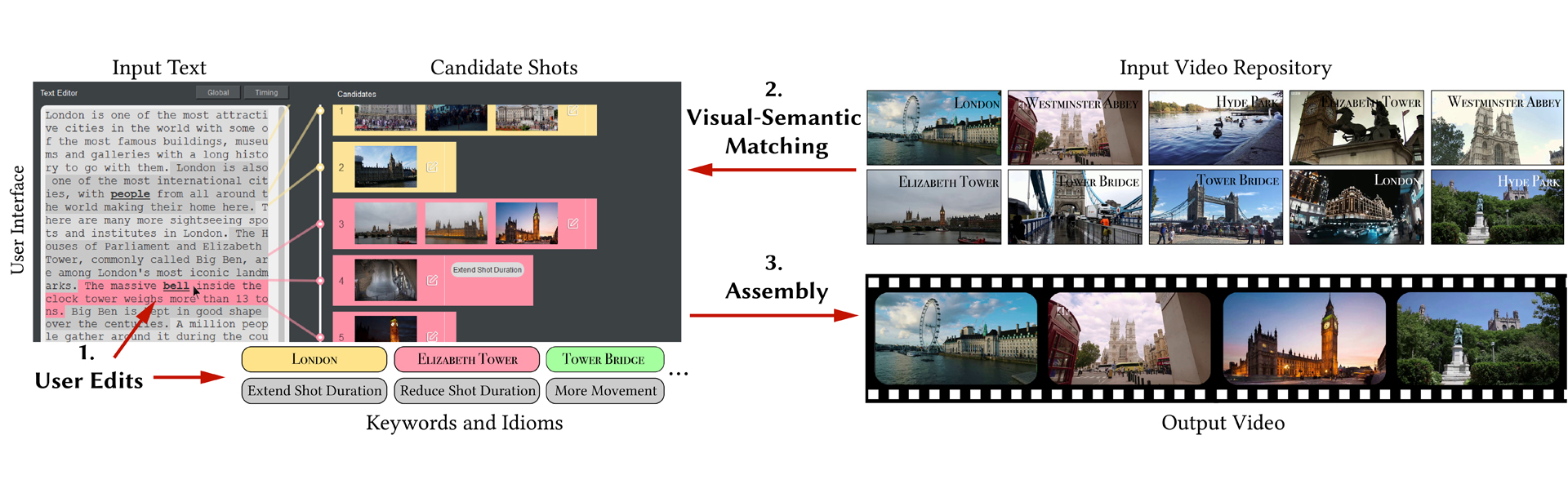
We present Write-A-Video, a tool for the creation of video montage using mostly text-editing. Given an input themed text and a related video repository either from online websites or personal albums, the tool allows novice users to generate a video montage much more easily than current video editing tools. The resulting video illustrates the given narrative, provides diverse visual content, and follows cinematographic guidelines. The process involves three simple steps: (1) the user provides input, mostly in the form of editing the text, (2) the tool automatically searches for semantically matching candidate shots from the video repository, and (3) an optimization method assembles the video montage. Visual-semantic matching between segmented text and shots is performed by cascaded keyword matching and visual-semantic embedding, that have better accuracy than alternative solutions. The video assembly is formulated as a hybrid optimization problem over a graph of shots, considering temporal constraints, cinematography metrics such as camera movement and tone, and user-specified cinematography idioms. Using our system, users without video editing experience are able to generate appealing videos.
References:
1. Ido Arev, Hyun Soo Park, Yaser Sheikh, Jessica Hodgins, and Ariel Shamir. 2014. Automatic editing of footage from multiple social cameras. ACM Trans. Graph. 33, 4 (2014), 81.Google ScholarDigital Library
2. Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. 2006. SURF: Speeded Up Robust Features. 404–417.Google Scholar
3. Rachele Bellini, Yanir Kleiman, and Daniel Cohen-Or. 2018. Dance to the beat: Synchronizing motion to audio. Computational Visual Media 4, 3 (2018), 197–208.Google ScholarCross Ref
4. Floraine Berthouzoz, Wilmot Li, and Maneesh Agrawala. 2012. Tools for Placing Cuts and Transitions in Interview Video. ACM Trans. Graph. 31, 4 (2012), 67:1–67:8.Google ScholarDigital Library
5. Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. 2015. ActivityNet: A Large-Scale Video Benchmark for Human Activity Understanding. In IEEE CVPR.Google Scholar
6. Minsuk Chang, Anh Truong, Oliver Wang, Maneesh Agrawala, and Juho Kim. 2019. How to Design Voice Based Navigation for How-To Videos. In ACM CHI. Article 701, 701:1–701:11 pages.Google Scholar
7. Pei-Yu Chi, Joyce Liu, Jason Linder, Mira Dontcheva, Wilmot Li, and Bjoern Hartmann. 2013. Democut: generating concise instructional videos for physical demonstrations. In ACM UIST. 141–150.Google Scholar
8. Chung-Cheng Chiu, Tara N Sainath, Yonghui Wu, Rohit Prabhavalkar, Patrick Nguyen, Zhifeng Chen, Anjuli Kannan, Ron J Weiss, Kanishka Rao, Ekaterina Gonina, et al. 2018. State-of-the-art speech recognition with sequence-to-sequence models. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 4774–4778.Google ScholarCross Ref
9. W. S. Chu, Yale Song, and A. Jaimes. 2015. Video co-summarization: Video summarization by visual co-occurrence. In IEEE CVPR. 3584–3592.Google Scholar
10. Abe Davis and Maneesh Agrawala. 2018. Visual Rhythm and Beat. ACM Trans. Graph. 37, 4, Article 122 (2018).Google ScholarDigital Library
11. Edward Dmytryk. 1984. On Film Editing: An Introduction to the Art of Film Construction. Focal Press.Google Scholar
12. David K Elson and Mark O Riedl. 2007. A Lightweight Intelligent Virtual Cinematography System for Machinima Production. (2007).Google Scholar
13. Fartash Faghri, David J Fleet, Jamie Ryan Kiros, and Sanja Fidler. 2018. VSE++: Improving Visual-Semantic Embeddings with Hard Negatives. In BMVC.Google Scholar
14. Martin A. Fischler and Robert C. Bolles. 1981. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 24, 6 (1981), 381–395.Google ScholarDigital Library
15. Quentin Galvane, Rémi Ronfard, Christophe Lino, and Marc Christie. 2015. Continuity Editing for 3D Animation. In AAAI. 753–762.Google Scholar
16. Andreas Girgensohn, John Boreczky, Patrick Chiu, John Doherty, Jonathan Foote, Gene Golovchinsky, Shingo Uchihashi, and Lynn Wilcox. 2000. A Semi-automatic Approach to Home Video Editing. In ACM UIST. 81–89.Google Scholar
17. Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. 2017. Mask r-cnn. In IEEE ICCV. 2980–2988.Google Scholar
18. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In IEEE CVPR. 770–778.Google Scholar
19. Rachel Heck, Michael Wallick, and Michael Gleicher. 2007. Virtual videography. ACM Trans. Multimedia Comput. Commun. Appl. 3, 1 (2007), 4.Google ScholarDigital Library
20. Weiming Hu, Nianhua Xie, Li Li, Xianglin Zeng, and Stephen Maybank. 2011. A survey on visual content-based video indexing and retrieval. IEEE Trans. Syst., Man, Cybern. C 41, 6 (2011), 797–819.Google ScholarDigital Library
21. Haozhi Huang, Xiaonan Fang, Yufei Ye, Songhai Zhang, and Paul L. Rosin. 2017. Practical automatic background substitution for live video. Computational Visual Media 3, 3 (2017), 273–284.Google ScholarCross Ref
22. Eakta Jain, Yaser Sheikh, Ariel Shamir, and Jessica Hodgins. 2015. Gaze-Driven Video Re-Editing. ACM Trans. Graph. 34, 2, Article 21 (2015), 12 pages.Google ScholarDigital Library
23. Neel Joshi, Wolf Kienzle, Mike Toelle, Matt Uyttendaele, and Michael F. Cohen. 2015. Real-time Hyperlapse Creation via Optimal Frame Selection. ACM Trans. Graph. 34, 4 (2015), 63:1–63:9.Google ScholarDigital Library
24. Andrej Karpathy and Li Fei-Fei. 2015. Deep visual-semantic alignments for generating image descriptions. In IEEE CVPR. 3128–3137.Google Scholar
25. G. Kim, L. Sigal, and E. P. Xing. 2014. Joint Summarization of Large-Scale Collections of Web Images and Videos for Storyline Reconstruction. In IEEE CVPR. 4225–4232.Google Scholar
26. Mackenzie Leake, Abe Davis, Anh Truong, and Maneesh Agrawala. 2017. Computational Video Editing for Dialogue-driven Scenes. ACM Trans. Graph. 36, 4 (2017), 130:1–130:14.Google ScholarDigital Library
27. Zicheng Liao, Yizhou Yu, Bingchen Gong, and Lechao Cheng. 2015. Audeosynth: Music-driven Video Montage. ACM Trans. Graph. 34, 4, Article 68 (2015).Google ScholarDigital Library
28. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In IEEE ECCV. 740–755.Google Scholar
29. Shugao Ma, Leonid Sigal, and Stan Sclaroff. 2016. Learning Activity Progression in LSTMs for Activity Detection and Early Detection. In IEEE CVPR.Google Scholar
30. Erik Machnicki and Lawrence A Rowe. 2001. Virtual director: Automating a webcast. In Multimedia Computing and Networking 2002, Vol. 4673. 208–226.Google Scholar
31. Antoine Miech, Ivan Laptev, and Josef Sivic. 2018. Learning a text-video embedding from incomplete and heterogeneous data. arXiv preprint arXiv:1804.02516 (2018).Google Scholar
32. M. Ramesh Naphade, I. V. Kozintsev, and T. S. Huang. 2002. Factor graph framework for semantic video indexing. IEEE Trans. Circuits Syst. Video Technol. 12, 1 (2002), 40–52.Google ScholarDigital Library
33. Yuzhen Niu and Feng Liu. 2012. What makes a professional video? a computational aesthetics approach. IEEE Trans. Circuits Syst. Video Technol. 22, 7 (2012), 1037–1049.Google ScholarDigital Library
34. Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 (2016).Google Scholar
35. Amy Pavel, Dan B Goldman, Björn Hartmann, and Maneesh Agrawala. 2015. Sceneskim: Searching and browsing movies using synchronized captions, scripts and plot summaries. In ACM UIST. 181–190.Google ScholarDigital Library
36. Amy Pavel, Colorado Reed, Björn Hartmann, and Maneesh Agrawala. 2014. Video Digests: A Browsable, Skimmable Format for Informational Lecture Videos. In ACM UIST (UIST ’14). 573–582.Google Scholar
37. Ana Serrano, Vincent Sitzmann, Jaime Ruiz-Borau, Gordon Wetzstein, Diego Gutierrez, and Belen Masia. 2017. Movie Editing and Cognitive Event Segmentation in Virtual Reality Video. ACM Trans. Graph. 36, 4, Article 47 (2017), 12 pages.Google ScholarDigital Library
38. Hijung Valentina Shin, Floraine Berthouzoz, Wilmot Li, and Frédo Durand. 2015. Visual transcripts: lecture notes from blackboard-style lecture videos. ACM Trans. Graph. 34, 6 (2015), 240.Google ScholarDigital Library
39. S. W. Smoliar and HongJiang Zhang. 1994. Content based video indexing and retrieval. IEEE MultiMedia 1, 2 (1994), 62–72.Google ScholarDigital Library
40. James Tompkin, Kwang In Kim, Jan Kautz, and Christian Theobalt. 2012. Videoscapes: Exploring Sparse, Unstructured Video Collections. ACM Trans. Graph. 31, 4, Article 68 (2012), 12 pages.Google Scholar
41. Anh Truong, Floraine Berthouzoz, Wilmot Li, and Maneesh Agrawala. 2016. QuickCut: An Interactive Tool for Editing Narrated Video. In ACM UIST. 497–507.Google Scholar
42. M. Wang, J. Liang, S. Zhang, S. Lu, A. Shamir, and S. Hu. 2018. Hyper-Lapse From Multiple Spatially-Overlapping Videos. IEEE Transactions on Image Processing 27, 4 (2018), 1735–1747.Google ScholarDigital Library
43. M. Wang, G. Yang, J. Lin, S. Zhang, A. Shamir, S. Lu, and S. Hu. 2019. Deep Online Video Stabilization With Multi-Grid Warping Transformation Learning. IEEE Transactions on Image Processing 28, 5 (2019), 2283–2292.Google ScholarCross Ref
44. Ke Xie, Hao Yang, Shengqiu Huang, Dani Lischinski, Marc Christie, Kai Xu, Minglun Gong, Daniel Cohen-Or, and Hui Huang. 2018. Creating and Chaining Camera Moves for Qadrotor Videography. ACM Trans. Graph. 37, 4 (2018), 88:1–88:13.Google ScholarDigital Library
45. Hao Yang, Ke Xie, Shengqiu Huang, and Hui Huang. 2018. Uncut Aerial Video via a Single Sketch. Computer Graphics Forum 37, 7 (2018), 191–199.Google ScholarCross Ref
46. F. Zhang, J. Wang, H. Zhao, R. R. Martin, and S. Hu. 2015. Simultaneous Camera Path Optimization and Distraction Removal for Improving Amateur Video. IEEE Transactions on Image Processing 24, 12 (2015), 5982–5994.Google ScholarDigital Library
47. F. Zhang, X. Wu, R. Li, J. Wang, Z. Zheng, and S. Hu. 2018. Detecting and Removing Visual Distractors for Video Aesthetic Enhancement. IEEE Transactions on Multimedia 20, 8 (2018), 1987–1999.Google ScholarCross Ref
48. Yu Zhang, Xiaowu Chen, Liang Lin, Changqun Xia, and Dongqing Zou. 2016. High-level representation sketch for video event retrieval. Science China Information Sciences 59, 7 (2016), 072103.Google ScholarCross Ref