
“VRMM: A Volumetric Relightable Morphable Head Model”
Conference:
Type(s):
Title:
- VRMM: A Volumetric Relightable Morphable Head Model
Presenter(s)/Author(s):
Abstract:
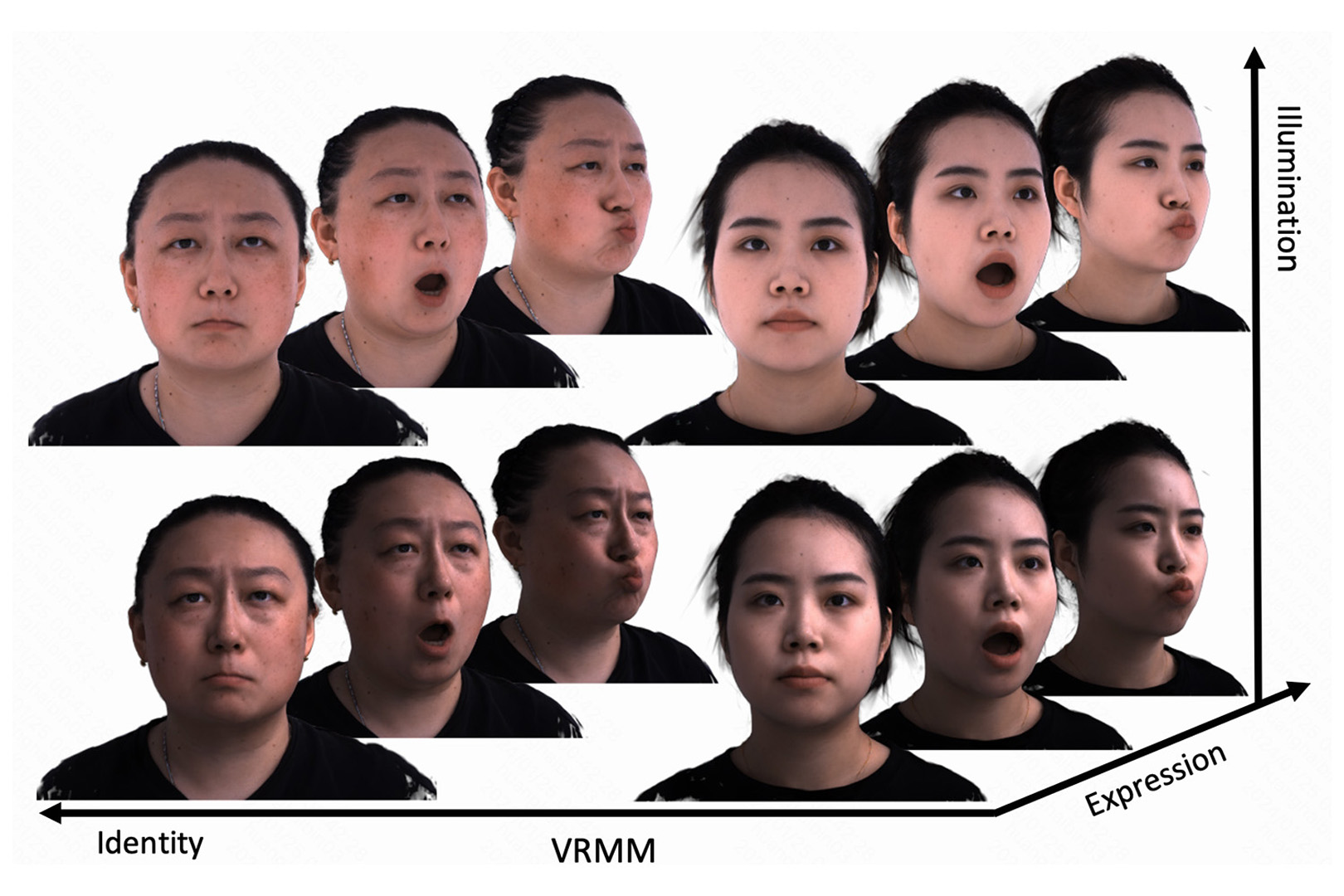
We present the Volumetric Relightable Morphable Model (VRMM), a novel volumetric and parametric facial prior. Our VRMM utilizes a novel training framework to efficiently disentangle and encode identity, expression, and lighting into low-dimensional representations. It facilitates the reconstruction of high-quality, animatable, and relightable volumetric avatars from few-shot captures.
References:
[1]
Rameen Abdal, Yipeng Qin, and Peter Wonka. 2019. Image2stylegan: How to embed images into the stylegan latent space?. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4432?4441.
[2]
Timur Bagautdinov, Chenglei Wu, Jason Saragih, Pascal Fua, and Yaser Sheikh. 2018. Modeling facial geometry using compositional vaes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3877?3886.
[3]
Thabo Beeler, Bernd Bickel, Paul Beardsley, Bob Sumner, and Markus Gross. 2010. High-quality single-shot capture of facial geometry. In ACM SIGGRAPH 2010 papers. 1?9.
[4]
Thabo Beeler, Fabian Hahn, Derek Bradley, Bernd Bickel, Paul Beardsley, Craig Gotsman, Robert W Sumner, and Markus Gross. 2011. High-quality passive facial performance capture using anchor frames. In ACM SIGGRAPH 2011 papers. 1?10.
[5]
Sai Bi, Stephen Lombardi, Shunsuke Saito, Tomas Simon, Shih-En Wei, Kevyn Mcphail, Ravi Ramamoorthi, Yaser Sheikh, and Jason Saragih. 2021. Deep relightable appearance models for animatable faces. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1?15.
[6]
Volker Blanz and Thomas Vetter. 1999. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques. 187?194.
[7]
James Booth, Anastasios Roussos, Stefanos Zafeiriou, Allan Ponniah, and David Dunaway. 2016. A 3d morphable model learnt from 10,000 faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5543?5552.
[8]
Derek Bradley, Wolfgang Heidrich, Tiberiu Popa, and Alla Sheffer. 2010. High resolution passive facial performance capture. In ACM SIGGRAPH 2010 papers. 1?10.
[9]
Marcel C B?hler, Kripasindhu Sarkar, Tanmay Shah, Gengyan Li, Daoye Wang, Leonhard Helminger, Sergio Orts-Escolano, Dmitry Lagun, Otmar Hilliges, Thabo Beeler, 2023. Preface: A data-driven volumetric prior for few-shot ultra high-resolution face synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3402?3413.
[10]
Chen Cao, Tomas Simon, Jin Kyu Kim, Gabe Schwartz, Michael Zollhoefer, Shun-Suke Saito, Stephen Lombardi, Shih-En Wei, Danielle Belko, Shoou-I Yu, 2022. Authentic volumetric avatars from a phone scan. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1?19.
[11]
Chen Cao, Yanlin Weng, Shun Zhou, Yiying Tong, and Kun Zhou. 2013. Facewarehouse: A 3D facial expression database for visual computing. IEEE Transactions on Visualization and Computer Graphics 20, 3 (2013), 413?425.
[12]
Pol Caselles, Eduard Ramon, Jaime Garcia, Xavier Giro-i Nieto, Francesc Moreno-Noguer, and Gil Triginer. 2023. Sira: Relightable avatars from a single image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 775?784.
[13]
Zhaoxi Chen and Ziwei Liu. 2022. Relighting4d: Neural relightable human from videos. In European Conference on Computer Vision. Springer, 606?623.
[14]
Alvaro Collet, Ming Chuang, Pat Sweeney, Don Gillett, Dennis Evseev, David Calabrese, Hugues Hoppe, Adam Kirk, and Steve Sullivan. 2015. High-quality streamable free-viewpoint video. ACM Transactions on Graphics (TOG) 34, 4 (2015), 1?13.
[15]
Paul Debevec, Tim Hawkins, Chris Tchou, Haarm-Pieter Duiker, Westley Sarokin, and Mark Sagar. 2000. Acquiring the reflectance field of a human face. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques. 145?156.
[16]
Mingsong Dou, Philip Davidson, Sean Ryan Fanello, Sameh Khamis, Adarsh Kowdle, Christoph Rhemann, Vladimir Tankovich, and Shahram Izadi. 2017a. Motion2fusion: Real-time volumetric performance capture. ACM Transactions on Graphics (TOG) 36, 6 (2017), 1?16.
[17]
Pengfei Dou, Shishir K Shah, and Ioannis A Kakadiaris. 2017b. End-to-end 3D face reconstruction with deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5908?5917.
[18]
Graham Fyffe and Paul Debevec. 2015. Single-shot reflectance measurement from polarized color gradient illumination. In 2015 IEEE International Conference on Computational Photography (ICCP). IEEE, 1?10.
[19]
Xuan Gao, Chenglai Zhong, Jun Xiang, Yang Hong, Yudong Guo, and Juyong Zhang. 2022. Reconstructing personalized semantic facial nerf models from monocular video. ACM Transactions on Graphics (TOG) 41, 6 (2022), 1?12.
[20]
Abhijeet Ghosh, Graham Fyffe, Borom Tunwattanapong, Jay Busch, Xueming Yu, and Paul Debevec. 2011. Multiview face capture using polarized spherical gradient illumination. ACM Transactions on Graphics (TOG) 30, 6 (2011), 1?10.
[21]
Kaiwen Guo, Peter Lincoln, Philip Davidson, Jay Busch, Xueming Yu, Matt Whalen, Geoff Harvey, Sergio Orts-Escolano, Rohit Pandey, Jason Dourgarian, 2019. The relightables: Volumetric performance capture of humans with realistic relighting. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1?19.
[22]
Yang Hong, Bo Peng, Haiyao Xiao, Ligang Liu, and Juyong Zhang. 2022. Headnerf: A real-time nerf-based parametric head model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20374?20384.
[23]
Haoda Huang, Jinxiang Chai, Xin Tong, and Hsiang-Tao Wu. 2011. Leveraging motion capture and 3D scanning for high-fidelity facial performance acquisition. In ACM SIGGRAPH 2011 papers. 1?10.
[24]
Zi-Hang Jiang, Qianyi Wu, Keyu Chen, and Juyong Zhang. 2019. Disentangled representation learning for 3D face shape. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 11957?11966.
[25]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4401?4410.
[26]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk?hler, and George Drettakis. 2023. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics 42, 4 (2023).
[27]
Alexandros Lattas, Stylianos Moschoglou, Baris Gecer, Stylianos Ploumpis, Vasileios Triantafyllou, Abhijeet Ghosh, and Stefanos Zafeiriou. 2020. AvatarMe: Realistically Renderable 3D Facial Reconstruction” in-the-wild”. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 760?769.
[28]
Alexandros Lattas, Stylianos Moschoglou, Stylianos Ploumpis, Baris Gecer, Abhijeet Ghosh, and Stefanos Zafeiriou. 2021. Avatarme++: Facial shape and brdf inference with photorealistic rendering-aware gans. IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 12 (2021), 9269?9284.
[29]
Gengyan Li, Abhimitra Meka, Franziska Mueller, Marcel C Buehler, Otmar Hilliges, and Thabo Beeler. 2022. EyeNeRF: a hybrid representation for photorealistic synthesis, animation and relighting of human eyes. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1?16.
[30]
Jiaman Li, Zhengfei Kuang, Yajie Zhao, Mingming He, Karl Bladin, and Hao Li. 2020b. Dynamic facial asset and rig generation from a single scan.ACM Trans. Graph. 39, 6 (2020), 215?1.
[31]
Ruilong Li, Karl Bladin, Yajie Zhao, Chinmay Chinara, Owen Ingraham, Pengda Xiang, Xinglei Ren, Pratusha Prasad, Bipin Kishore, Jun Xing, 2020a. Learning formation of physically-based face attributes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3410?3419.
[32]
Tianye Li, Timo Bolkart, Michael J Black, Hao Li, and Javier Romero. 2017. Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics (TOG) 36, 6 (2017), 194:1?194:17.
[33]
Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. 2019. Neural volumes: learning dynamic renderable volumes from images. ACM Transactions on Graphics (TOG) 38, 4 (2019), 1?14.
[34]
Stephen Lombardi, Tomas Simon, Gabriel Schwartz, Michael Zollhoefer, Yaser Sheikh, and Jason Saragih. 2021. Mixture of volumetric primitives for efficient neural rendering. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1?13.
[35]
Shugao Ma, Tomas Simon, Jason Saragih, Dawei Wang, Yuecheng Li, Fernando De La Torre, and Yaser Sheikh. 2021. Pixel codec avatars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 64?73.
[36]
Wan-Chun Ma, Tim Hawkins, Pieter Peers, Charles-Felix Chabert, Malte Weiss, Paul E Debevec, 2007. Rapid Acquisition of Specular and Diffuse Normal Maps from Polarized Spherical Gradient Illumination.Rendering Techniques 2007, 9 (2007), 10.
[37]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In European Conference on Computer Vision. 405?421.
[38]
Thomas M?ller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG) 41, 4 (2022), 1?15.
[39]
Foivos Paraperas Papantoniou, Alexandros Lattas, Stylianos Moschoglou, and Stefanos Zafeiriou. 2023. Relightify: Relightable 3D Faces from a Single Image via Diffusion Models. 2023 IEEE/CVF International Conference on Computer Vision (2023), 8772?8783. https://api.semanticscholar.org/CorpusID:258588229
[40]
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. 2019. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 165?174.
[41]
Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami Romdhani, and Thomas Vetter. 2009. A 3D face model for pose and illumination invariant face recognition. In 2009 sixth IEEE International Conference on Advanced Video and Signal Based Surveillance. Ieee, 296?301.
[42]
Stylianos Ploumpis, Evangelos Ververas, Eimear O?Sullivan, Stylianos Moschoglou, Haoyang Wang, Nick Pears, William AP Smith, Baris Gecer, and Stefanos Zafeiriou. 2020. Towards a complete 3D morphable model of the human head. IEEE Transactions on Pattern Analysis and Machine Intelligence 43, 11 (2020), 4142?4160.
[43]
J?r?my Riviere, Paulo Gotardo, Derek Bradley, Abhijeet Ghosh, and Thabo Beeler. 2020. Single-shot high-quality facial geometry and skin appearance capture. ACM Transactions on Graphics (TOG) 39, 4 (2020), 1?12.
[44]
Daniel Roich, Ron Mokady, Amit H Bermano, and Daniel Cohen-Or. 2022. Pivotal tuning for latent-based editing of real images. ACM Transactions on graphics (TOG) 42, 1 (2022), 1?13.
[45]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22500?22510.
[46]
Christophe Schlick. 1994. An inexpensive BRDF model for physically-based rendering. In Computer graphics forum. 233?246.
[47]
Gabriel Schwartz, Shih-En Wei, Te-Li Wang, Stephen Lombardi, Tomas Simon, Jason Saragih, and Yaser Sheikh. 2020. The eyes have it: An integrated eye and face model for photorealistic facial animation. ACM Transactions on Graphics (TOG) 39, 4 (2020), 91:1?91:15.
[48]
Ayush Tewari, Mohamed Elgharib, Gaurav Bharaj, Florian Bernard, Hans-Peter Seidel, Patrick P?rez, Michael Zollhofer, and Christian Theobalt. 2020. Stylerig: Rigging stylegan for 3d control over portrait images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6142?6151.
[49]
Ayush Tewari, Michael Zollhofer, Hyeongwoo Kim, Pablo Garrido, Florian Bernard, Patrick Perez, and Christian Theobalt. 2017. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In Proceedings of the IEEE International Conference on Computer Vision Workshops. 1274?1283.
[50]
Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Nie?ner. 2016. Face2face: Real-time face capture and reenactment of RGB videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2387?2395.
[51]
Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. 2021. Designing an encoder for stylegan image manipulation. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1?14.
[52]
Luan Tran and Xiaoming Liu. 2018. Nonlinear 3D face morphable model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7346?7355.
[53]
Luan Tran and Xiaoming Liu. 2019. On learning 3D face morphable model from in-the-wild images. IEEE Transactions on Pattern Analysis and Machine Intelligence 43, 1 (2019), 157?171.
[54]
Daniel Vlasic, Matthew Brand, Hanspeter Pfister, and Jovan Popovi?. 2005. Face Transfer with Multilinear Models. ACM Transactions on Graphics (TOG) 24, 3 (2005), 426?433.
[55]
Daoye Wang, Prashanth Chandran, Gaspard Zoss, Derek Bradley, and Paulo Gotardo. 2022. Morf: Morphable radiance fields for multiview neural head modeling. In ACM SIGGRAPH 2022 Conference Proceedings. 1?9.
[56]
Cheng-hsin Wuu, Ningyuan Zheng, Scott Ardisson, Rohan Bali, Danielle Belko, Eric Brockmeyer, Lucas Evans, Timothy Godisart, Hyowon Ha, Alexander Hypes, Taylor Koska, Steven Krenn, Stephen Lombardi, Xiaomin Luo, Kevyn McPhail, Laura Millerschoen, Michal Perdoch, Mark Pitts, Alexander Richard, Jason Saragih, Junko Saragih, Takaaki Shiratori, Tomas Simon, Matt Stewart, Autumn Trimble, Xinshuo Weng, David Whitewolf, Chenglei Wu, Shoou-I Yu, and Yaser Sheikh. 2022. Multiface: A Dataset for Neural Face Rendering. arXiv preprint arXiv:2207.11243 (2022).
[57]
Yuelang Xu, Hongwen Zhang, Lizhen Wang, Xiaochen Zhao, Han Huang, Guojun Qi, and Yebin Liu. 2023. Latentavatar: Learning latent expression code for expressive neural head avatar. In ACM SIGGRAPH 2023 Conference Proceedings. 1?10.
[58]
Shugo Yamaguchi, Shunsuke Saito, Koki Nagano, Yajie Zhao, Weikai Chen, Kyle Olszewski, Shigeo Morishima, and Hao Li. 2018. High-fidelity facial reflectance and geometry inference from an unconstrained image. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1?14.
[59]
Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, and Chongyang Ma. 2023. Towards Practical Capture of High-Fidelity Relightable Avatars. In SIGGRAPH Asia 2023 Conference Proceedings.
[60]
Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang, and Xun Cao. 2020. Facescape: a large-scale high quality 3D face dataset and detailed riggable 3D face prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 601?610.
[61]
Longwen Zhang, Chuxiao Zeng, Qixuan Zhang, Hongyang Lin, Ruixiang Cao, Wei Yang, Lan Xu, and Jingyi Yu. 2022. Video-driven neural physically-based facial asset for production. ACM Transactions on Graphics (TOG) 41, 6 (2022), 1?16.
[62]
Mingwu Zheng, Zhang Haiyu, Hongyu Yang, and Di Huang. 2023a. NeuFace: Realistic 3D Neural Face Rendering from Multi-view Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 16868?16877.
[63]
Mingwu Zheng, Hongyu Yang, Di Huang, and Liming Chen. 2022. ImFace: A Nonlinear 3D Morphable Face Model with Implicit Neural Representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 20343?20352.
[64]
Yufeng Zheng, Wang Yifan, Gordon Wetzstein, Michael J Black, and Otmar Hilliges. 2023b. Pointavatar: Deformable point-based head avatars from videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21057?21067.
[65]
Peihao Zhu, Rameen Abdal, Yipeng Qin, John Femiani, and Peter Wonka. 2020. Improved stylegan embedding: Where are the good latents?arXiv preprint arXiv:2012.09036 (2020).
[66]
Xiangyu Zhu, Xiaoming Liu, Zhen Lei, and Stan Z Li. 2017. Face alignment in full pose range: A 3D total solution. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 1 (2017), 78?92.
[67]
Yiyu Zhuang, Hao Zhu, Xusen Sun, and Xun Cao. 2022. Mofanerf: Morphable facial neural radiance field. In European Conference on Computer Vision. Springer, 268?285.
[68]
Wojciech Zielonka, Timo Bolkart, and Justus Thies. 2023. Instant volumetric head avatars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4574?4584.