
“Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion”
Conference:
Type(s):
Title:
- Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion
Presenter(s)/Author(s):
Abstract:
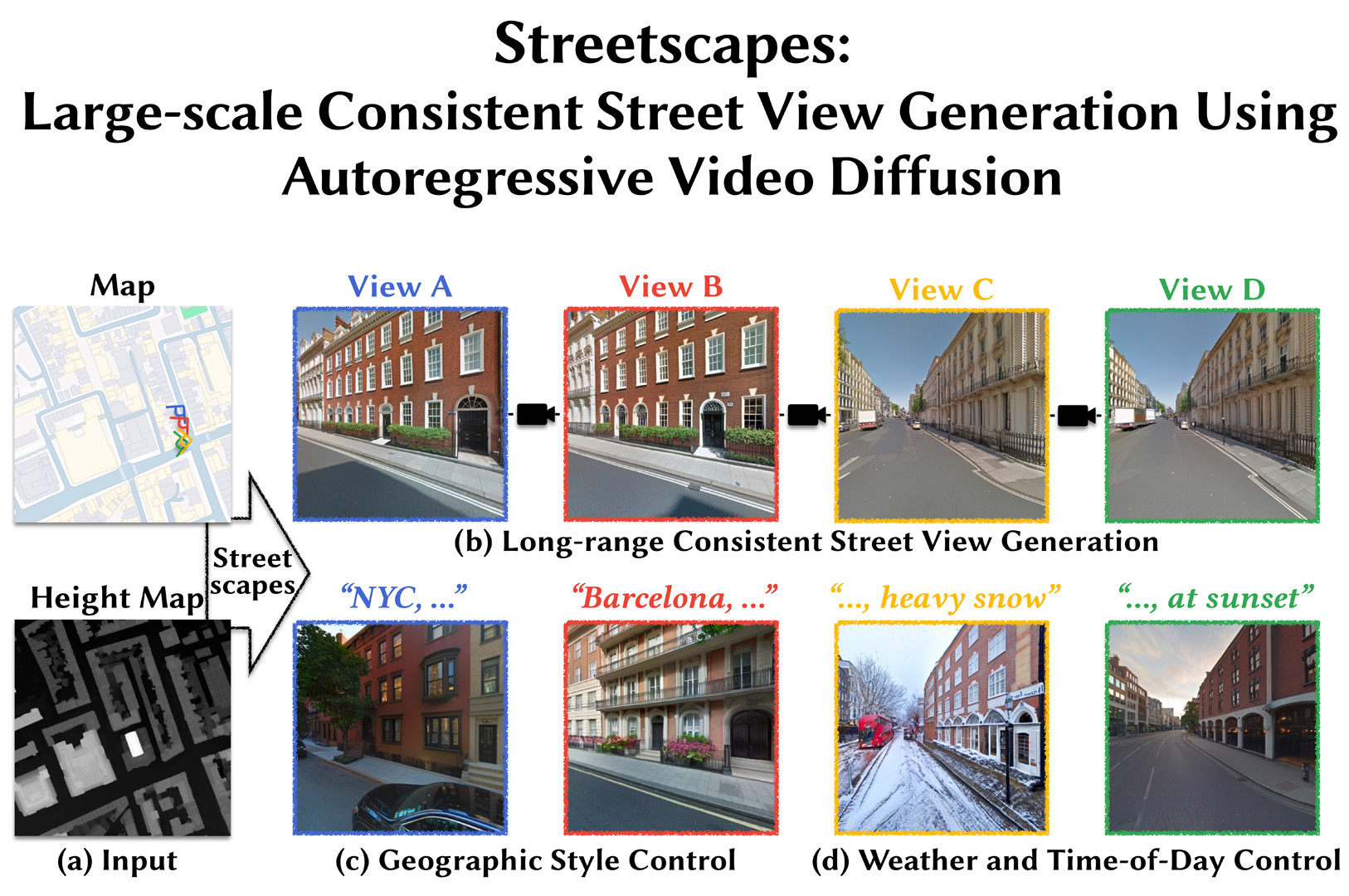
Our method generates Streetscapes ? long sequences of views through a synthesized city-scale scene. We build on video diffusion models, but in an autoregressive framework that easily scales to long camera trajectories. We train our system on the unique Google Street View data, allowing controlling generations by scene layouts and camera poses.
References:
[1]
Titas Anciukevi?ius, Zexiang Xu, Matthew Fisher, Paul Henderson, Hakan Bilen, Niloy J Mitra, and Paul Guerrero. 2023. Renderdiffusion: Image diffusion for 3d reconstruction, inpainting and generation. In Proc. Conference on Computer Vision and Pattern Recognition (CVPR).
[2]
Dragomir Anguelov, Carole Dulong, Daniel Filip, Christian Frueh, St?phane Lafon, Richard Lyon, Abhijit Ogale, Luc Vincent, and Josh Weaver. 2010. Google Street View: Capturing the World at Street Level. Computer 43 (2010). http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5481932&tag=1
[3]
Sherwin Bahmani, Jeong Joon Park, Despoina Paschalidou, Xingguang Yan, Gordon Wetzstein, Leonidas Guibas, and Andrea Tagliasacchi. 2023. CC3D: Layout-conditioned generation of compositional 3d scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision.
[4]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, 2023a. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023).
[5]
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 2023b. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22563?22575.
[6]
Shengqu Cai, Eric Ryan Chan, Songyou Peng, Mohamad Shahbazi, Anton Obukhov, Luc Van Gool, and Gordon Wetzstein. 2023. DiffDreamer: Towards Consistent Unsupervised Single-view Scene Extrapolation with Conditional Diffusion Models. In ICCV.
[7]
Lucy Chai, Richard Tucker, Zhengqi Li, Phillip Isola, and Noah Snavely. 2023. Persistent Nature: A Generative Model of Unbounded 3D Worlds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
[8]
Eric R Chan, Koki Nagano, Matthew A Chan, Alexander W Bergman, Jeong Joon Park, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, and Gordon Wetzstein. 2023. Generative novel view synthesis with 3d-aware diffusion models. Proc. International Conference on Computer Vision (ICCV) (2023).
[9]
Hansheng Chen, Jiatao Gu, Anpei Chen, Wei Tian, Zhuowen Tu, Lingjie Liu, and Hao Su. 2023b. Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction. arXiv preprint arXiv:2304.06714 (2023).
[10]
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. 2023a. Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
[11]
Jaeyoung Chung, Suyoung Lee, Hyeongjin Nam, Jaerin Lee, and Kyoung Mu Lee. 2023. LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes. arXiv preprint arXiv:2311.13384 (2023).
[12]
D. Cohen-Or, Y.L. Chrysanthou, C.T. Silva, and F. Durand. 2003. A survey of visibility for walkthrough applications. IEEE Transactions on Visualization and Computer Graphics 9, 3 (2003), 412?431. https://doi.org/10.1109/TVCG.2003.1207447
[13]
Michael Deering, Stephanie Winner, Bic Schediwy, Chris Duffy, and Neil Hunt. 1988. The triangle processor and normal vector shader: a VLSI system for high performance graphics. Acm siggraph computer graphics 22, 4 (1988), 21?30.
[14]
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl Vondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. 2023. Objaverse-XL: A Universe of 10M+ 3D Objects. arxiv:2307.05663 [cs.CV]
[15]
Carl Doersch, Saurabh Singh, Abhinav Gupta, Josef Sivic, and Alexei Efros. 2012. What makes paris look like paris?ACM Transactions on Graphics 31, 4 (2012).
[16]
Rafail Fridman, Amit Abecasis, Yoni Kasten, and Tali Dekel. 2023. SceneScape: Text-Driven Consistent Scene Generation. In NeurIPS.
[17]
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. 2023. Magicdrive: Street view generation with diverse 3d geometry control. arXiv preprint arXiv:2310.02601 (2023).
[18]
Jiatao Gu, Alex Trevithick, Kai-En Lin, Joshua M Susskind, Christian Theobalt, Lingjie Liu, and Ravi Ramamoorthi. 2023. Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion. In ICML.
[19]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Maneesh Agrawala, Dahua Lin, and Bo Dai. 2023a. SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models. arXiv preprint arXiv:2311.16933 (2023).
[20]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, and Bo Dai. 2023b. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023).
[21]
Anchit Gupta, Wenhan Xiong, Yixin Nie, Ian Jones, and Barlas O?uz. 2023. 3dgen: Triplane latent diffusion for textured mesh generation. arXiv preprint arXiv:2303.05371 (2023).
[22]
Zekun Hao, Arun Mallya, Serge Belongie, and Ming-Yu Liu. 2021. Gancraft: Unsupervised 3d neural rendering of minecraft worlds. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14072?14082.
[23]
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, 2022. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022).
[24]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. NIPS (2020).
[25]
Jonathan Ho and Tim Salimans. 2021. Classifier-Free Diffusion Guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications.
[26]
Lukas H?llein, Ang Cao, Andrew Owens, Justin Johnson, and Matthias Nie?ner. 2023. Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 7909?7920.
[27]
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. 2023. Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023).
[28]
Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, and Liefeng Bo. 2023. Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation. arXiv preprint arXiv:2311.17117 (2023).
[29]
Heewoo Jun and Alex Nichol. 2023. Shap-e: Generating conditional 3d implicit functions. arXiv preprint arXiv:2305.02463 (2023).
[30]
Animesh Karnewar, Andrea Vedaldi, David Novotny, and Niloy J Mitra. 2023. Holodiffusion: Training a 3D diffusion model using 2D images. In Proc. Conference on Computer Vision and Pattern Recognition (CVPR).
[31]
Zhengqi Li, Richard Tucker, Noah Snavely, and Aleksander Holynski. 2023. Generative image dynamics. arXiv preprint arXiv:2309.07906 (2023).
[32]
Zhengqi Li, Qianqian Wang, Noah Snavely, and Angjoo Kanazawa. 2022. InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images. In ECCV.
[33]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023a. Magic3D: High-Resolution Text-to-3D Content Creation. In Proc. Conference on Computer Vision and Pattern Recognition (CVPR). 300?309.
[34]
Chieh Hubert Lin, Hsin-Ying Lee, Willi Menapace, Menglei Chai, Aliaksandr Siarohin, Ming-Hsuan Yang, and Sergey Tulyakov. 2023b. Infinicity: Infinite-scale city synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision.
[35]
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. 2021. Infinite nature: Perpetual view generation of natural scenes from a single image. In Proc. International Conference on Computer Vision (ICCV). 14458?14467.
[36]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. 2023. Zero-1-to-3: Zero-shot one image to 3d object. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 9298?9309.
[37]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11461?11471.
[38]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. 2022. Point-e: A system for generating 3d point clouds from complex prompts. arXiv preprint arXiv:2212.08751 (2022).
[39]
Evangelos Ntavelis, Aliaksandr Siarohin, Kyle Olszewski, Chaoyang Wang, Luc Van Gool, and Sergey Tulyakov. 2023. AutoDecoding Latent 3D Diffusion Models. arXiv preprint arXiv:2307.05445 (2023).
[40]
Hao Ouyang, Tiancheng Sun, Stephen Lombardi, and Kathryn Heal. 2023. Text2Immersion: Generative Immersive Scene with 3D Gaussians. Arxiv (2023).
[41]
Ryan Po and Gordon Wetzstein. 2023. Compositional 3D Scene Generation using Locally Conditioned Diffusion. ArXiv abs/2303.12218 (2023). https://api.semanticscholar.org/CorpusID:257663283
[42]
Ryan Po, Wang Yifan, Vladislav Golyanik, Kfir Aberman, Jonathan T Barron, Amit H Bermano, Eric Ryan Chan, Tali Dekel, Aleksander Holynski, Angjoo Kanazawa, 2023. State of the art on diffusion models for visual computing. arXiv preprint arXiv:2310.07204 (2023).
[43]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2022. DreamFusion: Text-to-3D using 2D Diffusion. arXiv (2022).
[44]
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. 2023. Dreamfusion: Text-to-3d using 2d diffusion. (2023).
[45]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj?rn Ommer. 2022a. High-Resolution Image Synthesis With Latent Diffusion Models. In Proc. Conference on Computer Vision and Pattern Recognition (CVPR).
[46]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj?rn Ommer. 2022b. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684?10695.
[47]
Saurabh Saxena, Charles Herrmann, Junhwa Hur, Abhishek Kar, Mohammad Norouzi, Deqing Sun, and David J Fleet. 2023. The Surprising Effectiveness of Diffusion Models for Optical Flow and Monocular Depth Estimation. arXiv preprint arXiv:2306.01923 (2023).
[48]
Johannes Lutz Sch?nberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. 2016. Pixelwise View Selection for Unstructured Multi-View Stereo. In European Conference on Computer Vision (ECCV).
[49]
Jonas Schult, Sam Tsai, Lukas H?llein, Bichen Wu, Jialiang Wang, Chih-Yao Ma, Kunpeng Li, Xiaofang Wang, Felix Wimbauer, Zijian He, Peizhao Zhang, Bastian Leibe, Peter Vajda, and Ji Hou. 2023. ControlRoom3D: Room Generation using Semantic Proxy Rooms. arXiv:2312.05208 (2023).
[50]
Bokui Shen, Xinchen Yan, Charles R Qi, Mahyar Najibi, Boyang Deng, Leonidas Guibas, Yin Zhou, and Dragomir Anguelov. 2023b. GINA-3D: Learning to Generate Implicit Neural Assets in the Wild. In Proc. Conference on Computer Vision and Pattern Recognition (CVPR). 4913?4926.
[51]
Liao Shen, Xingyi Li, Huiqiang Sun, Juewen Peng, Ke Xian, Zhiguo Cao, and Guosheng Lin. 2023a. Make-It-4D: Synthesizing a Consistent Long-Term Dynamic Scene Video from a Single Image. In Proceedings of the 31st ACM International Conference on Multimedia. 8167?8175.
[52]
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. 2023. MVDream: Multi-view Diffusion for 3D Generation. arXiv:2308.16512 (2023).
[53]
J. Ryan Shue, Eric Ryan Chan, Ryan Po, Zachary Ankner, Jiajun Wu, and Gordon Wetzstein. 2023. 3D Neural Field Generation Using Triplane Diffusion. In Proc. Conference on Computer Vision and Pattern Recognition (CVPR).
[54]
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, 2022. Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792 (2022).
[55]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020a. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020).
[56]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020b. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020).
[57]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020c. Score-Based Generative Modeling through Stochastic Differential Equations. In International Conference on Learning Representations.
[58]
Alexander Swerdlow, Runsheng Xu, and Bolei Zhou. 2023. Street-View Image Generation from a Bird?s-Eye View Layout. arXiv preprint arXiv:2301.04634 (2023).
[59]
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. 2021. Csdi: Conditional score-based diffusion models for probabilistic time series imputation. Advances in Neural Information Processing Systems 34 (2021), 24804?24816.
[60]
Seth J. Teller and Carlo H. S?quin. 1991. Visibility preprocessing for interactive walkthroughs. In Proceedings of the 18th Annual Conference on Computer Graphics and Interactive Techniques(SIGGRAPH ?91). Association for Computing Machinery, New York, NY, USA, 61?70. https://doi.org/10.1145/122718.122725
[61]
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Rapha?l Marinier, Marcin Michalski, and Sylvain Gelly. 2019. FVD: A new Metric for Video Generation. https://openreview.net/forum?id=rylgEULtdN
[62]
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. 2022. Phenaki: Variable length video generation from open domain textual description. arXiv preprint arXiv:2210.02399 (2022).
[63]
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A. Yeh, and Greg Shakhnarovich. 2022. Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation. arXiv preprint arXiv:2212.00774 (2022).
[64]
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. 2023. MotionCtrl: A Unified and Flexible Motion Controller for Video Generation. arXiv preprint arXiv:2312.03641 (2023).
[65]
Daniel Watson, William Chan, Ricardo Martin-Brualla, Jonathan Ho, Andrea Tagliasacchi, and Mohammad Norouzi. 2022. Novel View Synthesis with Diffusion Models. arxiv:2210.04628 [cs.CV]
[66]
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. 2023. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7623?7633.
[67]
Yinghao Xu, Hao Tan, Fujun Luan, Sai Bi, Peng Wang, Jiahao Li, Zifan Shi, Kalyan Sunkavalli, Gordon Wetzstein, Zexiang Xu, and Kai Zhang. 2024. DMV3D: Denoising Multi-View Diffusion using 3D Large Reconstruction Model. In Proc. International Conference on Learning Representations (ICLR).
[68]
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. 2023. MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model. arXiv preprint arXiv:2311.16498 (2023).
[69]
Kairui Yang, Enhui Ma, Jibin Peng, Qing Guo, Di Lin, and Kaicheng Yu. 2023a. BEVControl: Accurately Controlling Street-view Elements with Multi-perspective Consistency via BEV Sketch Layout. arXiv preprint arXiv:2308.01661 (2023).
[70]
Yuanbo Yang, Yifei Yang, Hanlei Guo, Rong Xiong, Yue Wang, and Yiyi Liao. 2023b. UrbanGIRAFFE: Representing Urban Scenes as Compositional Generative Neural Feature Fields. In ICCV.
[71]
Hong-Xing Yu, Haoyi Duan, Junhwa Hur, Kyle Sargent, Michael Rubinstein, William T Freeman, Forrester Cole, Deqing Sun, Noah Snavely, Jiajun Wu, 2023. WonderJourney: Going from Anywhere to Everywhere. arXiv preprint arXiv:2312.03884 (2023).
[72]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3836?3847.
[73]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In CVPR.