
“Sketch2Pose: estimating a 3D character pose from a bitmap sketch” by Brodt and Bessmeltsev
Conference:
Type(s):
Title:
- Sketch2Pose: estimating a 3D character pose from a bitmap sketch
Presenter(s)/Author(s):
Abstract:
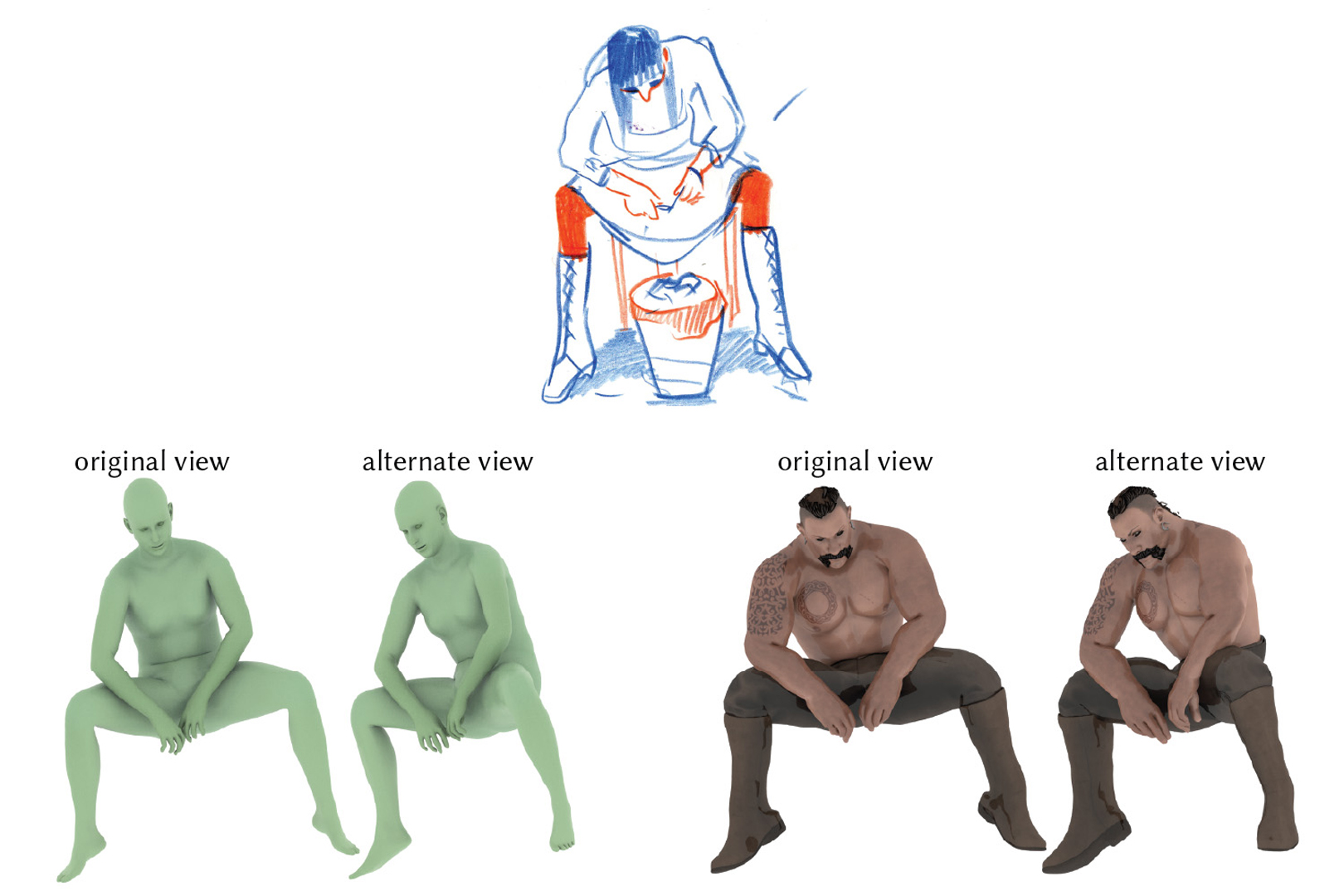
Artists frequently capture character poses via raster sketches, then use these drawings as a reference while posing a 3D character in a specialized 3D software — a time-consuming process, requiring specialized 3D training and mental effort. We tackle this challenge by proposing the first system for automatically inferring a 3D character pose from a single bitmap sketch, producing poses consistent with viewer expectations. Algorithmically interpreting bitmap sketches is challenging, as they contain significantly distorted proportions and foreshortening. We address this by predicting three key elements of a drawing, necessary to disambiguate the drawn poses: 2D bone tangents, self-contacts, and bone foreshortening. These elements are then leveraged in an optimization inferring the 3D character pose consistent with the artist’s intent. Our optimization balances cues derived from artistic literature and perception research to compensate for distorted character proportions. We demonstrate a gallery of results on sketches of numerous styles. We validate our method via numerical evaluations, user studies, and comparisons to manually posed characters and previous work.Code and data for our paper are available at http://www-labs.iro.umontreal.ca/bmpix/sketch2pose/.
References:
1. Kfir Aberman, Peizhuo Li, Sorkine-Hornung Olga, Dani Lischinski, Daniel Cohen-Or, and Baoquan Chen. 2020. Skeleton-Aware Networks for Deep Motion Retargeting. ACM Transactions on Graphics (TOG) 39, 4 (2020), 62.Google ScholarDigital Library
2. Ijaz Akhter and Michael J. Black. 2015. Pose-conditioned joint angle limits for 3D human pose reconstruction. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 07–12-June-2015 (2015), 1446–1455. Google ScholarCross Ref
3. Mikhail Bessmeltsev, Nicholas Vining, and Alla Sheffer. 2016. Gesture3D: Posing 3D Characters via Gesture Drawings. ACM Trans. Graph. 35, 6, Article 165 (Nov. 2016), 13 pages. Google ScholarDigital Library
4. Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J. Black. 2016. Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image. arXiv:1607.08128 [cs.CV]Google Scholar
5. Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2019. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv:1812.08008 [cs.CV]Google Scholar
6. João Carreira, Pulkit Agrawal, Katerina Fragkiadaki, and Jitendra Malik. 2016. Human Pose Estimation with Iterative Error Feedback. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4733–4742. Google ScholarCross Ref
7. Yu Chen, Tae-Kyun Kim, and Roberto Cipolla. 2011. Silhouette-based object phenotype recognition using 3D shape priors. In IEEE International Conference on Computer Vision, ICCV. 25–32.Google ScholarDigital Library
8. Yucheng Chen, Yingli Tian, and Mingyi He. 2020. Monocular human pose estimation: A survey of deep learning-based methods. Computer Vision and Image Understanding 192 (Mar 2020), 102897. Google ScholarDigital Library
9. Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. 2018. Cascaded Pyramid Network for Multi-Person Pose Estimation. (2018).Google Scholar
10. Byungkuk Choi, Roger Blanco i Ribera, J. P. Lewis, Yeongho Seol, Seokpyo Hong, Haegwang Eom, Sunjin Jung, and Junyong Noh. 2016. SketchiMo: Sketch-Based Motion Editing for Articulated Characters. ACM Trans. Graph. 35, 4, Article 146 (July 2016), 12 pages. Google ScholarDigital Library
11. M. G. Choi, K. Yang, T. Igarashi, J. Mitani, and J. Lee. 2012. Retrieval and visualization of human motion data via stick figures. Computer Graphics Forum 31 (2012), 2057–2065.Google ScholarDigital Library
12. Rishabh Dabral, Anurag Mundhada, Uday Kusupati, Safeer Afaque, and Arjun Jain. 2017. Structure-Aware and Temporally Coherent 3D Human Pose Estimation. CoRR abs/1711.09250 (2017). arXiv:1711.09250 http://arxiv.org/abs/1711.09250Google Scholar
13. James Davis, Maneesh Agrawala, Erika Chuang, Zoran Popović, and David Salesin. 2003. A Sketching Interface for Articulated Figure Animation. Proc. Symposium on Computer Animation (2003), 320–328.Google Scholar
14. Sai Kumar Dwivedi, Nikos Athanasiou, Muhammed Kocabas, and Michael J. Black. 2021. Learning To Regress Bodies From Images Using Differentiable Semantic Rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 11250–11259.Google Scholar
15. Mihai Fieraru, Mihai Zanfir, Elisabeta Oneata, Alin-Ionut Popa, Vlad Olaru, and Cristian Sminchisescu. 2021. Learning Complex 3D Human Self-Contact. Proceedings of the AAAI Conference on Artificial Intelligence 35, 2 (May 2021), 1343–1351. https://ojs.aaai.org/index.php/AAAI/article/view/16223Google ScholarCross Ref
16. Juergen Gall, Bodo Rosenhahn, Thomas Brox, and Hans Peter Seidel. 2010. Optimization and filtering for human motion capture : AAA multi-layer framework. International Journal of Computer Vision 87, 1–2 (2010), 75–92.Google ScholarDigital Library
17. Oliver Glauser, Wan-Chun Ma, Daniele Panozzo, Alec Jacobson, Otmar Hilliges, and Olga Sorkine-Hornung. 2016. Rig Animation with a Tangible and Modular Input Device. ACM Trans. Graph. 35, 4, Article 144 (July 2016), 11 pages. Google ScholarDigital Library
18. Keith Grochow, Steven L. Martin, Aaron Hertzmann, and Zoran Popović. 2004. Style-Based Inverse Kinematics. ACM Trans. Graph. 23, 3 (Aug. 2004), 522–531. Google ScholarDigital Library
19. Martin Guay, Marie-Paule Cani, and Rémi Ronfard. 2013. The Line of Action: An Intuitive Interface for Expressive Character Posing. ACM Trans. Graph. 32, 6, Article 205 (Nov. 2013), 8 pages. Google ScholarDigital Library
20. Martin Guay, Rémi Ronfard, Michael Gleicher, and Marie-Paule Cani. 2015. Space-Time Sketching of Character Animation. ACM Trans. Graph. 34, 4, Article 118 (July 2015), 10 pages. Google ScholarDigital Library
21. Fabian Hahn, Frederik Mutzel, Stelian Coros, Bernhard Thomaszewski, Maurizio Nitti, Markus Gross, and Robert W. Sumner. 2015. Sketch Abstractions for Character Posing. In Proc. Symp. Computer Animation. 185–191.Google Scholar
22. Ronie Hecker and Kenneth Perlin. 1992. Controlling 3D objects by sketching 2D views. Proc. SPIE 1828 (1992), 46–48.Google Scholar
23. Robert Hess and David Field. 1999. Integration of contours: new insights. Trends in Cognitive Sciences 3, 12 (1999), 480–486.Google ScholarCross Ref
24. Burne Hogarth. 1996. Dynamic Figure Drawing. Watson-Guptill.Google Scholar
25. Clara Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. 2014. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Analysis & Machine Intelligence 36, 7 (2014), 1325–1339.Google ScholarDigital Library
26. Alec Jacobson, Ladislav Kavan, and Olga Sorkine. 2013. Robust Inside-Outside Segmentation using Generalized Winding Numbers. ACM Trans. Graph. 32, 4 (2013).Google ScholarDigital Library
27. Eakta Jain, Yaser Sheikh, Moshe Mahler, and Jessica Hodgins. 2012. Three-dimensional proxies for hand-drawn characters. ACM Trans. on Graphics 31, 1 (2012), 1–16.Google ScholarDigital Library
28. Hanbyul Joo, Natalia Neverova, and Andrea Vedaldi. 2021. Exemplar Fine-Tuning for 3D Human Model Fitting Towards In-the-Wild 3D Human Pose Estimation. 2021 International Conference on 3D Vision (3DV) (2021), 42–52.Google ScholarCross Ref
29. Hanbyul Joo, Tomas Simon, and Yaser Sheikh. 2018. Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8320–8329. Google ScholarCross Ref
30. Angjoo Kanazawa, Michael J. Black, David W. Jacobs, and Jitendra Malik. 2018. End-to-End Recovery of Human Shape and Pose. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018. IEEE Computer Society, 7122–7131. Google ScholarCross Ref
31. K. Koffka. 1955. Principles of Gestalt Psychology. Routledge & K. Paul.Google Scholar
32. Nikos Kolotouros, Georgios Pavlakos, Michael J. Black, and Kostas Daniilidis. 2019. Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop. In Proceedings of the IEEE International Conference on Computer Vision.Google ScholarCross Ref
33. Ji-yong Kwon and In-Kwon Lee. 2012. The Squash-and-Stretch Stylization for Character Motions. IEEE Trans. Vis. Comput. Graph. 18, 3 (2012), 488–500. Google ScholarDigital Library
34. Juncong Lin, Takeo Igarashi, Jun Mitani, and Greg Saul. 2010. A Sketching Interface for Sitting-pose Design. In Proc. Sketch-Based Interfaces and Modeling Symposium. 111–118.Google Scholar
35. Huajun Liu, Fuqiang Liu, Xinyi Fan, and Dong Huang. 2021. Polarized Self-Attention: Towards High-quality Pixel-wise Regression. Arxiv Pre-Print arXiv:2107.00782 (2021).Google Scholar
36. Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. 2015. SMPL: A Skinned Multi-Person Linear Model. ACM Trans. Graph. 34, 6, Article 248 (Oct. 2015), 16 pages. Google ScholarDigital Library
37. Meysam Madadi, Hugo Bertiche, and Sergio Escalera. 2018. SMPLR: Deep SMPL reverse for 3D human pose and shape recovery. CoRR abs/1812.10766 (2018). arXiv:1812.10766 http://arxiv.org/abs/1812.10766Google Scholar
38. Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. 2019. AMASS: Archive of Motion Capture as Surface Shapes. In International Conference on Computer Vision. 5442–5451.Google Scholar
39. C Mao, S F Qin, and D K Wright. 2005. A sketch-based gesture interface for rough 3D stick figure animation. Proc. Sketch Based Interfaces and Modeling (2005).Google Scholar
40. Julieta Martinez, Rayat Hossain, Javier Romero, and James J. Little. 2017. A simple yet effective baseline for 3d human pose estimation. In ICCV.Google Scholar
41. Dushyant Mehta, Helge Rhodin, Dan Casas, Pascal Fua, Oleksandr Sotnychenko, Weipeng Xu, and Christian Theobalt. 2017a. Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision. In 3D Vision (3DV), 2017 Fifth International Conference on. IEEE. Google ScholarCross Ref
42. Dushyant Mehta, Oleksandr Sotnychenko, Franziska Mueller, Weipeng Xu, Mohamed Elgharib, Pascal Fua, Hans Peter Seidel, Helge Rhodin, Gerard Pons-Moll, and Christian Theobalt. 2020. XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera. ACM Transactions on Graphics 39, 4 (2020), 1–24. arXiv:1907.00837 Google ScholarDigital Library
43. Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans Peter Seidel, Weipeng Xu, Dan Casas, and Christian Theobalt. 2017b. VNect: Real-time 3D human pose estimation with a single RGB camera. ACM Transactions on Graphics 36, 4 (2017), 1–13. arXiv:1705.01583 Google ScholarDigital Library
44. Lea Müller, Ahmed A. A. Osman, Siyu Tang, Chun-Hao P. Huang, and Michael J. Black. 2021. On Self-Contact and Human Pose. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recogßnition (CVPR).Google Scholar
45. Alejandro Newell, Kaiyu Yang, and Jia Deng. 2016. Stacked Hourglass Networks for Human Pose Estimation. CoRR abs/1603.06937 (2016). arXiv:1603.06937 http://arxiv.org/abs/1603.06937Google Scholar
46. David Novotný, Nikhila Ravi, Benjamin Graham, Natalia Neverova, and Andrea Vedaldi. 2019. C3DPO: Canonical 3D Pose Networks for Non-Rigid Structure From Motion. CoRR abs/1909.02533 (2019). arXiv:1909.02533 http://arxiv.org/abs/1909.02533Google Scholar
47. George Papandreou, Tyler Zhu, Nori Kanazawa, Alexander Toshev, Jonathan Tompson, Chris Bregler, and Kevin P. Murphy. 2017. Towards Accurate Multi-person Pose Estimation in the Wild. CoRR abs/1701.01779 (2017). arXiv:1701.01779 http://arxiv.org/abs/1701.01779Google Scholar
48. Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. 2019. Expressive Body Capture: 3D Hands, Face, and Body from a Single Image. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).Google Scholar
49. Georgios Pavlakos, Xiaowei Zhou, Konstantinos G. Derpanis, and Kostas Daniilidis. 2017. Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1263–1272. Google ScholarCross Ref
50. Georgios Pavlakos, Luyang Zhu, Xiaowei Zhou, and Kostas Daniilidis. 2018. Learning to Estimate 3D Human Pose and Shape From a Single Color Image. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018. IEEE Computer Society, 459–468. Google ScholarCross Ref
51. Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. 2012. Reconstructing 3D Human Pose from 2D Image Landmarks. In Computer Vision – ECCV 2012, Andrew Fitzgibbon, Svetlana Lazebnik, Pietro Perona, Yoichi Sato, and Cordelia Schmid (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 573–586.Google ScholarDigital Library
52. D. Ramanan. 2011. Part-Based Models for Finding People and Estimating Their Pose. Springer (2011), 199–223.Google ScholarCross Ref
53. G. Rogez, P. Weinzaepfel, and C. Schmid. 2017. LCR-Net: Localization-Classification-Regression for Human Pose. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1216–1224. Google ScholarCross Ref
54. Yossi Rubner, Carlo Tomasi, and Leonidas J Guibas. 2000. The earth mover’s distance as a metric for image retrieval. International journal of computer vision 40, 2 (2000), 99–121.Google Scholar
55. Benjamin Sapp, Alexander Toshev, and Ben Taskar. 2010. Cascaded models for articulated pose estimation. Lecture Notes in Computer Science 6312 (2010), 406–420.Google ScholarDigital Library
56. Ryan Schmidt, Azam Khan, Gord Kurtenbach, and Karan Singh. 2009. On expert performance in 3D curve-drawing tasks. Proceedings of the 6th Eurographics Symposium on Sketch-Based Interfaces and Modeling – SBIM ’09 1 (2009), 133. Google ScholarDigital Library
57. Mingyi Shi, Kfir Aberman, Andreas Aristidou, Taku Komura, Dani Lischinski, Daniel Cohen-Or, and Baoquan Chen. 2020. MotioNet: 3D Human Motion Reconstruction from Monocular Video with Skeleton Consistency. ACM Trans. Graph. 40, 1, Article 1 (Sept. 2020), 15 pages. Google ScholarDigital Library
58. Karan Singh. 2002. A Fresh Perspective. In Proceedings of the Graphics Interface 2002 Conference, May 27–29, 2002, Calgary, Alberta, Canada (Calgary, Alberta). 17–24. http://graphicsinterface.org/wp-content/uploads/gi2002-3.pdfGoogle Scholar
59. Tibor Stanko, Mikhail Bessmeltsev, David Bommes, and Adrien Bousseau. 2020. Integer-Grid Sketch Simplification and Vectorization. Computer Graphics Forum (Proceedings of the Eurographics Symposium on Geometry Processing) 39, 5 (jul 2020), 149–161. http://www-sop.inria.fr/reves/Basilic/2020/SBBB20Google Scholar
60. Nisha Sudarsanam, Cindy Grimm, and Karan Singh. 2008. Non-Linear Perspective Widgets for Creating Multiple-View Images. In Proceedings of the 6th International Symposium on Non-Photorealistic Animation and Rendering (Annecy, France) (NPAR ’08). Association for Computing Machinery, New York, NY, USA, 69–77. Google ScholarDigital Library
61. Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. 2019. Deep High-Resolution Representation Learning for Human Pose Estimation. In CVPR.Google Scholar
62. Xiao Sun, Jiaxiang Shang, Shuang Liang, and Yichen Wei. 2017. Compositional Human Pose Regression. In 2017 IEEE International Conference on Computer Vision (ICCV). 2621–2630. Google ScholarCross Ref
63. Bugra Tekin, Pablo Márquez-Neila, Mathieu Salzmann, and Pascal Fua. 2017. Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation. arXiv:1611.05708 [cs.CV]Google Scholar
64. Bugra Tekin, Artem Rozantsev, Vincent Lepetit, and Pascal Fua. 2016. Direct Prediction of 3D Body Poses From Motion Compensated Sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Google ScholarCross Ref
65. Frank Thomas and Ollie Johnston. 1981. The Illusion of Life: Disney Animation (1st hyperi ed.). Disney Editions, New York, N.Y.Google Scholar
66. Denis Tomè, Chris Russell, and L. Agapito. 2017. Lifting from the Deep: Convolutional 3D Pose Estimation from a Single Image. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017), 5689–5698.Google ScholarCross Ref
67. Alexander Toshev and Christian Szegedy. 2014. DeepPose: Human Pose Estimation via Deep Neural Networks. In 2014 IEEE Conference on Computer Vision and Pattern Recognition. 1653–1660. Google ScholarDigital Library
68. Hsiao-Yu Fish Tung, Adam W. Harley, William Seto, and Katerina Fragkiadaki. 2017. Adversarial Inverse Graphics Networks: Learning 2D-to-3D Lifting and Image-to-Image Translation from Unpaired Supervision. arXiv:1705.11166 [cs.CV]Google Scholar
69. Leo Brodie Walt Stanchfield. 2020. Gesture Drawing for Animation (1 ed.). Independently published.Google Scholar
70. Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, and Bin Xiao. 2019b. Deep High-Resolution Representation Learning for Visual Recognition. TPAMI (2019).Google Scholar
71. Keze Wang, Liang Lin, Chenhan Jiang, Chen Qian, and Pengxu Wei. 2019a. 3D Human Pose Machines with Self-supervised Learning. IEEE transactions on pattern analysis and machine intelligence (2019).Google ScholarCross Ref
72. Xiaolin Wei and Jinxiang Chai. 2011. Intuitive Interactive Human-Character Posing with Millions of Example Poses. IEEE Comput. Graph. Appl. 31, 4 (2011), 78–88.Google ScholarDigital Library
73. Marta Wnuczko, Karan Singh, and John M Kennedy. 2016. Foreshortening produces errors in the perception of angles pictured as on the ground. Attention, Perception, & Psychophysics 78, 1 (2016), 309–316.Google ScholarCross Ref
74. Jungdam Won and Jehee Lee. 2016. Shadow Theatre: Discovering Human Motion from a Sequence of Silhouettes. ACM Trans. Graph. 35, 4, Article 147 (July 2016), 12 pages. Google ScholarDigital Library
75. Donglai Xiang, Hanbyul Joo, and Yaser Sheikh. 2019. Monocular Total Capture: Posing Face, Body, and Hands in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Google ScholarCross Ref
76. Bin Xiao, Haiping Wu, and Yichen Wei. 2018. Simple Baselines for Human Pose Estimation and Tracking. In European Conference on Computer Vision (ECCV).Google Scholar
77. Baoxuan Xu, William Chang, Alla Sheffer, Adrien Bousseau, James McCrae, and Karan Singh. 2014. True2Form: 3D Curve Networks from 2D Sketches via Selective Regularization. Transactions on Graphics (Proc. SIGGRAPH 2014) 33, 4 (2014). https://doi.org/2601097.2601128Google ScholarDigital Library
78. Yuanlu Xu, Song Chun Zhu, and Tony Tung. 2019. DenseRaC: Joint 3D pose and shape estimation by dense render-And-compare. arXiv (2019), 7760–7770.Google Scholar
79. Wei Yang, Wanli Ouyang, Xiaolong Wang, Jimmy S. J. Ren, Hongsheng Li, and Xiaogang Wang. 2018. 3D Human Pose Estimation in the Wild by Adversarial Learning. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018. IEEE Computer Society, 5255–5264. Google ScholarCross Ref
80. Y. Yang and D. Ramanan. 2013. Articulated Human Detection with Flexible Mixtures of Parts. IEEE Transactions on Pattern Analysis and Machine Intelligence 35, 12 (2013), 2878–2890. Google ScholarDigital Library
81. Jianmin Zhao and Norman I. Badler. 1994. Inverse kinematics positioning using nonlinear programming for highly articulated figures. ACM Transactions on Graphics 13, 4 (1994), 313–336.Google ScholarDigital Library
82. Yue Zhong, Yulia Gryaditskaya, Honggang Zhang, and Yi-Zhe Song. 2020. Deep Sketch-Based Modeling: Tips and Tricks. arXiv:2011.06133 [cs.CV]Google Scholar
83. Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, and Yichen Wei. 2017. Towards 3D Human Pose Estimation in the Wild: A Weakly-Supervised Approach. In The IEEE International Conference on Computer Vision (ICCV).Google ScholarCross Ref
84. Xingyi Zhou, Xiao Sun, Wei Zhang, Shuang Liang, and Yichen Wei. 2016. Deep Kinematic Pose Regression. In Computer Vision – ECCV 2016 Workshops – Amsterdam, The Netherlands, October 8–10 and 15–16, 2016, Proceedings, Part III (Lecture Notes in Computer Science, Vol. 9915), Gang Hua and Hervé Jégou (Eds.). 186–201. Google ScholarCross Ref