
“Sign Motion Generation by Motion Diffusion Model” by Hakozaki, Murakami, Uchida, Miyazaki and Kaneko
Conference:
Type(s):
Title:
- Sign Motion Generation by Motion Diffusion Model
Session/Category Title:
- Images, Video & Computer Vision
Presenter(s)/Author(s):
Abstract:
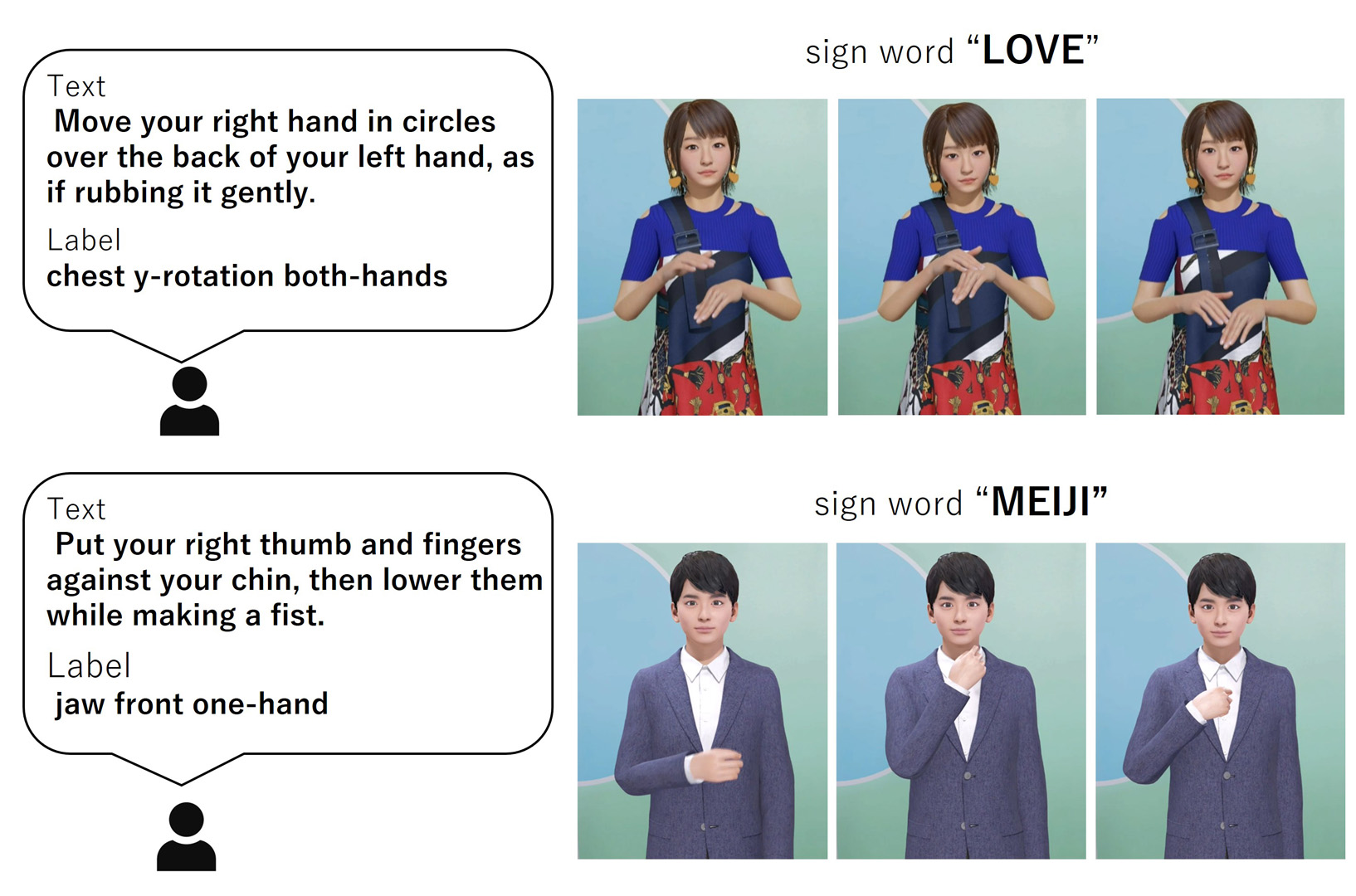
We propose a method that uses a diffusion model to generate sign motions from the text and label prompts, enabling the generation of complex hand and body movements required to express sign words, which has been difficult in previous work.
References:
[1]
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. 2022. Generating Diverse and Natural 3D Human Motions From Text. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5152?5161.
[2]
Matthias Plappert, Christian Mandery, and Tamim Asfour. 2016. The KIT Motion-Language Dataset. Big Data 4, 4 (Dec. 2016), 236?252. https://doi.org/10.1089/big.2016.0028
[3]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit Haim Bermano. 2023. Human Motion Diffusion Model. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=SJ1kSyO2jwu
[4]
Tsubasa Uchida, Naoki Nakatani, Taro Miyazaki, Hiroyuki Kaneko, and Masanori Sano. 2023. Motion Editing Tool for Reproducing Grammatical Elements of Japanese Sign Language Avatar Animation. In IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW). 1?5. https://doi.org/10.1109/ICASSPW59220.2023.10193198
[5]
Akihiko Yonekawa (Ed.). 2011. [New Japanese Sign Language Dictionary] Shin Nihongo Shuwajiten(in Japanese).