
“SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound” by Dagli, Prakash, Wu and Khosravani
Conference:
Type(s):
Title:
- SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Session/Category Title:
- Interactive Techniques
Presenter(s)/Author(s):
Abstract:
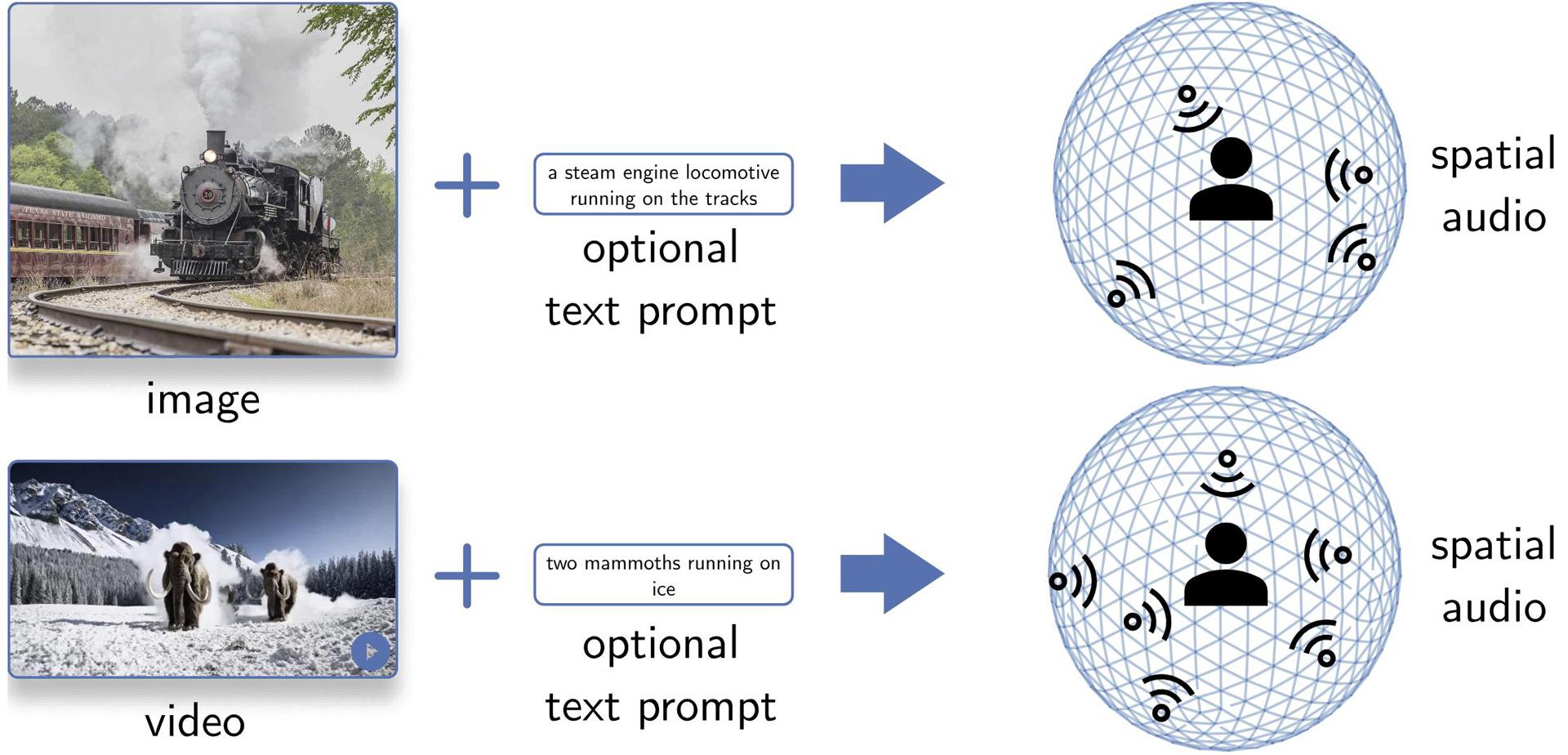
SEE-2-SOUND is a zero-shot approach that generates spatial audio for visual content. It decomposes the task into four steps: identifying visual regions of interest, locating them in 3D space, generating mono-audio for each, and integrating them into spatial audio. Our approach can generate realistic spatial-audio from images or videos.
References:
[1] Changan Chen, Ruohan Gao, Paul Calamia, and Kristen Grauman. 2022. Visual acoustic matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18858–18868.
[2] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. 2023. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4015–4026.
[3] Roy Sheffer and Yossi Adi. 2023. I hear your true colors: Image guided audio generation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5.
[4] Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, and Mohit Bansal. 2024. Any-to-any generation via composable diffusion. Advances in Neural Information Processing Systems 36 (2024).
[5] Ho-Hsiang Wu, Prem Seetharaman, Kundan Kumar, and Juan Pablo Bello. 2022. Wav2clip: Learning robust audio representations from clip. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 4563–4567.
[6] Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data. In CVPR.