
“Learning to optimize halide with tree search and random programs” by Adams, Ma, Anderson, Baghdadi, Li, et al. …
Conference:
Type(s):
Title:
- Learning to optimize halide with tree search and random programs
Session/Category Title:
- Sound Graphics
Presenter(s)/Author(s):
Abstract:
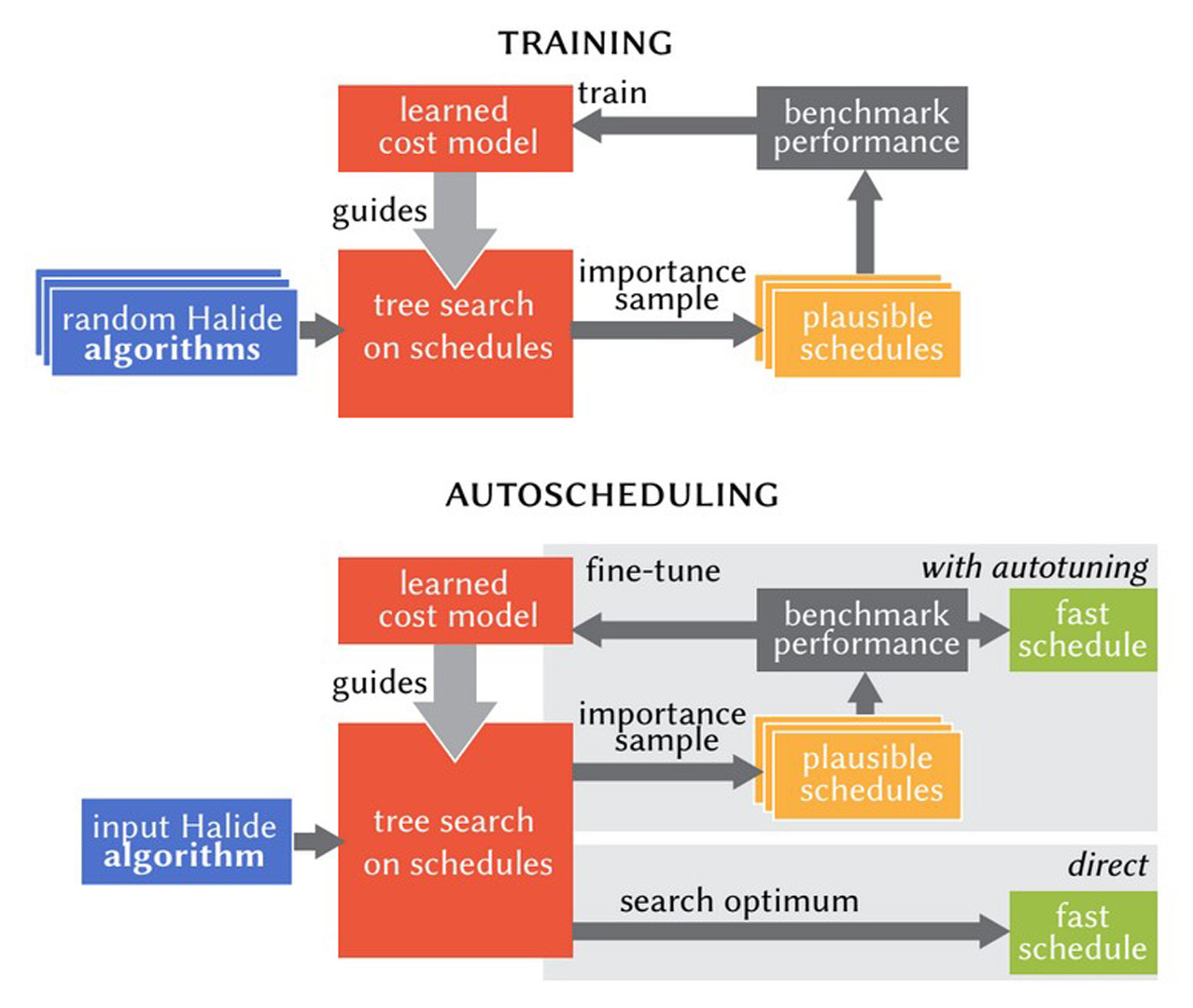
We present a new algorithm to automatically schedule Halide programs for high-performance image processing and deep learning. We significantly improve upon the performance of previous methods, which considered a limited subset of schedules. We define a parameterization of possible schedules much larger than prior methods and use a variant of beam search to search over it. The search optimizes runtime predicted by a cost model based on a combination of new derived features and machine learning. We train the cost model by generating and featurizing hundreds of thousands of random programs and schedules. We show that this approach operates effectively with or without autotuning. It produces schedules which are on average almost twice as fast as the existing Halide autoscheduler without autotuning, or more than twice as fast with, and is the first automatic scheduling algorithm to significantly outperform human experts on average.
References:
1. Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Gregory S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian J. Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Józefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Gordon Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul A. Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda B. Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. CoRR (2016). http://arxiv.org/abs/1603.04467Google Scholar
2. Jason Ansel, Shoaib Kamil, Kalyan Veeramachaneni, Jonathan Ragan-Kelley, Jeffrey Bosboom, Una-May O’Reilly, and Saman Amarasinghe. 2014. OpenTuner: An Extensible Framework for Program Autotuning. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation (PACT ’14). ACM. Google ScholarDigital Library
3. Amir H. Ashouri, William Killian, John Cavazos, Gianluca Palermo, and Cristina Silvano. 2018. A Survey on Compiler Autotuning Using Machine Learning. ACM Comput. Surv. 51, 5 (Sept. 2018). Google ScholarDigital Library
4. Riyadh Baghdadi, Ulysse Beaugnon, Albert Cohen, Tobias Grosser, Michael Kruse, Chandan Reddy, Sven Verdoolaege, Adam Betts, Alastair F. Donaldson, Jeroen Ketema, Javed Absar, Sven van Haastregt, Alexey Kravets, Anton Lokhmotov, Robert David, and Elnar Hajiyev. 2015. PENCIL: A Platform-Neutral Compute Intermediate Language for Accelerator Programming. In Proceedings of the 2015 International Conference on Parallel Architecture and Compilation (PACT) (PACT ’15). IEEE Computer Society. Google ScholarDigital Library
5. Uday Bondhugula, Albert Hartono, J. Ramanujam, and P. Sadayappan. 2008. A Practical Automatic Polyhedral Parallelizer and Locality Optimizer. In Proceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI ’08). ACM. Google ScholarDigital Library
6. Jiawen Chen, Andrew Adams, Neal Wadhwa, and Samuel W. Hasinof. 2016. Bilateral Guided Upsampling. ACM Trans. Graph. 35, 6 (Nov. 2016). Google ScholarDigital Library
7. Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. 2015. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. CoRR (2015). http://arxiv.org/abs/1512.01274Google Scholar
8. Tianqi Chen, Thierry Moreau, Ziheng Jiang, Haichen Shen, Eddie Q. Yan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018a. TVM: End-to-End Optimization Stack for Deep Learning. CoRR (2018). http://arxiv.org/abs/1802.04799Google Scholar
9. Tianqi Chen, Lianmin Zheng, Eddie Q. Yan, Ziheng Jiang, Thierry Moreau, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018b. Learning to Optimize Tensor Programs. CoRR (2018). http://arxiv.org/abs/1805.08166 Google ScholarDigital Library
10. Chris Cummins, Pavlos Petoumenos, Zheng Wang, and Hugh Leather. 2017. End-to-end deep learning of optimization heuristics. In Parallel Architectures and Compilation Techniques (PACT), 2017 26th International Conference on. IEEE.Google ScholarCross Ref
11. Grigori Fursin, Cupertino Miranda, Olivier Temam, Mircea Namolaru, Elad Yom-Tov, Ayal Zaks, Bilha Mendelson, Edwin Bonilla, John Thomson, Hugh Leather, et al. 2008. MILEPOST GCC: machine learning based research compiler. In GCC summit.Google Scholar
12. Tobias Grosser, Armin Groslinger, and Christian Lengauer. 2012. Polly – Performing Polyhedral Optimizations on a Low-Level Intermediate Representation. Parallel Processing Letters 22, 4 (2012).Google ScholarCross Ref
13. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Google Scholar
14. James Hegarty, John Brunhaver, Zachary DeVito, Jonathan Ragan-Kelley, Noy Cohen, Steven Bell, Artem Vasilyev, Mark Horowitz, and Pat Hanrahan. 2014. Darkroom: Compiling High-level Image Processing Code into Hardware Pipelines. ACM Trans. Graph. (Proc. SIGGRAPH) 33, 4 (July 2014). Google ScholarDigital Library
15. Intel. 2016. Intel(R) Math Kernel Library for Deep Neural Networks. https://github.com/intel/mkl-dnnGoogle Scholar
16. Abhinav Jangda and Uday Bondhugula. 2018. An effective fusion and tile size model for optimizing image processing pipelines. In Symposium on Principles and Practice of Parallel Programming. Google ScholarDigital Library
17. Diederick P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In International Conference on Learning Representations.Google Scholar
18. Tzu-Mao Li, Michaël Gharbi, Andrew Adams, Frédo Durand, and Jonathan Ragan-Kelley. 2018. Differentiable Programming for Image Processing and Deep Learning in Halide. ACM Trans. Graph. 37, 4 (July 2018). Google ScholarDigital Library
19. Charith Mendis, Saman Amarasinghe, and Michael Carbin. 2018. Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation using Deep Neural Networks. ArXiv e-prints (Aug. 2018). arXiv:cs.DC/1808.07412 https://arxiv.org/pdf/1808.07412.pdfGoogle Scholar
20. Ravi Teja Mullapudi, Andrew Adams, Dillon Sharlet, Jonathan Ragan-Kelley, and Kayvon Fatahalian. 2016. Automatically Scheduling Halide Image Processing Pipelines. ACM Trans. Graph. 35, 4 (July 2016). Google ScholarDigital Library
21. Ravi Teja Mullapudi, Vinay Vasista, and Uday Bondhugula. 2015. PolyMage: Automatic Optimization for Image Processing Pipelines. SIGARCH Comput. Archit. News 43, 1 (March 2015).Google ScholarDigital Library
22. Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. Automatic differentiation in PyTorch. In NIPS Autodiff Workshop.Google Scholar
23. Jonathan Ragan-Kelley, Andrew Adams, Sylvain Paris, Marc Levoy, Saman Amarasinghe, and Frédo Durand. 2012. Decoupling Algorithms from Schedules for Easy Optimization of Image Processing Pipelines. ACM Trans. Graph. 31, 4 (July 2012). Google ScholarDigital Library
24. Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. 2013. Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines. SIGPLAN Not. 48, 6 (June 2013). Google ScholarDigital Library
25. Mohammed Rahman, Louis-Noël Pouchet, and P Sadayappan. 2010. Neural network assisted tile size selection. In International Workshop on Automatic Performance Tuning (IWAPT’2010). Berkeley, CA: Springer Verlag.Google Scholar
26. D. Raj. Reddy. 1977. Speech Understanding Systems: A Summary of Results of the Five-Year Research Effort. Department of Computer Science Technical Report. Carnegie Mellon University.Google Scholar
27. Savvas Sioutas, Sander Stuijk, Henk Corporaal, Twan Basten, and Lou Somers. 2018. Loop Transformations Leveraging Hardware Prefetching. In Proceedings of the 2018 International Symposium on Code Generation and Optimization (CGO 2018). ACM. Google ScholarDigital Library
28. Savvas Sioutas, Sander Stuijk, Luc Waeijen, Twan Basten, Henk Corporaal, and Lou Somers. 2019. Schedule Synthesis for Halide Pipelines Through Reuse Analysis. ACM Trans. Archit. Code Optim. 16, 2 (April 2019). Google ScholarDigital Library
29. Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zach DeVito, William S. Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. 2018. Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions. CoRR (2018). http://arxiv.org/abs/1802.04730Google Scholar