
“Learning hierarchical shape segmentation and labeling from online repositories”
Conference:
Type(s):
Title:
- Learning hierarchical shape segmentation and labeling from online repositories
Presenter(s)/Author(s):
Abstract:
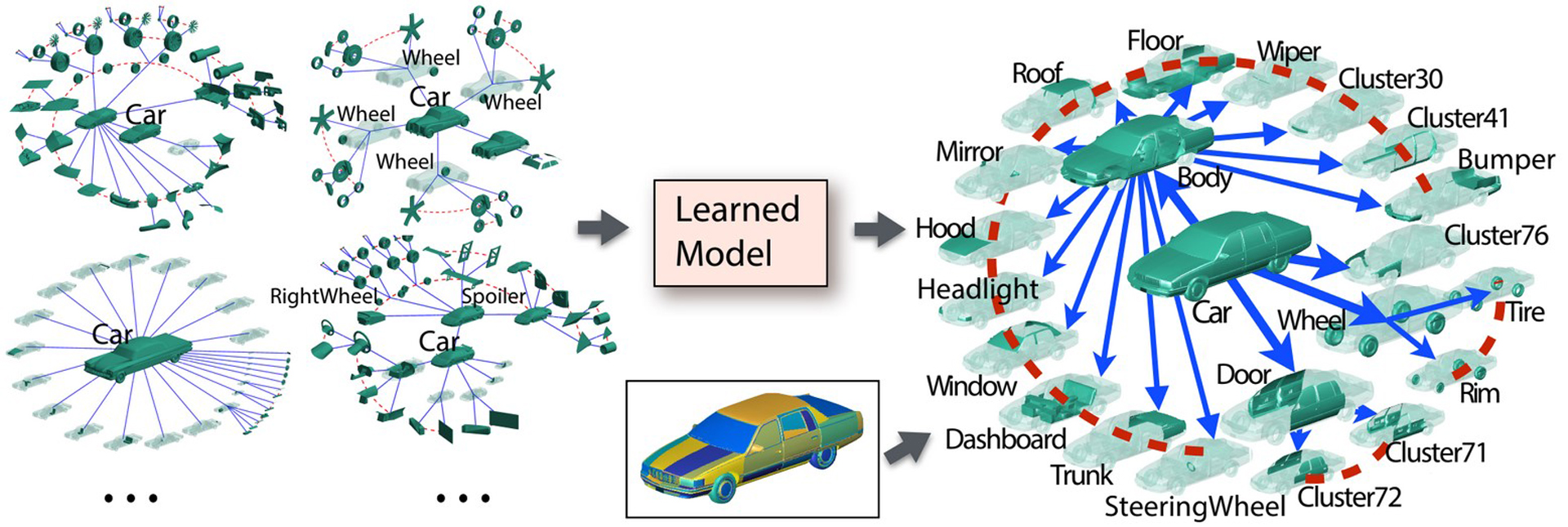
We propose a method for converting geometric shapes into hierarchically segmented parts with part labels. Our key idea is to train category-specific models from the scene graphs and part names that accompany 3D shapes in public repositories. These freely-available annotations represent an enormous, untapped source of information on geometry. However, because the models and corresponding scene graphs are created by a wide range of modelers with different levels of expertise, modeling tools, and objectives, these models have very inconsistent segmentations and hierarchies with sparse and noisy textual tags. Our method involves two analysis steps. First, we perform a joint optimization to simultaneously cluster and label parts in the database while also inferring a canonical tag dictionary and part hierarchy. We then use this labeled data to train a method for hierarchical segmentation and labeling of new 3D shapes. We demonstrate that our method can mine complex information, detecting hierarchies in man-made objects and their constituent parts, obtaining finer scale details than existing alternatives. We also show that, by performing domain transfer using a few supervised examples, our technique outperforms fully-supervised techniques that require hundreds of manually-labeled models.
References:
1. Sugato Basu, Mikhail Bilenko, and Raymond J Mooney. 2004. A probabilistic framework for semi-supervised clustering. In Proc. KDD. Google ScholarDigital Library
2. Serge Belongie, Jitendra Malik, and Jan Puzicha. 2002. Shape Matching and Object Recognition Using Shape Contexts. IEEE T-PAMI 24, 24 (2002), 509–521. Google ScholarDigital Library
3. Yuri Boykov, Olga Veksler, and Ramin Zabih. 2001. Fast approximate energy minimization via graph cuts. IEEE Trans. PAMI (2001).Google Scholar
4. Olivier Cappé and Eric Moulines. 2009. On-line expectation-maximization algorithm for latent data models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 71, 3 (2009), 593–613. Google ScholarCross Ref
5. Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. 2015. ShapeNet: An Information-Rich 3D Model Repository. (2015). arXiv:1512.03012.Google Scholar
6. Ding-Yun Chen, Xiao-Pei Tian, Yu-Te Shen, and Ming Ouhyoung. 2003. On Visual Similarity Based 3D Model Retrieval. In Computer Graphics Forum (Eurographics).Google Scholar
7. Xiaobai Chen, Aleksey Golovinskiy and Thomas Funkhouser. 2009. A Benchmark for 3D Mesh Segmentation. In ACM SIGGRAPH (SIGGRAPH). Article 73, 73:1–73:12 pages.Google Scholar
8. Xinlei Chen and Abhinav Gupta. 2015. Webly Supervised Learning of Convolutional Networks. In Proc. ICCV. Google ScholarDigital Library
9. Matthew Fisher, Manolis Savva, and Pat Hanrahan. 2011. Characterizing structural relationships in scenes using graph kernels. In ACM TOG, Vol. 30. 34. Google ScholarDigital Library
10. Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. In AISTATS.Google Scholar
11. Aleksey Golovinskiy and Thomas Funkhouser. 2009. Consistent Segmentation of 3D Models. Proc. SMI 33, 3 (2009), 262–269.Google Scholar
12. Kan Guo, Dongqing Zou, and Xiaowu Chen. 2015. 3D Mesh Labeling via Deep Convolutional Neural Networks. ACM TOG 35, 1, Article 3 (2015), 12 pages.Google Scholar
13. Ruizhen Hu, Lubin Fan, , and Ligang Liu. 2012. Co-segmentation of 3D shapes via subspace clustering. SGP 31, 5 (2012), 1703–1713. Google ScholarDigital Library
14. Qixing Huang, Vladlen Koltun, and Leonidas Guibas. 2011. Joint shape segmentation with linear programming. In ACM SIGGRAPH Asia. 125:1–125:12. Google ScholarDigital Library
15. Qixing Huang, Fan Wang, and Leonidas Guibas. 2014. Functional Map Networks for Analyzing and Exploring Large Shape Collections. SIGGRAPH 33, 4 (2014). Google ScholarDigital Library
16. Hamid Izadinia, Bryan C. Russell, Ali Farhadi, Matthew D. Hoffman, and Aaron Hertzmann. 2015. Deep Classifiers from Image Tags in the Wild. In Proc. Multimedia COMMONS. Google ScholarDigital Library
17. Andrew E. Johnson and Martial Hebert. 1999. Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes. IEEE T-PAMI 21, 5 (1999), 433–449. Google ScholarDigital Library
18. Evangelos Kalogerakis, Aaron Hertzmann, and Karan Singh. 2010. Learning 3D mesh segmentation and labeling. ACM Transactions on Graphics (TOG) 29, 4 (2010), 102.Google ScholarDigital Library
19. Vladimir G Kim, Wilmot Li, Niloy J Mitra, Siddhartha Chaudhuri, Stephen DiVerdi, and Thomas Funkhouser. 2013. Learning part-based templates from large collections of 3D shapes. ACM Transactions on Graphics (TOG) 32, 4 (2013), 70.Google ScholarDigital Library
20. Diederik P. Kingma and Jimmy Lei Ba. 2015. Adam: A Method for Stochastic Optimization. In Proc. ICLR.Google Scholar
21. Xirong Li, Tiberio Uricchio, Lamberto Ballan, Marco Bertini, Cees G. M. Snoek, and Alberto Del Bimbo. 2016. Socializing the Semantic Gap: A Comparative Survey on Image Tag Assignment, Refinement, and Retrieval. ACM Comput. Surv. 49, 1 (2016). Google ScholarDigital Library
22. Tianqiang Liu, Siddhartha Chaudhuri, Vladimir G. Kim, Qi-Xing Huang, Niloy J. Mitra, and Thomas Funkhouser. 2014. Creating Consistent Scene Graphs Using a Probabilistic Grammar. SIGGRAPH Asia 33, 6 (2014). Google ScholarDigital Library
23. Niloy J Mitra, Michael Wand, Hao Zhang, Daniel Cohen-Or, and Martin Bokeloh. 2013. Structure-aware shape processing. In Eurographics STARs. 175–197.Google Scholar
24. Radford M Neal and Geoffrey E Hinton. 1998. A view of the EM algorithm that justifies incremental, sparse, and other variants. In Learning in graphical models. Springer, 355–368. Google ScholarCross Ref
25. Vicente Ordonez, Girish Kulkarni, and Tamara L. Berg. 2011. Im2text: Describing images using 1 million captioned photographs. In Proc. NIPS.Google Scholar
26. Robert Osada, Thomas Funkhouser, Bernard Chazelle, and David Dobkin. 2002. Shape Distributions. ACM Transactions on Graphics (2002).Google Scholar
27. Oana Sidi, Oliver van Kaick, Yanir Kleiman, Hao Zhang, and Daniel Cohen-Or. 2011. Unsupervised Co-Segmentation of a Set of Shapes via Descriptor-Space Spectral Clustering. ACM SIGGRAPH Asia 30, 6 (2011), 126:1–126:9.Google Scholar
28. Jerry Talton, Lingfeng Yang, Ranjitha Kumar, Maxine Lim, Noah Goodman, and Radomír Měch. 2012. Learning design patterns with bayesian grammar induction. In UIST. Google ScholarDigital Library
29. Oliver van Kaick, Kai Xu, Hao Zhang, Yanzhen Wang, Shuyang Sun, Ariel Shamir, and Daniel Cohen-Or. 2013. Co-hierarchical analysis of shape structures. ACM Transactions on Graphics (TOG) 32, 4 (2013), 69.Google ScholarDigital Library
30. Yunhai Wang, Shmulik Asafi, Oliver van Kaick, Hao Zhang, Daniel Cohen-Or, and Baoquan Chenand. 2012. Active Co-Analysis of a Set of Shapes. SIGGRAPH Asia (2012).Google Scholar
31. Yanzhen Wang, Kai Xu, Jun Li, Hao Zhang, Ariel Shamir, Ligang Liu, Zhiquan Cheng, and Yueshan Xiong. 2011. Symmetry Hierarchy of Man-Made Objects. Eurographics 30, 2 (2011). Google ScholarCross Ref
32. Kai Xu, Vladimir G. Kim, Qixing Huang, Niloy J. Mitra, and Evangelos Kalogerakis. 2016. Data-Driven Shape Analysis and Processing. SIGGRAPH Asia Course (2016).Google Scholar
33. Li Yi, Vladimir G Kim, Duygu Ceylan, I Shen, Mengyan Yan, Hao Su, Cewu Lu, Qixing Huang, Alla Sheffer, and Leonidas Guibas. 2016. A scalable active framework for region annotation in 3D shape collections. TOG 35, 6 (2016), 210.Google ScholarDigital Library
34. Mehmet Ersin Yumer, Won Chun, and Ameesh Makadia. 2014. Co-segmentation of textured 3D shapes with sparse annotations. In 2014 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 240–247. Google ScholarDigital Library
35. Qingnan Zhou and Alec Jacobson. 2016. Thingi10K: A Dataset of 10,000 3D-Printing Models. (2016). arxiv:1605.04797.Google Scholar