
“Learning character-agnostic motion for motion retargeting in 2D” by Aberman, Wu, Lischinski, Chen and Cohen-Or
Conference:
Type(s):
Title:
- Learning character-agnostic motion for motion retargeting in 2D
Session/Category Title:
- Learning to Move
Presenter(s)/Author(s):
Abstract:
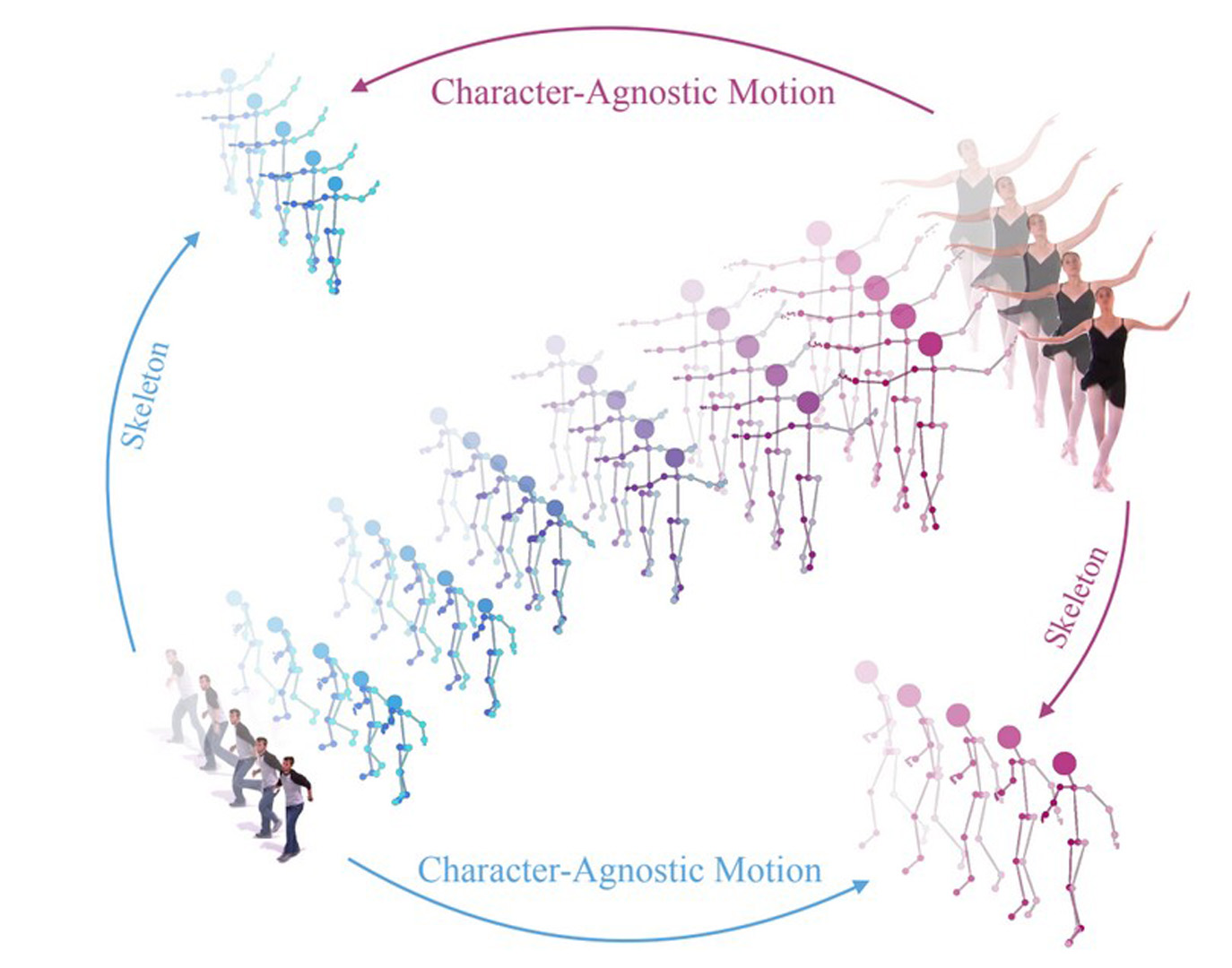
Analyzing human motion is a challenging task with a wide variety of applications in computer vision and in graphics. One such application, of particular importance in computer animation, is the retargeting of motion from one performer to another. While humans move in three dimensions, the vast majority of human motions are captured using video, requiring 2D-to-3D pose and camera recovery, before existing retargeting approaches may be applied. In this paper, we present a new method for retargeting video-captured motion between different human performers, without the need to explicitly reconstruct 3D poses and/or camera parameters.In order to achieve our goal, we learn to extract, directly from a video, a high-level latent motion representation, which is invariant to the skeleton geometry and the camera view. Our key idea is to train a deep neural network to decompose temporal sequences of 2D poses into three components: motion, skeleton, and camera view-angle. Having extracted such a representation, we are able to re-combine motion with novel skeletons and camera views, and decode a retargeted temporal sequence, which we compare to a ground truth from a synthetic dataset.We demonstrate that our framework can be used to robustly extract human motion from videos, bypassing 3D reconstruction, and outperforming existing retargeting methods, when applied to videos in-the-wild. It also enables additional applications, such as performance cloning, video-driven cartoons, and motion retrieval.
References:
1. Kfir Aberman, Mingyi Shi, Jing Liao, Dani Lischinski, Baoquan Chen, and Daniel Cohen-Or. 2018. Deep Video-Based Performance Cloning. arXiv preprint arXiv:1808.06847 (2018).Google Scholar
2. Adobe Systems Inc. 2018. Mixamo. https://www.mixamo.com. https://www.mixamo.com Accessed: 2018-12-27.Google Scholar
3. Andreas Aristidou, Daniel Cohen-Or, Jessica K. Hodgins, Yiorgos Chrysanthou, and Ariel Shamir. 2018. Deep Motifs and Motion Signatures. ACM Trans. Graph. 37, 6, Article 187 (Nov. 2018), 13 pages. Google ScholarDigital Library
4. Jürgen Bernard, Eduard Dobermann, Anna Vögele, Björn Krüger, Jörn Kohlhammer, and Dieter Fellner. 2017. Visual-interactive semi-supervised labeling of human motion capture data. Electronic Imaging 2017, 1 (2017), 34–45.Google ScholarCross Ref
5. Jürgen Bernard, Nils Wilhelm, Björn Krüger, Thorsten May, Tobias Schreck, and Jörn Kohlhammer. 2013. Motionexplorer: Exploratory search in human motion capture data based on hierarchical aggregation. IEEE TVCG 19, 12 (2013), 2257–2266. Google ScholarDigital Library
6. Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2016. Realtime multi-person 2d pose estimation using part affinity fields. arXiv preprint arXiv:1611.08050 (2016).Google Scholar
7. Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. 2018. Everybody dance now. arXiv preprint arXiv.1808.07371 (2018).Google Scholar
8. Songle Chen, Zhengxing Sun, and Yan Zhang. 2015. Scalable Organization of Collections of Motion Capture Data via Quantitative and Qualitative Analysis. In Proc. 5th ACM International Conference on Multimedia Retrieval. ACM, 411–418. Google ScholarDigital Library
9. Kwang-Jin Choi and Hyeong-Seok Ko. 2000. Online motion retargetting. The Journal of Visualization and Computer Animation 11, 5 (2000), 223–235.Google ScholarCross Ref
10. Michael Gleicher. 1998. Retargetting motion to new characters. In Proc. 25th annual conference on computer graphics and interactive techniques. ACM, 33–42. Google ScholarDigital Library
11. Daniel Holden, Jun Saito, and Taku Komura. 2016. A deep learning framework for character motion synthesis and editing. ACM Transactions on Graphics (TOG) 35, 4 (2016), 138. Google ScholarDigital Library
12. Daniel Holden, Jun Saito, Taku Komura, and Thomas Joyce. 2015. Learning motion manifolds with convolutional autoencoders. In SIGGRAPH Asia 2015 Technical Briefs. ACM, 18. Google ScholarDigital Library
13. Eugene Hsu, Kari Pulli, and Jovan Popović. 2005. Style translation for human motion. In ACM Transactions on Graphics (TOG), Vol. 24. ACM, 1082–1089. Google ScholarDigital Library
14. Yueqi Hu, Shuangyuan Wu, Shihong Xia, Jinghua Fu, and Wei Chen. 2010. Motion track: Visualizing variations of human motion data.. In PacificVis. 153–160.Google Scholar
15. Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. 2018. End-to-end recovery of human shape and pose. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Google ScholarCross Ref
16. Leonard Kaufman and Peter J Rousseeuw. 2009. Finding groups in data: an introduction to cluster analysis. Vol. 344. John Wiley & Sons.Google Scholar
17. Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv.1412.6980 (2014).Google Scholar
18. Lucas Kovar and Michael Gleicher. 2004. Automated extraction and parameterization of motions in large data sets. In ACM Transactions on Graphics (ToG), Vol. 23. ACM, 559–568. Google ScholarDigital Library
19. Tejas D Kulkarni, William F Whitney, Pushmeet Kohli, and Josh Tenenbaum. 2015. Deep convolutional inverse graphics network. In Advances in neural information processing systems. 2539–2547. Google ScholarDigital Library
20. Jehee Lee and Sung Yong Shin. 1999. A hierarchical approach to interactive motion editing for human-like figures. In Proc. 26th annual conference on computer graphics and interactive techniques. ACM Press/Addison-Wesley Publishing Co., 39–48. Google ScholarDigital Library
21. Lingjie Liu, Weipeng Xu, Michael Zollhoefer, Hyeongwoo Kim, Florian Bernard, Marc Habermann, Wenping Wang, and Christian Theobalt. 2018. Neural Animation and Reenactment of Human Actor Videos. arXiv preprint arXiv:1809.03658 (2018).Google Scholar
22. Liqian Ma, Qianru Sun, Stamatios Georgoulis, Luc Van Gool, Bernt Schiele, and Mario Fritz. 2018. Disentangled person image generation. In Proc. IEEE CVPR. 99–108.Google ScholarCross Ref
23. Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research 9, Nov (2008), 2579–2605.Google Scholar
24. Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, and Christian Theobalt. 2017. Vnect: Real-time 3d human pose estimation with a single rgb camera. ACM Transactions on Graphics (TOG) 36, 4 (2017), 44. Google ScholarDigital Library
25. Jianyuan Min, Huajun Liu, and Jinxiang Chai. 2010. Synthesis and editing of personalized stylistic human motion. In Proc. 2010 ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games. ACM, 39–46. Google ScholarDigital Library
26. Lee Montgomery. 2012. Tradigital Maya: A CG Animator’s Guide to Applying the Classical Principles of Animation. Focal Press.Google ScholarCross Ref
27. Meinard Müller, Andreas Baak, and Hans-Peter Seidel. 2009. Efficient and robust annotation of motion capture data. In Proc. 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation. ACM, 17–26. Google ScholarDigital Library
28. Augustus Odena, Vincent Dumoulin, and Chris Olah. 2016. Deconvolution and Checker-board Artifacts. Distill (2016).Google Scholar
29. Xi Peng, Xiang Yu, Kihyuk Sohn, Dimitris N Metaxas, and Manmohan Chandraker. 2017. Reconstruction-based disentanglement for pose-invariant face recognition. intervals 20 (2017), 12.Google Scholar
30. Xue Bin Peng, Angjoo Kanazawa, Jitendra Malik, Pieter Abbeel, and Sergey Levine. 2018. SFV: reinforcement learning of physical skills from videos. ACM Trans. Graph. 37, 6 (November 2018), Article 178.Google ScholarDigital Library
31. Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. 2018. On the convergence of adam and beyond. (2018).Google Scholar
32. Charles F Rose III, Peter-Pike J Sloan, and Michael F Cohen. 2001. Artist-directed inverse-kinematics using radial basis function interpolation. In Computer Graphics Forum, Vol. 20. Wiley Online Library, 239–250.Google Scholar
33. Tomas Simon, Hanbyul Joo, Iain Matthews, and Yaser Sheikh. 2017. Hand Keypoint Detection in Single Images using Multiview Bootstrapping. In CVPR.Google Scholar
34. Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. 2012. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012).Google Scholar
35. Seyoon Tak and Hyeong-Seok Ko. 2005. A physically-based motion retargeting filter. ACM Transactions on Graphics (TOG) 24, 1 (2005), 98–117. Google ScholarDigital Library
36. Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. 2017. Mocogan: Decomposing motion and content for video generation. arXiv preprint arXiv:1707.04993 (2017).Google Scholar
37. Ruben Villegas, Jimei Yang, Duygu Ceylan, and Honglak Lee. 2018. Neural Kinematic Networks for Unsupervised Motion Retargetting. In Proc. IEEE CVPR. 8639–8648.Google ScholarCross Ref
38. Shuangyuan Wu, Zhaoqi Wang, and Shihong Xia. 2009. Indexing and retrieval of human motion data by a hierarchical tree. In Proc. 16th ACM Symposium on Virtual Reality Software and Technology. ACM, 207–214. Google ScholarDigital Library
39. Shihong Xia, Congyi Wang, Jinxiang Chai, and Jessica Hodgins. 2015. Realtime style transfer for unlabeled heterogeneous human motion. ACM Transactions on Graphics (TOG) 34, 4 (2015), 119. Google ScholarDigital Library
40. Weiyu Zhang, Menglong Zhu, and Konstantinos G Derpanis. 2013. From actemes to action: A strongly-supervised representation for detailed action understanding. In Proceedings of the IEEE International Conference on Computer Vision. 2248–2255. Google ScholarDigital Library