
“Flexible Motion In-betweening With Diffusion Models”
Conference:
Type(s):
Title:
- Flexible Motion In-betweening With Diffusion Models
Presenter(s)/Author(s):
Abstract:
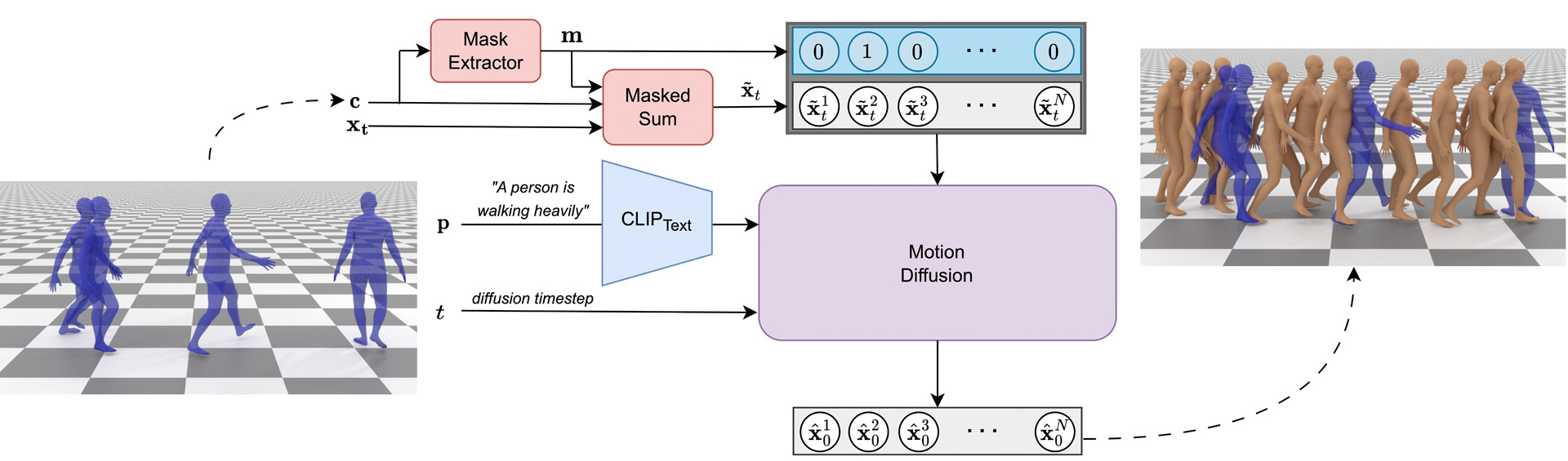
We introduce CondMDI, a simple and unified diffusion-based approach for text and keyframe guided motion in-betweening. CondMDI accommodates flexible keyframe placements and partial keyframes, generating high-quality and diverse motions coherent with the input constraints. Evaluation on the HumanML3D dataset showcases CondMDI’s effectiveness on a diverse set of motion in-betweening tasks.
References:
[1]
Adobe Systems Inc.2021. Mixamo. https://www.mixamo.com Accessed: 2021-12-25.
[2]
Hyemin Ahn, Timothy Ha, Yunho Choi, Hwiyeon Yoo, and Songhwai Oh. 2018. Text2action: Generative adversarial synthesis from language to action. In 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 5915?5920.
[3]
Chaitanya Ahuja and Louis-Philippe Morency. 2019. Language2pose: Natural language grounded pose forecasting. In 2019 International Conference on 3D Vision (3DV). IEEE, 719?728.
[4]
Emre Aksan, Manuel Kaufmann, and Otmar Hilliges. 2019. Structured prediction helps 3d human motion modelling. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7144?7153.
[5]
Okan Arikan and David A Forsyth. 2002. Interactive motion generation from examples. ACM Transactions on Graphics (TOG) 21, 3 (2002), 483?490.
[6]
Okan Arikan, David A Forsyth, and James F O?Brien. 2003. Motion synthesis from annotations. In ACM SIGGRAPH 2003 Papers. 402?408.
[7]
Philippe Beaudoin, Stelian Coros, Michiel Van de Panne, and Pierre Poulin. 2008. Motion-motif graphs. In Proceedings of the 2008 ACM SIGGRAPH/Eurographics symposium on computer animation. 117?126.
[8]
Uttaran Bhattacharya, Nicholas Rewkowski, Abhishek Banerjee, Pooja Guhan, Aniket Bera, and Dinesh Manocha. 2021. Text2gestures: A transformer-based network for generating emotive body gestures for virtual agents. In 2021 IEEE virtual reality and 3D user interfaces (VR). IEEE, 1?10.
[9]
Michael B?ttner and Simon Clavet. 2015. Motion matching-the road to next gen animation. Proc. of Nucl. ai 1, 2015 (2015), 2.
[10]
Jinxiang Chai and Jessica K Hodgins. 2007. Constraint-based motion optimization using a statistical dynamic model. In ACM SIGGRAPH 2007 papers. 8?es.
[11]
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. 2023. Executing your Commands via Motion Diffusion in Latent Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18000?18010.
[12]
Rishabh Dabral, Muhammad Hamza Mughal, Vladislav Golyanik, and Christian Theobalt. 2023. Mofusion: A framework for denoising-diffusion-based motion synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9760?9770.
[13]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis. Advances in neural information processing systems 34 (2021), 8780?8794.
[14]
Laurent Dinh, David Krueger, and Yoshua Bengio. 2014. Nice: Non-linear independent components estimation. arXiv preprint arXiv:1410.8516 (2014).
[15]
Yinglin Duan, Tianyang Shi, Zhengxia Zou, Yenan Lin, Zhehui Qian, Bohan Zhang, and Yi Yuan. 2021. Single-shot motion completion with transformer. arXiv preprint arXiv:2103.00776 (2021).
[16]
Katerina Fragkiadaki, Sergey Levine, Panna Felsen, and Jitendra Malik. 2015. Recurrent network models for human dynamics. In Proceedings of the IEEE international conference on computer vision. 4346?4354.
[17]
Anindita Ghosh, Noshaba Cheema, Cennet Oguz, Christian Theobalt, and Philipp Slusallek. 2021. Synthesis of compositional animations from textual descriptions. In Proceedings of the IEEE/CVF international conference on computer vision. 1396?1406.
[18]
Partha Ghosh, Jie Song, Emre Aksan, and Otmar Hilliges. 2017. Learning human motion models for long-term predictions. In 2017 International Conference on 3D Vision (3DV). IEEE, 458?466.
[19]
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. 2022. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5152?5161.
[20]
Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong, and Li Cheng. 2020. Action2motion: Conditioned generation of 3d human motions. In Proceedings of the 28th ACM International Conference on Multimedia. 2021?2029.
[21]
F?lix G Harvey and Christopher Pal. 2018. Recurrent transition networks for character locomotion. In SIGGRAPH Asia 2018 Technical Briefs. 1?4.
[22]
F?lix G Harvey, Mike Yurick, Derek Nowrouzezahrai, and Christopher Pal. 2020. Robust motion in-betweening. ACM Transactions on Graphics (TOG) 39, 4 (2020), 60?1.
[23]
William Harvey, Saeid Naderiparizi, Vaden Masrani, Christian Weilbach, and Frank Wood. 2022. Flexible diffusion modeling of long videos. Advances in Neural Information Processing Systems 35 (2022), 27953?27965.
[24]
Chengan He, Jun Saito, James Zachary, Holly Rushmeier, and Yi Zhou. 2022. Nemf: Neural motion fields for kinematic animation. Advances in Neural Information Processing Systems 35 (2022), 4244?4256.
[25]
Gustav Eje Henter, Simon Alexanderson, and Jonas Beskow. 2020. Moglow: Probabilistic and controllable motion synthesis using normalising flows. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1?14.
[26]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840?6851.
[27]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. 2022. Video Diffusion Models. arxiv:2204.03458 [cs.CV]
[28]
Daniel Holden, Jun Saito, and Taku Komura. 2016. A deep learning framework for character motion synthesis and editing. ACM Transactions on Graphics (TOG) 35, 4 (2016), 1?11.
[29]
Daniel Holden, Jun Saito, Taku Komura, and Thomas Joyce. 2015. Learning motion manifolds with convolutional autoencoders. In SIGGRAPH Asia 2015 technical briefs. 1?4.
[30]
Eugene Hsu, Sommer Gentry, and Jovan Popovi?. 2004. Example-based control of human motion. In Proceedings of the 2004 ACM SIGGRAPH/Eurographics symposium on Computer animation. 69?77.
[31]
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. 2022. Planning with diffusion for flexible behavior synthesis. arXiv preprint arXiv:2205.09991 (2022).
[32]
Roy Kapon, Guy Tevet, Daniel Cohen-Or, and Amit H Bermano. 2023. MAS: Multi-view Ancestral Sampling for 3D motion generation using 2D diffusion. arXiv preprint arXiv:2310.14729 (2023).
[33]
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. 2023a. GMD: Controllable Human Motion Synthesis via Guided Diffusion Models. arXiv preprint arXiv:2305.12577 (2023).
[34]
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. 2023b. Guided Motion Diffusion for Controllable Human Motion Synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2151?2162.
[35]
Jihoon Kim, Jiseob Kim, and Sungjoon Choi. 2022. FLAME: Free-form Language-based Motion Synthesis & Editing. arXiv preprint arXiv:2209.00349 (2022).
[36]
Lucas Kovar and Michael Gleicher. 2004. Automated extraction and parameterization of motions in large data sets. ACM Transactions on Graphics (ToG) 23, 3 (2004), 559?568.
[37]
Lucas Kovar, Michael Gleicher, and Fr?d?ric Pighin. 2002. Motion graphs. Vol. 21. 473?482.
[38]
Jehee Lee, Jinxiang Chai, Paul SA Reitsma, Jessica K Hodgins, and Nancy S Pollard. 2002. Interactive control of avatars animated with human motion data. In Proceedings of the 29th annual conference on Computer graphics and interactive techniques. 491?500.
[39]
Jehee Lee and Kang Hoon Lee. 2004. Precomputing avatar behavior from human motion data. In Proceedings of the 2004 ACM SIGGRAPH/Eurographics symposium on Computer animation. 79?87.
[40]
Sergey Levine, Jack M Wang, Alexis Haraux, Zoran Popovi?, and Vladlen Koltun. 2012. Continuous character control with low-dimensional embeddings. ACM Transactions on Graphics (TOG) 31, 4 (2012), 1?10.
[41]
Jiaman Li, Ruben Villegas, Duygu Ceylan, Jimei Yang, Zhengfei Kuang, Hao Li, and Yajie Zhao. 2021. Task-generic hierarchical human motion prior using vaes. In 2021 International Conference on 3D Vision (3DV). IEEE, 771?781.
[42]
Zimo Li, Yi Zhou, Shuangjiu Xiao, Chong He, Zeng Huang, and Hao Li. 2017. Auto-conditioned recurrent networks for extended complex human motion synthesis. arXiv preprint arXiv:1707.05363 (2017).
[43]
Han Liang, Wenqian Zhang, Wenxuan Li, Jingyi Yu, and Lan Xu. 2023. InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions. arXiv preprint arXiv:2304.05684 (2023).
[44]
Hung Yu Ling, Fabio Zinno, George Cheng, and Michiel Van De Panne. 2020. Character controllers using motion vaes. ACM Transactions on Graphics (TOG) 39, 4 (2020), 40?1.
[45]
Wan-Yen Lo and Matthias Zwicker. 2008. Real-time planning for parameterized human motion. In Proceedings of the 2008 ACM SIGGRAPH/Eurographics Symposium on Computer Animation. 29?38.
[46]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11461?11471.
[47]
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. 2019a. AMASS: Archive of Motion Capture as Surface Shapes. In International Conference on Computer Vision. 5442?5451.
[48]
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. 2019b. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF international conference on computer vision. 5442?5451.
[49]
James McCann and Nancy Pollard. 2007. Responsive characters from motion fragments. In ACM SIGGRAPH 2007 papers. 6?es.
[50]
Jianyuan Min and Jinxiang Chai. 2012. Motion graphs++ a compact generative model for semantic motion analysis and synthesis. ACM Transactions on Graphics (TOG) 31, 6 (2012), 1?12.
[51]
Tomohiko Mukai and Shigeru Kuriyama. 2005. Geostatistical motion interpolation. In ACM SIGGRAPH 2005 Papers. 1062?1070.
[52]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021).
[53]
Boris N Oreshkin, Antonios Valkanas, F?lix G Harvey, Louis-Simon M?nard, Florent Bocquelet, and Mark J Coates. 2023. Motion In-Betweening via Deep ? -Interpolator. IEEE Transactions on Visualization and Computer Graphics (2023).
[54]
Katherine Pullen and Christoph Bregler. 2002. Motion capture assisted animation: Texturing and synthesis. In Proceedings of the 29th annual conference on Computer graphics and interactive techniques. 501?508.
[55]
Jia Qin, Youyi Zheng, and Kun Zhou. 2022. Motion in-betweening via two-stage transformers. ACM Transactions on Graphics (TOG) 41, 6 (2022), 1?16.
[56]
Sigal Raab, Inbal Leibovitch, Guy Tevet, Moab Arar, Amit H Bermano, and Daniel Cohen-Or. 2023. Single Motion Diffusion. arXiv preprint arXiv:2302.05905 (2023).
[57]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748?8763.
[58]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1, 2 (2022), 3.
[59]
Charles Rose, Michael F Cohen, and Bobby Bodenheimer. 1998. Verbs and adverbs: Multidimensional motion interpolation. IEEE Computer Graphics and Applications 18, 5 (1998), 32?40.
[60]
Charles F Rose III, Peter-Pike J Sloan, and Michael F Cohen. 2001. Artist-directed inverse-kinematics using radial basis function interpolation. In Computer graphics forum, Vol. 20. Wiley Online Library, 239?250.
[61]
Alla Safonova and Jessica K Hodgins. 2007. Construction and optimal search of interpolated motion graphs. In ACM SIGGRAPH 2007 papers. 106?es.
[62]
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. 2022a. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 conference proceedings. 1?10.
[63]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, 2022b. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems 35 (2022), 36479?36494.
[64]
Yonatan Shafir, Guy Tevet, Roy Kapon, and Amit H Bermano. 2023. Human motion diffusion as a generative prior. arXiv preprint arXiv:2303.01418 (2023).
[65]
Yijun Shen, He Wang, Edmond SL Ho, Longzhi Yang, and Hubert PH Shum. 2017. Posture-based and action-based graphs for boxing skill visualization. Computers & Graphics 69 (2017), 104?115.
[66]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning. PMLR, 2256?2265.
[67]
Yang Song and Stefano Ermon. 2019. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems 32 (2019).
[68]
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. 2023. Human Motion Diffusion Model. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=SJ1kSyO2jwu
[69]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ?ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
[70]
Hongsong Wang, Liang Wang, Jiashi Feng, and Daquan Zhou. 2022. Velocity-to-velocity human motion forecasting. Pattern Recognition 124 (2022), 108424.
[71]
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. 2023. OmniControl: Control Any Joint at Any Time for Human Motion Generation. arXiv preprint arXiv:2310.08580 (2023).
[72]
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. 2023. Physdiff: Physics-guided human motion diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 16010?16021.
[73]
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. 2023. T2m-gpt: Generating human motion from textual descriptions with discrete representations. arXiv preprint arXiv:2301.06052 (2023).
[74]
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. 2022. Motiondiffuse: Text-driven human motion generation with diffusion model. arXiv preprint arXiv:2208.15001 (2022).
[75]
Xinyi Zhang and Michiel van de Panne. 2018. Data-driven autocompletion for keyframe animation. In Proceedings of the 11th ACM SIGGRAPH Conference on Motion, Interaction and Games. 1?11.
[76]
Yi Zhou, Jingwan Lu, Connelly Barnes, Jimei Yang, Sitao Xiang, 2020. Generative tweening: Long-term inbetweening of 3d human motions. arXiv preprint arXiv:2005.08891 (2020).