
“Efficient Video Portrait Reenactment via Grid-based Codebook” by Wang, Zhou, Wu, Tang, Xu, et al. …

Conference:
Type(s):
Title:
- Efficient Video Portrait Reenactment via Grid-based Codebook
Session/Category Title:
- Making Faces With Neural Avatars
Presenter(s)/Author(s):
- Kaisiyuan Wang
- Hang Zhou
- Qianyi Wu
- Jiaxiang Tang
- Zhiliang Xu
- Borong Liang
- Tianshu Hu
- Errui Ding
- Jingtuo Liu
- Ziwei Liu
- Jingdong Wang
Moderator(s):
Abstract:
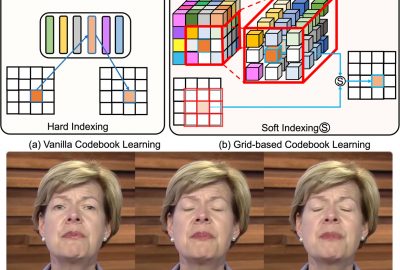
While progress has been made in the field of portrait reenactment, the problem of how to efficiently produce high-fidelity and accurate videos remains. Recent studies build direct mappings between driving signals and their predictions, leading to failure cases when synthesizing background textures and detailed local motions. In this paper, we propose the Video Portrait via Grid-based Codebook (VPGC) framework, which achieves efficient and high-fidelity portrait modeling. Our key insight is to query driving signals in a position-aware textural codebook with an explicit grid structure. The grid-based codebook stores delicate textural information locally according to our observations on video portraits, which can be learned efficiently and precisely. We subsequently design a Prior-Guided Driving Module to predict reliable features from the driving signals, which can be later decoded back to high-quality video portraits by querying the codebook. Comprehensive experiments are conducted to validate the effectiveness of our approach.
References:
1. Volker Blanz and Thomas Vetter. 1999. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques. 187–194.
2. Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T Freeman, Michael Rubinstein, 2023. Muse: Text-To-Image Generation via Masked Generative Transformers. arXiv preprint arXiv:2301.00704 (2023).
3. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. 2022. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11315–11325.
4. Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. 2022. Tensorf: Tensorial radiance fields. In Proceedings of the European Conference on Computer Vision. 333–350.
5. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, 2021. An image is worth 16×16 words: Transformers for image recognition at scale. In International Conference on Learning Representations.
6. Michail Christos Doukas, Stefanos Zafeiriou, and Viktoriia Sharmanska. 2021. HeadGAN: One-shot Neural Head Synthesis and Editing. In IEEE/CVF International Conference on Computer Vision.
7. Nikita Drobyshev, Jenya Chelishev, Taras Khakhulin, Aleksei Ivakhnenko, Victor Lempitsky, and Egor Zakharov. 2022. MegaPortraits: One-shot Megapixel Neural Head Avatars. Proceedings of the 30th ACM International Conference on Multimedia.
8. Patrick Esser, Robin Rombach, Andreas Blattmann, and Bjorn Ommer. 2021b. Imagebart: Bidirectional context with multinomial diffusion for autoregressive image synthesis. Advances in Neural Information Processing Systems 34 (2021).
9. Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021a. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12873–12883.
10. Yao Feng, Haiwen Feng, Michael J. Black, and Timo Bolkart. 2021. Learning an Animatable Detailed 3D Face Model from In-The-Wild Images. ACM Transactions on Graphics 40, 8. https://doi.org/10.1145/3450626.3459936
11. Guy Gafni, Justus Thies, Michael Zollhofer, and Matthias Nießner. 2021. Dynamic neural radiance fields for monocular 4d facial avatar reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8649–8658.
12. Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
13. Philip-William Grassal, Malte Prinzler, Titus Leistner, Carsten Rother, Matthias Nießner, and Justus Thies. 2022. Neural head avatars from monocular RGB videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18653–18664.
14. Yuchao Gu, Xintao Wang, Liangbin Xie, Chao Dong, Gen Li, Ying Shan, and Ming-Ming Cheng. 2022. VQFR: Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder. In Proceedings of the European Conference on Computer Vision.
15. Yudong Guo, Keyu Chen, Sen Liang, Yongjin Liu, Hujun Bao, and Juyong Zhang. 2021. AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis. In IEEE/CVF International Conference on Computer Vision.
16. Xinya Ji, Hang Zhou, Kaisiyuan Wang, Qianyi Wu, Wayne Wu, Feng Xu, and Xun Cao. 2022. EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model. In ACM SIGGRAPH 2022 Conference Proceedings(SIGGRAPH ’22). https://doi.org/10.1145/3528233.3530745
17. Xinya Ji, Hang Zhou, Kaisiyuan Wang, Wayne Wu, Chen Change Loy, Xun Cao, and Feng Xu. 2021. Audio-driven emotional video portraits. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14080–14089.
18. Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision. Springer, 694–711.
19. Taras Khakhulin, Vanessa Sklyarova, Victor Lempitsky, and Egor Zakharov. 2022. Realistic one-shot mesh-based head avatars. In Proceedings of the European Conference on Computer Vision. Springer, 345–362.
20. Hyeongwoo Kim, Mohamed Elgharib, Michael Zollhöfer, Hans-Peter Seidel, Thabo Beeler, Christian Richardt, and Christian Theobalt. 2019. Neural style-preserving visual dubbing. ACM Transactions on Graphics 38, 6 (2019), 1–13.
21. Hyeongwoo Kim, Pablo Garrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Niessner, Patrick Pérez, Christian Richardt, Michael Zollhöfer, and Christian Theobalt. 2018. Deep video portraits. ACM Transactions on Graphics 37, 4 (2018), 1–14.
22. Xian Liu, Qianyi Wu, Hang Zhou, Yuanqi Du, Wayne Wu, Dahua Lin, and Ziwei Liu. 2022. Audio-Driven Co-Speech Gesture Video Generation. Advances in Neural Information Processing Systems (2022).
23. Yuanxun Lu, Jinxiang Chai, and Xun Cao. 2021. Live speech portraits: real-time photorealistic talking-head animation. ACM Transactions on Graphics 40, 6 (2021), 1–17.
24. Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. Nerf: Representing scenes as neural radiance fields for view synthesis. In Proceedings of the European Conference on Computer Vision. Springer, 405–421.
25. Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics 41, 4 (2022), 1–15.
26. Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019. First order motion model for image animation. Advances in Neural Information Processing Systems 32 (2019), 7137–7147.
27. Cheng Sun, Min Sun, and Hwann-Tzong Chen. 2022a. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5459–5469.
28. Yasheng Sun, Hang Zhou, Kaisiyuan Wang, Qianyi Wu, Zhibin Hong, Jingtuo Liu, Errui Ding, Jingdong Wang, Ziwei Liu, and Koike Hideki. 2022b. Masked Lip-Sync Prediction by Audio-Visual Contextual Exploitation in Transformers. In SIGGRAPH Asia 2022 Conference Papers. 1–9.
29. Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. 2017. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics 36, 4 (2017), 1–13.
30. Jiaxiang Tang, Kaisiyuan Wang, Hang Zhou, Xiaokang Chen, Dongliang He, Tianshu Hu, Jingtuo Liu, Gang Zeng, and Jingdong Wang. 2022. Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition. arXiv preprint arXiv:2211.12368 (2022).
31. Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Nießner. 2016. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2387–2395.
32. Aaron Van Den Oord, Oriol Vinyals, 2017. Neural discrete representation learning. Advances in Neural Information Processing Systems 30 (2017).
33. Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. 2020. MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation. In ECCV.
34. Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. 2018. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
35. Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. 2021. One-shot free-view neural talking-head synthesis for video conferencing. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10039–10049.
36. Yaohui Wang, Di Yang, Francois Bremond, and Antitza Dantcheva. 2022. Latent Image Animator: Learning to Animate Images via Latent Space Navigation. In International Conference on Learning Representations.
37. Wayne Wu, Yunxuan Zhang, Cheng Li, Chen Qian, and Chen Change Loy. 2018. Reenactgan: Learning to reenact faces via boundary transfer. In Proceedings of the European Conference on Computer Vision. 603–619.
38. Kewei Yang, Kang Chen, Daoliang Guo, Song-Hai Zhang, Yuan-Chen Guo, and Weidong Zhang. 2022. Face2Face ρ : Real-Time High-Resolution One-Shot Face Reenactment. In Proceedings of the European Conference on Computer Vision. Springer, 55–71.
39. Fei Yin, Yong Zhang, Xiaodong Cun, Mingdeng Cao, Yanbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, and Yujiu Yang. 2022. StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN. In Proceedings of the European Conference on Computer Vision.
40. Egor Zakharov, Aleksei Ivakhnenko, Aliaksandra Shysheya, and Victor Lempitsky. 2020. Fast Bi-layer Neural Synthesis of One-Shot Realistic Head Avatars. In Proceedings of the European Conference on Computer Vision. Springer, 524–540.
41. Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, and Victor Lempitsky. 2019. Few-shot adversarial learning of realistic neural talking head models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 9459–9468.
42. Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. 2021. Flow-Guided One-Shot Talking Face Generation With a High-Resolution Audio-Visual Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3661–3670.
43. Chuanxia Zheng, Tat-Jen Cham, Jianfei Cai, and Dinh Phung. 2022b. Bridging Global Context Interactions for High-Fidelity Image Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11512–11522.
44. Yufeng Zheng, Victoria Fernández Abrevaya, Marcel C Bühler, Xu Chen, Michael J Black, and Otmar Hilliges. 2022a. Im avatar: Implicit morphable head avatars from videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13545–13555.
45. Hang Zhou, Yu Liu, Ziwei Liu, Ping Luo, and Xiaogang Wang. 2019. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 9299–9306.
46. Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu. 2021. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4176–4186.
47. Shangchen Zhou, Kelvin Chan, Chongyi Li, and Chen Change Loy. 2022. Towards robust blind face restoration with codebook lookup transformer. Advances in Neural Information Processing Systems 35 (2022), 30599–30611.
Additional Images:
-
- 2023 Technical Papers: Wang_Efficient Video Portrait Reenactment via Grid-based Codebook
