
“Disentangled Phoneme-Prosody Mapping for Controllable 3D Facial Animation” by Serrano and Musialski
Conference:
Type(s):
Title:
- Disentangled Phoneme-Prosody Mapping for Controllable 3D Facial Animation
Session/Category Title:
- Animation & Simulation
Presenter(s)/Author(s):
Abstract:
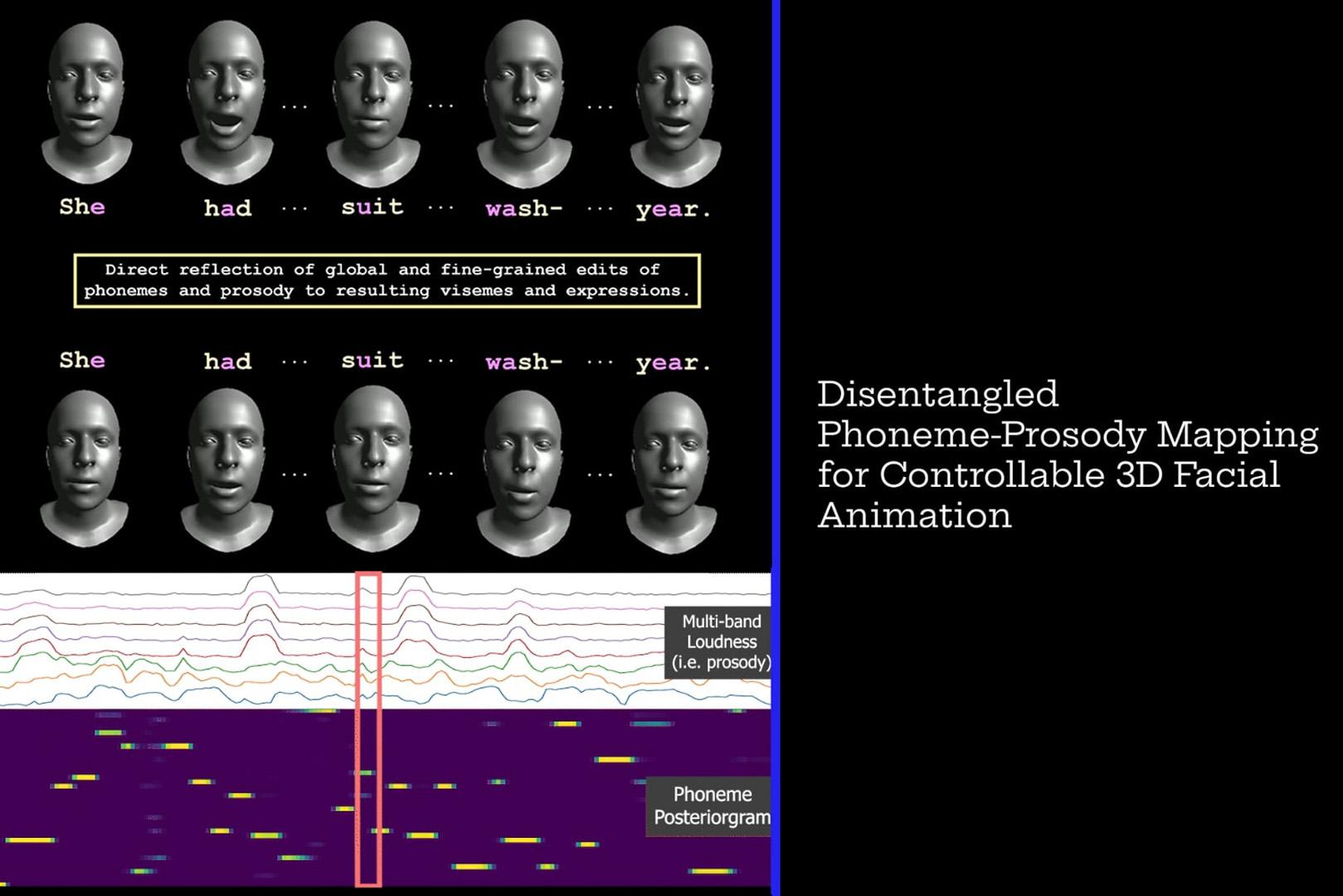
Speech driven 3D face animation driven by disentangled phoneme and prosody features, enabling fine-grained and intuitive control over visemes and expressions—uses a convolutional autoencoder to learn a relative motion prior and a transformer to map these interpretable audio features into latent deformations.
References:
[1] Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, and Matthias Nießner. 2024. GaussianSpeech: Audio-Driven Gaussian Avatars. arxiv:https://arXiv.org/abs/2411.18675 [cs.CV] https://arxiv.org/abs/2411.18675
[2] Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Advances in Neural Information Processing Systems 33 (NeurIPS 2020).
[3] Cameron Churchwell, Max Morrison, and Bryan Pardo. 2024. High-Fidelity Neural Phonetic Posteriorgrams. arxiv:https://arXiv.org/abs/2402.17735 [eess.AS] https://arxiv.org/abs/2402.17735
[4] Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, and Michael Black. 2019. Capture, Learning, and Synthesis of 3D Speaking Styles. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). 10101–10111. http://voca.is.tue.mpg.de/
[5] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. arXiv preprint arXiv:https://arXiv.org/abs/2106.07447 (2021).
[6] Zeynep Inanoglu and Steve J Young. 2007. A system for transforming the emotion in speech: combining data-driven conversion techniques for prosody and voice quality. In INTERSPEECH. 490–493.
[7] Max Morrison, Cameron Churchwell, Nathan Pruyne, and Bryan Pardo. 2024a. Fine-Grained and Interpretable Neural Speech Editing. arxiv:https://arXiv.org/abs/2407.05471 [eess.AS] https://arxiv.org/abs/2407.05471
[8] Max Morrison, Caedon Hsieh, Nathan Pruyne, and Bryan Pardo. 2024b. Cross-domain Neural Pitch and Periodicity Estimation. arxiv:https://arXiv.org/abs/2301.12258 [eess.AS] https://arxiv.org/abs/2301.12258
[9] Qingcheng Zhao, Pengyu Long, Qixuan Zhang, Dafei Qin, Han Liang, Longwen Zhang, Yingliang Zhang, Jingyi Yu, and Lan Xu. 2024. Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance. arxiv:https://arXiv.org/abs/2401.15687 [cs.CV] https://arxiv.org/abs/2401.15687