
“Capturing detailed deformations of moving human bodies” by Chen, Park, Macit and Kavan
Conference:
Type(s):
Title:
- Capturing detailed deformations of moving human bodies
Presenter(s)/Author(s):
Abstract:
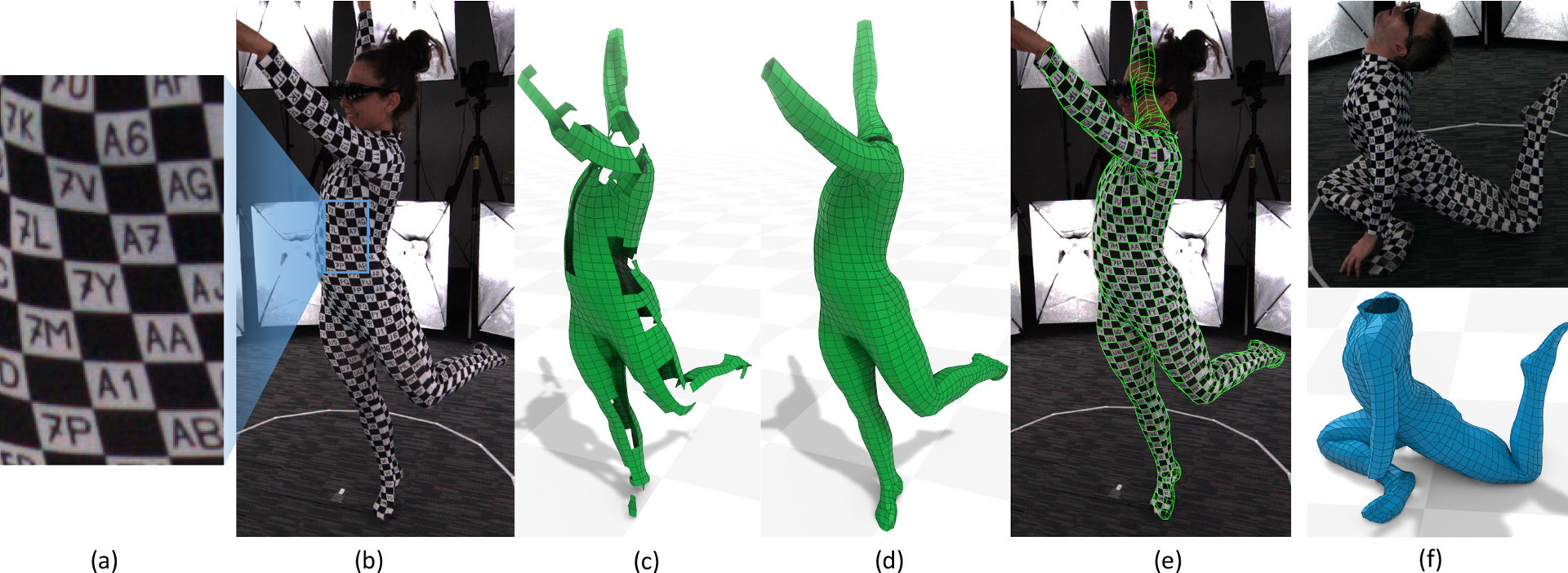
We present a new method to capture detailed human motion, sampling more than 1000 unique points on the body. Our method outputs highly accurate 4D (spatio-temporal) point coordinates and, crucially, automatically assigns a unique label to each of the points. The locations and unique labels of the points are inferred from individual 2D input images only, without relying on temporal tracking or any human body shape or skeletal kinematics models. Therefore, our captured point trajectories contain all of the details from the input images, including motion due to breathing, muscle contractions and flesh deformation, and are well suited to be used as training data to fit advanced models of the human body and its motion. The key idea behind our system is a new type of motion capture suit which contains a special pattern with checkerboard-like corners and two-letter codes. The images from our multi-camera system are processed by a sequence of neural networks which are trained to localize the corners and recognize the codes, while being robust to suit stretching and self-occlusions of the body. Our system relies only on standard RGB or monochrome sensors and fully passive lighting and the passive suit, making our method easy to replicate, deploy and use. Our experiments demonstrate highly accurate captures of a wide variety of human poses, including challenging motions such as yoga, gymnastics, or rolling on the ground.
References:
1. Mart?n Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Man?, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Vi?gas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2015. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. https://www.tensorflow.org/ Software available from tensorflow.org.Google Scholar
2. Sameer Agarwal and Keir Mierle. 2012. Ceres solver: Tutorial & reference. Google Inc 2 (2012), 72.Google Scholar
3. Benjamin Allain, Jean-S?bastien Franco, and Edmond Boyer. 2015. An efficient volumetric framework for shape tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 268–276.Google ScholarCross Ref
4. Brett Allen, Brian Curless, Brian Curless, and Zoran Popovi?. 2003. The space of human body shapes: reconstruction and parameterization from range scans. In ACM transactions on graphics (TOG), Vol. 22. ACM, 587–594.Google Scholar
5. Dragomir Anguelov, Praveen Srinivasan, Daphne Koller, Sebastian Thrun, Jim Rodgers, and James Davis. 2005. Scape: shape completion and animation of people. In ACM Transactions on Graphics (TOG), Vol. 24. ACM, 408–416.Google ScholarDigital Library
6. Andreas Aristidou, Daniel Cohen-Or, Jessica K Hodgins, and Ariel Shamir. 2018. Self-similarity analysis for motion capture cleaning. In Computer Graphics Forum, Vol. 37. Wiley Online Library, 297–309.Google Scholar
7. Angelos Barmpoutis. 2013. Tensor body: Real-time reconstruction of the human body and avatar synthesis from RGB-D. IEEE transactions on cybernetics 43, 5 (2013), 1347–1356.Google Scholar
8. Stuart Bennett and Joan Lasenby. 2014. ChESS-Quick and robust detection of chessboard features. Computer Vision and Image Understanding 118 (2014), 197–210.Google ScholarDigital Library
9. Federica Bogo, Michael J Black, Matthew Loper, and Javier Romero. 2015. Detailed full-body reconstructions of moving people from monocular RGB-D sequences. In Proceedings of the IEEE International Conference on Computer Vision. 2300–2308.Google ScholarDigital Library
10. Federica Bogo, Javier Romero, Matthew Loper, and Michael J Black. 2014. FAUST: Dataset and evaluation for 3D mesh registration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3794–3801.Google ScholarDigital Library
11. Federica Bogo, Javier Romero, Gerard Pons-Moll, and Michael J Black. 2017. Dynamic FAUST: Registering human bodies in motion. In Proceedings of the IEEE conference on computer vision and pattern recognition. 6233–6242.Google ScholarCross Ref
12. Adnane Boukhayma, Vagia Tsiminaki, Jean-S?bastien Franco, and Edmond Boyer. 2016. Eigen appearance maps of dynamic shapes. In European Conference on Computer Vision. Springer, 230–245.Google ScholarCross Ref
13. G. Bradski. 2000. The OpenCV Library. Dr. Dobb’s Journal of Software Tools (2000).Google Scholar
14. Gary Bradski and Adrian Kaehler. 2008. Learning OpenCV: Computer vision with the OpenCV library. ” O’Reilly Media, Inc.”.Google Scholar
15. Christoph Bregler, Jitendra Malik, and Katherine Pullen. 2004. Twist based acquisition and tracking of animal and human kinematics. International Journal of Computer Vision 56, 3 (2004), 179–194.Google ScholarDigital Library
16. Thomas Brox, Bodo Rosenhahn, Juergen Gall, and Daniel Cremers. 2009. Combined region and motion-based 3D tracking of rigid and articulated objects. IEEE transactions on pattern analysis and machine intelligence 32, 3 (2009), 402–415.Google Scholar
17. Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2018. OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. arXiv preprint arXiv:1812.08008 (2018).Google Scholar
18. Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2017. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7291–7299.Google ScholarCross Ref
19. Dan Casas, Margara Tejera, Jean-Yves Guillemaut, and Adrian Hilton. 2012. 4D parametric motion graphs for interactive animation. In Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games. 103–110.Google ScholarDigital Library
20. Ben Chen, Caihua Xiong, and Qi Zhang. 2018. CCDN: Checkerboard corner detection network for robust camera calibration. In International Conference on Intelligent Robotics and Applications. Springer, 324–334.Google ScholarCross Ref
21. Vasileios Choutas, Georgios Pavlakos, Timo Bolkart, Dimitrios Tzionas, and Michael J Black. 2020. Monocular expressive body regression through body-driven attention. arXiv preprint arXiv:2008.09062 (2020).Google Scholar
22. Alvaro Collet, Ming Chuang, Pat Sweeney, Don Gillett, Dennis Evseev, David Calabrese, Hugues Hoppe, Adam Kirk, and Steve Sullivan. 2015. High-quality streamable free-viewpoint video. ACM Transactions on Graphics (ToG) 34, 4 (2015), 1–13.Google ScholarDigital Library
23. Stefano Corazza, Lars M?ndermann, Emiliano Gambaretto, Giancarlo Ferrigno, and Thomas P Andriacchi. 2010. Markerless motion capture through visual hull, articulated icp and subject specific model generation. International journal of computer vision 87, 1-2 (2010), 156–169.Google ScholarDigital Library
24. Edilson De Aguiar, Carsten Stoll, Christian Theobalt, Naveed Ahmed, Hans-Peter Seidel, and Sebastian Thrun. 2008. Performance capture from sparse multi-view video. In ACM SIGGRAPH 2008 papers. 1–10.Google ScholarDigital Library
25. Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. 2018. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 224–236.Google ScholarCross Ref
26. Simon Donn?, Jonas De Vylder, Bart Goossens, and Wilfried Philips. 2016. MATE: Machine learning for adaptive calibration template detection. Sensors 16, 11 (2016), 1858.Google ScholarCross Ref
27. Mingsong Dou, Jonathan Taylor, Henry Fuchs, Andrew Fitzgibbon, and Shahram Izadi. 2015. 3D scanning deformable objects with a single RGBD sensor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 493–501.Google ScholarCross Ref
28. Mark Fiala. 2005. ARTag, a fiducial marker system using digital techniques. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), Vol. 2. IEEE, 590–596.Google ScholarDigital Library
29. Wolfgang F?rstner and Eberhard G?lch. 1987. A fast operator for detection and precise location of distinct points, corners and centres of circular features. In Proc. ISPRS intercommission conference on fast processing of photogrammetric data. Interlaken, 281–305.Google Scholar
30. Juergen Gall, Bodo Rosenhahn, Thomas Brox, and Hans-Peter Seidel. 2010. Optimization and filtering for human motion capture. International journal of computer vision 87, 1-2 (2010), 75.Google ScholarDigital Library
31. Sergio Garrido-Jurado, Rafael Mu?oz-Salinas, Francisco Jos? Madrid-Cuevas, and Manuel Jes?s Mar?n-Jim?nez. 2014. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognition 47, 6 (2014), 2280–2292.Google ScholarDigital Library
32. D Gavrila and LS Davis. 1996. Tracking of humans in action: A 3-D model-based approach. In ARPA Image Understanding Workshop. (Palm Springs), 737–746.Google Scholar
33. Stevie Giovanni, Yeun Chul Choi, Jay Huang, Eng Tat Khoo, and KangKang Yin. 2012. Virtual try-on using kinect and HD camera. In International Conference on Motion in Games. Springer, 55–65.Google ScholarCross Ref
34. R?za Alp G?ler, Natalia Neverova, and Iasonas Kokkinos. 2018. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7297–7306.Google ScholarCross Ref
35. Kaiwen Guo, Peter Lincoln, Philip Davidson, Jay Busch, Xueming Yu, Matt Whalen, Geoff Harvey, Sergio Orts-Escolano, Rohit Pandey, Jason Dourgarian, et al. 2019. The relightables: Volumetric performance capture of humans with realistic relighting. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1–19.Google ScholarDigital Library
36. Shangchen Han, Beibei Liu, Robert Wang, Yuting Ye, Christopher D Twigg, and Kenrick Kin. 2018. Online optical marker-based hand tracking with deep labels. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–10.Google ScholarDigital Library
37. Christopher G Harris, Mike Stephens, et al. 1988. A combined corner and edge detector.. In Alvey vision conference, Vol. 15. Citeseer, 10–5244.Google Scholar
38. Richard I Hartley and Peter Sturm. 1997. Triangulation. Computer vision and image understanding 68, 2 (1997), 146–157.Google Scholar
39. Gines Hidalgo, Yaadhav Raaj, Haroon Idrees, Donglai Xiang, Hanbyul Joo, Tomas Simon, and Yaser Sheikh. 2019. Single-Network Whole-Body Pose Estimation. arXiv preprint arXiv:1909.13423 (2019).Google Scholar
40. David A Hirshberg, Matthew Loper, Eric Rachlin, and Michael J Black. 2012. Coregistration: Simultaneous alignment and modeling of articulated 3D shape. In European Conference on Computer Vision. Springer, 242–255.Google ScholarDigital Library
41. Daniel Holden. 2018. Robust solving of optical motion capture data by denoising. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–12.Google ScholarDigital Library
42. Danying Hu, Daniel DeTone, and Tomasz Malisiewicz. 2019. Deep charuco: Dark charuco marker pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 8436–8444.Google ScholarCross Ref
43. Peng Huang, Chris Budd, and Adrian Hilton. 2011. Global temporal registration of multiple non-rigid surface sequences. In CVPR 2011. IEEE, 3473–3480.Google ScholarDigital Library
44. Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, and Thomas Brox. 2017. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2462–2470.Google ScholarCross Ref
45. Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. 2014. Deep features for text spotting. In European conference on computer vision. Springer, 512–528.Google ScholarCross Ref
46. Hanbyul Joo, Tomas Simon, and Yaser Sheikh. 2018. Total capture: A 3d deformation model for tracking faces, hands, and bodies. In Proceedings of the IEEE conference on computer vision and pattern recognition. 8320–8329.Google ScholarCross Ref
47. Roland Kehl and Luc Van Gool. 2006. Markerless tracking of complex human motions from multiple views. Computer Vision and Image Understanding 104, 2-3 (2006), 190–209.Google ScholarDigital Library
48. Hao Li, Bart Adams, Leonidas J Guibas, and Mark Pauly. 2009. Robust single-view geometry and motion reconstruction. ACM Transactions on Graphics (ToG) 28, 5 (2009), 1–10.Google ScholarDigital Library
49. Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. 2016. Ssd: Single shot multibox detector. In European conference on computer vision. Springer, 21–37.Google ScholarCross Ref
50. Yebin Liu, Juergen Gall, Carsten Stoll, Qionghai Dai, Hans-Peter Seidel, and Christian Theobalt. 2013. Markerless motion capture of multiple characters using multiview image segmentation. IEEE transactions on pattern analysis and machine intelligence 35, 11 (2013), 2720–2735.Google Scholar
51. Stephen Lombardi, Jason Saragih, Tomas Simon, and Yaser Sheikh. 2018. Deep appearance models for face rendering. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–13.Google ScholarDigital Library
52. Shangbang Long, Xin He, and Cong Yao. 2020. Scene text detection and recognition: The deep learning era. International Journal of Computer Vision (2020), 1–24.Google ScholarDigital Library
53. Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. 2015. SMPL: A skinned multi-person linear model. ACM transactions on graphics (TOG) 34, 6 (2015), 248.Google ScholarDigital Library
54. David G Lowe. 1999. Object recognition from local scale-invariant features. In Proceedings of the seventh IEEE international conference on computer vision, Vol. 2. Ieee, 1150–1157.Google ScholarDigital Library
55. Jianqi Ma, Weiyuan Shao, Hao Ye, Li Wang, Hong Wang, Yingbin Zheng, and Xiangyang Xue. 2018. Arbitrary-oriented scene text detection via rotation proposals. IEEE Transactions on Multimedia 20, 11 (2018), 3111–3122.Google ScholarDigital Library
56. Qianli Ma, Jinlong Yang, Anurag Ranjan, Sergi Pujades, Gerard Pons-Moll, Siyu Tang, and Michael Black. 2020. Learning to Dress 3D People in Generative Clothing. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE.Google ScholarCross Ref
57. Nadia Magnenat-Thalmann, Richard Laperrire, and Daniel Thalmann. 1988. Joint-dependent local deformations for hand animation and object grasping. In In Proceedings on Graphics interface’88. Citeseer.Google Scholar
58. Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, and Christian Theobalt. 2017. Vnect: Real-time 3d human pose estimation with a single rgb camera. ACM Transactions on Graphics (TOG) 36, 4 (2017), 44.Google ScholarDigital Library
59. Abhimitra Meka, Rohit Pandey, Christian Haene, Sergio Orts-Escolano, Peter Barnum, Philip Davidson, Daniel Erickson, Yinda Zhang, Jonathan Taylor, Sofien Bouaziz, Chloe Legendre, Wan-Chun Ma, Ryan Overbeck, Thabo Beeler, Paul Debevec, Shahram Izadi, Christian Theobalt, Christoph Rhemann, and Sean Fanello. 2020. Deep Relightable Textures – Volumetric Performance Capture with Neural Rendering. ACM Transactions on Graphics (Proceedings SIGGRAPH Asia) 39, 6. Google ScholarDigital Library
60. Alberto Menache. 2000. Understanding motion capture for computer animation and video games. Morgan kaufmann.Google Scholar
61. Richard A Newcombe, Dieter Fox, and Steven M Seitz. 2015. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the IEEE conference on computer vision and pattern recognition. 343–352.Google ScholarCross Ref
62. Alejandro Newell, Kaiyu Yang, and Jia Deng. 2016. Stacked hourglass networks for human pose estimation. In European conference on computer vision. Springer, 483–499.Google ScholarCross Ref
63. Edwin Olson. 2011. AprilTag: A robust and flexible visual fiducial system. In 2011 IEEE International Conference on Robotics and Automation. IEEE, 3400–3407.Google ScholarCross Ref
64. Ahmed A A Osman, Timo Bolkart, and Michael J. Black. 2020. STAR: A Spare Trained Articulated Human Body Regressor. In European Conference on Computer Vision (ECCV). https://star.is.tue.mpg.deGoogle Scholar
65. Sang Il Park and Jessica K Hodgins. 2006. Capturing and animating skin deformation in human motion. ACM Transactions on Graphics (TOG) 25, 3 (2006), 881–889.Google ScholarDigital Library
66. Sang Il Park and Jessica K Hodgins. 2008. Data-driven modeling of skin and muscle deformation. In ACM SIGGRAPH 2008 papers. 1–6.Google ScholarDigital Library
67. Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. 2019. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 10975–10985.Google ScholarCross Ref
68. Georgios Pavlakos, Xiaowei Zhou, Konstantinos G Derpanis, and Kostas Daniilidis. 2017. Harvesting multiple views for marker-less 3d human pose annotations. In Proceedings of the IEEE conference on computer vision and pattern recognition. 6988–6997.Google ScholarCross Ref
69. Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, Peter V Gehler, and Bernt Schiele. 2016. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4929–4937.Google ScholarCross Ref
70. Gerard Pons-Moll, Javier Romero, Naureen Mahmood, and Michael J Black. 2015. Dyna: A model of dynamic human shape in motion. ACM Transactions on Graphics (TOG) 34, 4 (2015), 120.Google ScholarDigital Library
71. Fabi?n Prada, Misha Kazhdan, Ming Chuang, Alvaro Collet, and Hugues Hoppe. 2016. Motion graphs for unstructured textured meshes. ACM Transactions on Graphics (TOG) 35, 4 (2016), 1–14.Google ScholarDigital Library
72. Yaadhav Raaj, Haroon Idrees, Gines Hidalgo, and Yaser Sheikh. 2019. Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4620–4628.Google ScholarCross Ref
73. Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. 2020. Accelerating 3D Deep Learning with Py-Torch3D. arXiv:2007.08501 (2020).Google Scholar
74. Joseph Redmon and Ali Farhadi. 2017. YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7263–7271.Google ScholarCross Ref
75. Kathleen M Robinette, Sherri Blackwell, Hein Daanen, Mark Boehmer, and Scott Fleming. 2002. Civilian american and european surface anthropometry resource (caesar), final report. volume 1. summary. Technical Report. SYTRONICS INC DAYTON OH.Google Scholar
76. Edward Rosten and Tom Drummond. 2006. Machine learning for high-speed corner detection. In European conference on computer vision. Springer, 430–443.Google ScholarDigital Library
77. Peter Sand, Leonard McMillan, and Jovan Popovi?. 2003. Continuous capture of skin deformation. In ACM SIGGRAPH 2003 Papers. 578–586.Google ScholarDigital Library
78. Volker Scholz, Timo Stich, Marcus Magnor, Michael Keckeisen, and Markus Wacker. 2005. Garment motion capture using color-coded patterns. In ACM SIGGRAPH 2005 Sketches. 38–es.Google ScholarDigital Library
79. Jianbo Shi et al. 1994. Good features to track. In 1994 Proceedings of IEEE conference on computer vision and pattern recognition. IEEE, 593–600.Google Scholar
80. Ray Smith. 2007. An overview of the Tesseract OCR engine. In Ninth international conference on document analysis and recognition (ICDAR 2007), Vol. 2. IEEE, 629–633.Google ScholarCross Ref
81. Min-Ho Song and Rolf Inge God?y. 2016. How fast is your body motion? Determining a sufficient frame rate for an optical motion tracking system using passive markers. PloS one 11, 3 (2016), e0150993.Google Scholar
82. Jonathan Starck and Adrian Hilton. 2007. Surface capture for performance-based animation. IEEE computer graphics and applications 27, 3 (2007), 21–31.Google ScholarDigital Library
83. Carsten Stoll, Nils Hasler, Juergen Gall, Hans-Peter Seidel, and Christian Theobalt. 2011. Fast articulated motion tracking using a sums of gaussians body model. In 2011 International Conference on Computer Vision. IEEE, 951–958.Google ScholarDigital Library
84. Bill Triggs, Philip F McLauchlan, Richard I Hartley, and Andrew W Fitzgibbon. 1999. Bundle adjustment—a modern synthesis. In International workshop on vision algorithms. Springer, 298–372.Google Scholar
85. Tony Tung and Takashi Matsuyama. 2010. Dynamic surface matching by geodesic mapping for 3d animation transfer. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 1402–1409.Google ScholarCross Ref
86. Graham Upton and Ian Cook. 1996. Understanding statistics. Oxford University Press.Google Scholar
87. Daniel Vlasic, Ilya Baran, Wojciech Matusik, and Jovan Popovi?. 2008. Articulated mesh animation from multi-view silhouettes. In ACM Transactions on Graphics (TOG), Vol. 27. ACM, 97.Google ScholarDigital Library
88. John Wang and Edwin Olson. 2016. AprilTag 2: Efficient and robust fiducial detection. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 4193–4198.Google ScholarDigital Library
89. Robert Y Wang and Jovan Popovi?. 2009. Real-time hand-tracking with a color glove. ACM transactions on graphics (TOG) 28, 3 (2009), 1–8.Google Scholar
90. Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. 2016. Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 4724–4732.Google ScholarCross Ref
91. Ryan White, Keenan Crane, and David A Forsyth. 2007. Capturing and animating occluded cloth. ACM Transactions on Graphics (TOG) 26, 3 (2007), 34–es.Google ScholarDigital Library
92. Donglai Xiang, Hanbyul Joo, and Yaser Sheikh. 2019. Monocular total capture: Posing face, body, and hands in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 10965–10974.Google ScholarCross Ref
93. Yuanlu Xu, Song-Chun Zhu, and Tony Tung. 2019. Denserac: Joint 3d pose and shape estimation by dense render-and-compare. In Proceedings of the IEEE International Conference on Computer Vision. 7760–7770.Google ScholarCross Ref
94. Zhengyou Zhang. 2000. A flexible new technique for camera calibration. IEEE Transactions on pattern analysis and machine intelligence 22, 11 (2000), 1330–1334.Google ScholarDigital Library
95. Huiyu Zhou and Huosheng Hu. 2008. Human motion tracking for rehabilitation—A survey. Biomedical signal processing and control 3, 1 (2008), 1–18.Google Scholar