
“Bodyformer: Semantics-guided 3D Body Gesture Synthesis With Transformer” by Pang, Qin, Fan, Habekost, Shiratori, et al. …
Conference:
Type(s):
Title:
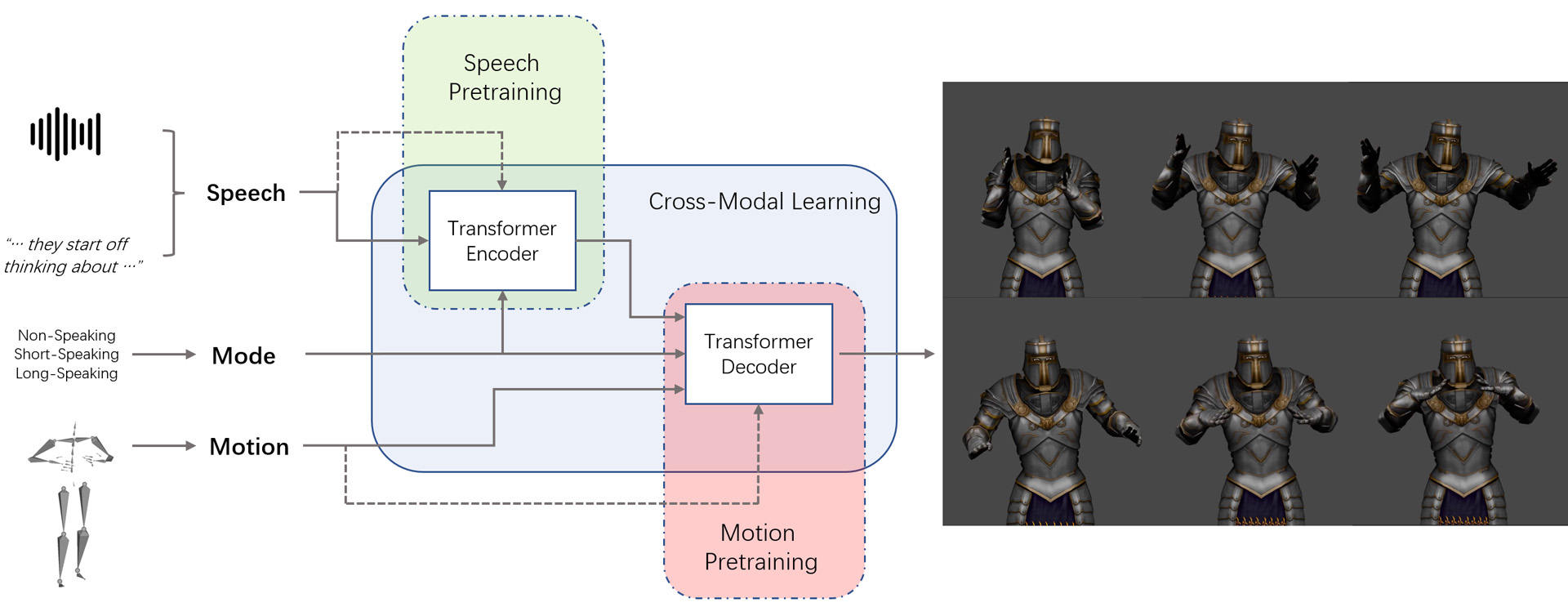
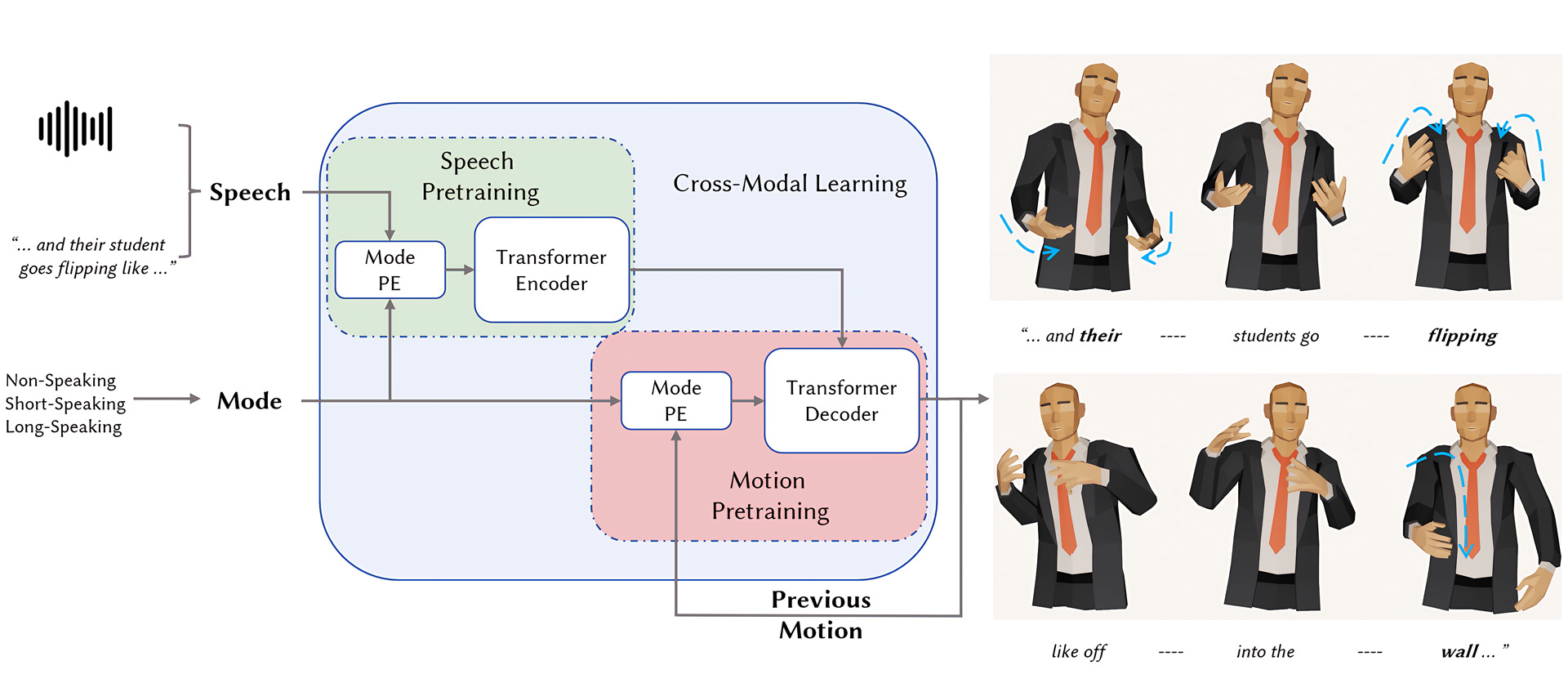
- Bodyformer: Semantics-guided 3D Body Gesture Synthesis With Transformer
Session/Category Title:
- Character Animation: Knowing What To Do With Your Hands
Presenter(s)/Author(s):
Moderator(s):
Abstract:
This paper presents a new variational transformer framework for synthesizing 3D body gestures driven by speech. The system uses a mode position embedding and intra-modal pre-training to learn motion patterns from limited conversational data. Extensive studies show that the system can generate realistic and diverse gestures similar to the ground-truth.
Additional Images:
-
- 2023 Technical Papers: Pang_Bodyformer: Semantics-guided 3D Body Gesture Synthesis With Transformer
Overview Page:
Submit a story:
If you would like to submit a story about this presentation, please contact us: historyarchives@siggraph.org