
“SAWNA: Space-Aware Text to Image Generation” by Morita, Kuno, Tanaka, Li, Dinh, et al. …
Conference:
Type(s):
Title:
- SAWNA: Space-Aware Text to Image Generation
Session/Category Title:
- Images, Video & Computer Vision
Presenter(s)/Author(s):
Abstract:
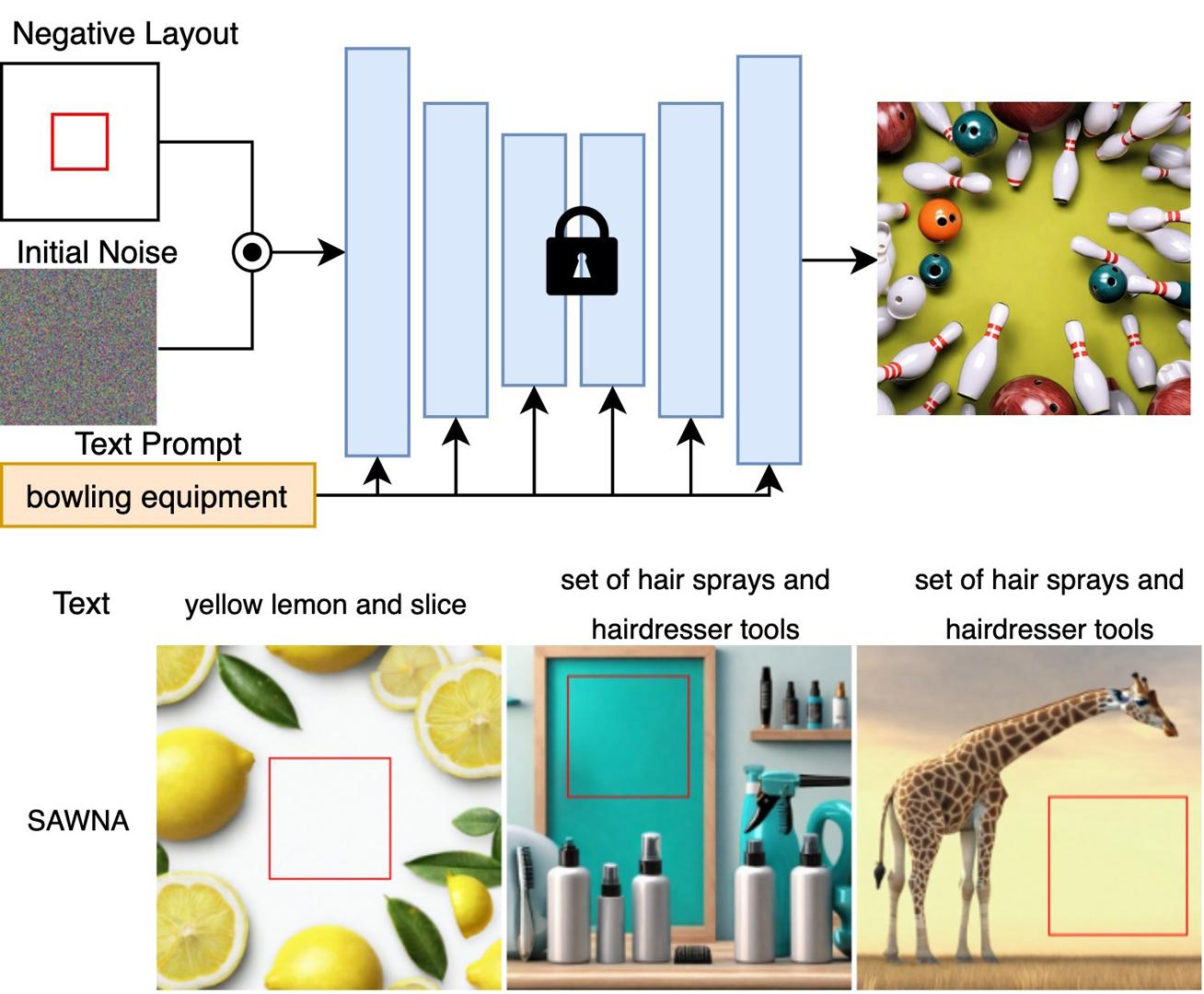
SAWNA tackles layout-sensitive text-to-image generation by treating user-specified empty regions as first-class constraints. Bounding-box masks are blurred and injected as mean-shifted, inert noise into the frozen Stable Diffusion latent, suppressing synthesis inside reserved areas while preserving diversity and quality elsewhere. This simple training-free modification supports workflows that require precise layout fidelity, including advertising (e.g., space for logos or headlines), UI design (e.g., button placement), and animation pre-production (e.g., speech bubbles, subtitles, or motion overlays). Experiments show that SAWNA outperforms layout-aware baselines like GLIGEN and in-painting pipelines, both of which struggle to maintain truly empty regions without introducing artifacts or incoherence. In contrast, SAWNA yields clean, editable space while producing semantically rich images across the remaining canvas. This makes it especially suitable for design-critical applications where reserved regions are integral to downstream compositing or storytelling.
References:
[1] Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. 2023. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22511–22521.
[2] Ryugo Morita, Stanislav Frolov, Brian Bernhard Moser, Takahiro Shirakawa, Ko Watanabe, Andreas Dengel, and Jinjia Zhou. 2024. TKG-DM: Training-free Chroma Key Content Generation Diffusion Model. arXiv preprint arXiv:https://arXiv.org/abs/2411.15580 (2024).
[3] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2023. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:https://arXiv.org/abs/2307.01952 (2023).
[4] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695.
[5] Takahiro Shirakawa and Seiichi Uchida. 2024. Noisecollage: A layout-aware text-to-image diffusion model based on noise cropping and merging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8921–8930.
[6] Andrey Voynov, Kfir Aberman, and Daniel Cohen-Or. 2023. Sketch-guided text-to-image diffusion models. In ACM SIGGRApH 2023 conference proceedings. 1–11.
[7] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision. 3836–3847.
[8] Guangcong Zheng, Xianpan Zhou, Xuewei Li, Zhongang Qi, Ying Shan, and Xi Li. 2023. Layoutdiffusion: Controllable diffusion model for layout-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22490–22499.