
“Iterative Motion Editing With Natural Language”
Conference:
Type(s):
Title:
- Iterative Motion Editing With Natural Language
Presenter(s)/Author(s):
Abstract:
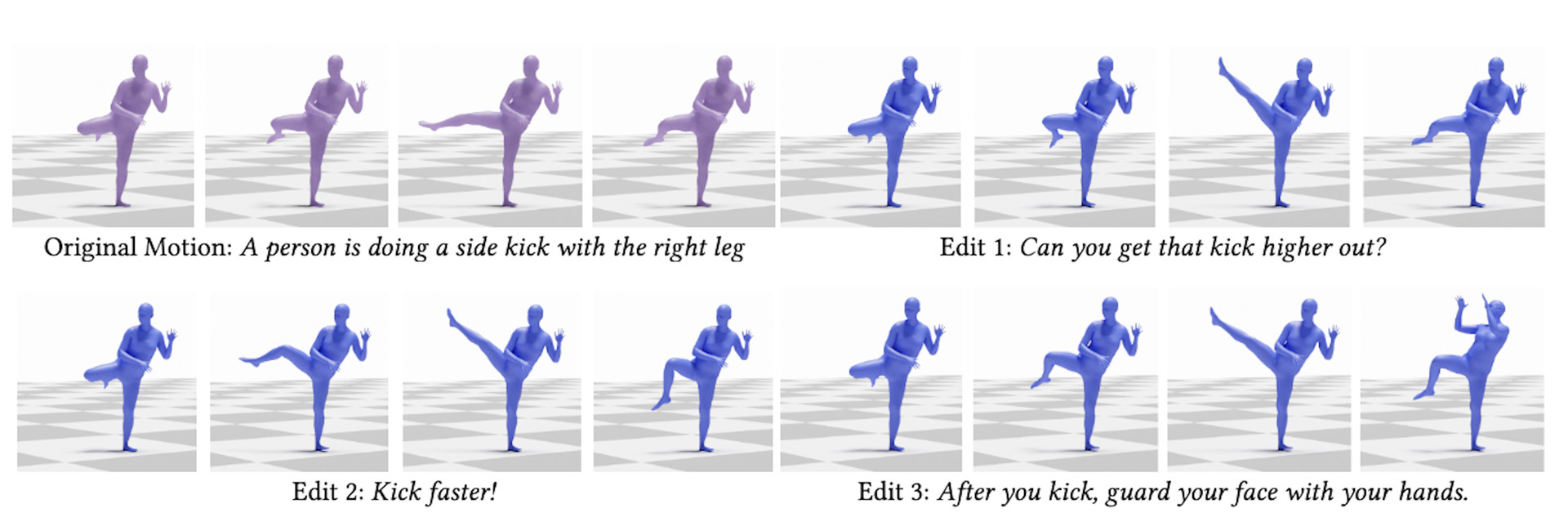
We present a method for using natural language to iteratively and conversationally specify local edits to existing character animations. Our key idea is to represent a space of motion edits using a set of operators that have well-defined semantics for how to modify specific frames of a target motion.
References:
[1]
Kfir Aberman, Yijia Weng, Dani Lischinski, Daniel Cohen-Or, and Baoquan Chen. 2020. Unpaired Motion Style Transfer from Video to Animation. ACM Transactions on Graphics (TOG) 39, 4 (2020), 64.
[2]
Maneesh Agrawala. 2023. Unpredictable Black Boxes are Terrible Interfaces. https://magrawala.substack.com/p/unpredictable-black-boxes-are-terrible.
[3]
Andreas Aristidou, Daniel Cohen-Or, Jessica K. Hodgins, Yiorgos Chrysanthou, and Ariel Shamir. 2018. Deep Motifs and Motion Signatures. ACM Trans. Graph. 37, 6, Article 187 (dec 2018), 13 pages. https://doi.org/10.1145/3272127.3275038
[4]
Omri Avrahami, Dani Lischinski, and Ohad Fried. 2022. Blended Diffusion for Text-Driven Editing of Natural Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18208?18218.
[5]
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J. Black. 2016. Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image. In Computer Vision ? ECCV 2016(Lecture Notes in Computer Science). Springer International Publishing.
[6]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. 2023. InstructPix2Pix: Learning to Follow Image Editing Instructions. In CVPR.
[7]
Ginger Delmas, Philippe Weinzaepfel, Francesc Moreno-Noguer, and Gr?gory Rogez. 2023. PoseFix: Correcting 3D Human Poses with Natural Language. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 15018?15028.
[8]
Mark Endo, Joy Hsu, Jiaman Li, and Jiajun Wu. 2023. Motion Question Answering via Modular Motion Programs. ICML (2023).
[9]
Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, and Michael J. Black. 2023. PoseGPT: Chatting about 3D Human Pose. arxiv:2311.18836 [cs.CV]
[10]
Michael Gleicher. 1997. Motion Editing with Spacetime Constraints. In Proceedings of the 1997 Symposium on Interactive 3D Graphics (Providence, Rhode Island, USA) (I3D ?97). Association for Computing Machinery, New York, NY, USA, 139?ff.https://doi.org/10.1145/253284.253321
[11]
Michael Gleicher. 2001. Motion Path Editing. In Proceedings of the 2001 Symposium on Interactive 3D Graphics(I3D ?01). Association for Computing Machinery, New York, NY, USA, 195?202. https://doi.org/10.1145/364338.364400
[12]
Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. 2023. MultiModal-GPT: A Vision and Language Model for Dialogue with Humans. arxiv:2305.04790 [cs.CV]
[13]
Deepak Gopinath and Jungdam Won. 2020. fairmotion – Tools to load, process and visualize motion capture data. Github. https://github.com/facebookresearch/fairmotion
[14]
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. 2023. MoMask: Generative Masked Modeling of 3D Human Motions. (2023). arxiv:2312.00063 [cs.CV]
[15]
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. 2022. Generating Diverse and Natural 3D Human Motions From Text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5152?5161.
[16]
Sehoon Ha and C. Karen Liu. 2015. Iterative Training of Dynamic Skills Inspired by Human Coaching Techniques. ACM Trans. Graph. 34, 1, Article 1 (dec 2015), 11 pages. https://doi.org/10.1145/2682626
[17]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-prompt image editing with cross attention control. (2022).
[18]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. arXiv preprint arxiv:2006.11239 (2020).
[19]
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022. Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. CoRR abs/2201.07207 (2022). arXiv:2201.07207https://arxiv.org/abs/2201.07207
[20]
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. 2023. MotionGPT: Human Motion as a Foreign Language. arXiv preprint arXiv:2306.14795 (2023).
[21]
Zhongyu Jiang, Zhuoran Zhou, Lei Li, Wenhao Chai, Cheng-Yen Yang, and Jenq-Neng Hwang. 2024. Back to optimization: Diffusion-based zero-shot 3d human pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 6142?6152.
[22]
Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, and Siyu Tang. 2023. Optimizing Diffusion Noise Can Serve As Universal Motion Priors. In arxiv:2312.11994.
[23]
Lucas Kovar, Michael Gleicher, and Fr?d?ric Pighin. 2023. Motion Graphs (1 ed.). Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3596711.3596788
[24]
Sumith Kulal, Jiayuan Mao, Alex Aiken, and Jiajun Wu. 2021. Hierarchical Motion Understanding via Motion Programs. In CVPR.
[25]
Jehee Lee and Sung Yong Shin. 1999. A Hierarchical Approach to Interactive Motion Editing for Human-like Figures. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques(SIGGRAPH ?99). ACM Press/Addison-Wesley Publishing Co., USA, 39?48. https://doi.org/10.1145/311535.311539
[26]
Jiaman Li, Jiajun Wu, and C Karen Liu. 2023. Object motion guided human motion synthesis. ACM Transactions on Graphics (TOG) 42, 6 (2023), 1?11.
[27]
Ruilong Li, Shan Yang, David A. Ross, and Angjoo Kanazawa. 2021. AI Choreographer: Music Conditioned 3D Dance Generation with AIST++. arxiv:2101.08779 [cs.CV]
[28]
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. 2023. Code as Policies: Language Model Programs for Embodied Control. In 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE. https://doi.org/10.1109/icra48891.2023.10160591
[29]
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. 2019. AMASS: Archive of Motion Capture as Surface Shapes. In International Conference on Computer Vision. 5442?5451.
[30]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. 2022. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. arxiv:2108.01073 [cs.CV]
[31]
Lea M?ller, Vickie Ye, Georgios Pavlakos, Michael Black, and Angjoo Kanazawa. 2023. Generative Proxemics: A Prior for 3D Social Interaction from Images. arXiv preprint arXiv:2306.09337 (2023).
[32]
Boris N. Oreshkin, Florent Bocquelet, F?lix G. Harvey, Bay Raitt, and Dominic Laflamme. 2022. ProtoRes: Proto-Residual Network for Pose Authoring via Learned Inverse Kinematics. In International Conference on Learning Representations.
[33]
Jia Qin, Youyi Zheng, and Kun Zhou. 2022. Motion In-Betweening via Two-Stage Transformers. ACM Trans. Graph. 41, 6, Article 184 (nov 2022), 16 pages. https://doi.org/10.1145/3550454.3555454
[34]
Davis Rempe, Zhengyi Luo, Xue Bin Peng, Ye Yuan, Kris Kitani, Karsten Kreis, Sanja Fidler, and Or Litany. 2023. Trace and Pace: Controllable Pedestrian Animation via Guided Trajectory Diffusion. In Conference on Computer Vision and Pattern Recognition (CVPR).
[35]
Jiawei Ren, Mingyuan Zhang, Cunjun Yu, Xiao Ma, Liang Pan, and Ziwei Liu. 2023. InsActor: Instruction-driven Physics-based Characters. NeurIPS (2023).
[36]
Vishnu Sarukkai, Linden Li, Arden Ma, Christopher R?, and Kayvon Fatahalian. 2023. Collage Diffusion. arxiv:2303.00262 [cs.CV]
[37]
Yonatan Shafir, Guy Tevet, Roy Kapon, and Amit H Bermano. 2023. Human motion diffusion as a generative prior. arXiv preprint arXiv:2303.01418 (2023).
[38]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. arxiv:2303.11366 [cs.AI]
[39]
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. 2023. ProgPrompt: Generating Situated Robot Task Plans using Large Language Models. In 2023 IEEE International Conference on Robotics and Automation (ICRA). 11523?11530. https://doi.org/10.1109/ICRA48891.2023.10161317
[40]
D?dac Sur?s, Sachit Menon, and Carl Vondrick. 2023. ViperGPT: Visual Inference via Python Execution for Reasoning. Proceedings of IEEE International Conference on Computer Vision (ICCV) (2023).
[41]
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. 2023. Human Motion Diffusion Model. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=SJ1kSyO2jwu
[42]
Jonathan Tseng, Rodrigo Castellon, and C Karen Liu. 2022. EDGE: Editable Dance Generation From Music. arXiv preprint arXiv:2211.10658 (2022).
[43]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023b. Voyager: An Open-Ended Embodied Agent with Large Language Models. arxiv:2305.16291 [cs.AI]
[44]
Kuan-Chieh Wang, Zhenzhen Weng, Maria Xenochristou, Jo?o Pedro Ara?jo, Jeffrey Gu, Karen Liu, and Serena Yeung. 2023a. NeMo: Learning 3D Neural Motion Fields From Multiple Video Instances of the Same Action. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 22129?22138.
[45]
Dong Wei, Xiaoning Sun, Huaijiang Sun, Bin Li, Sheng liang Hu, Weiqing Li, and Jian-Zhou Lu. 2023a. Understanding Text-driven Motion Synthesis with Keyframe Collaboration via Diffusion Models. ArXiv abs/2305.13773 (2023). https://api.semanticscholar.org/CorpusID:258841591
[46]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023b. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arxiv:2201.11903 [cs.CL]
[47]
Andrew P. Witkin and Zoran Popovic. 1995. Motion warping. Proceedings of the 22nd annual conference on Computer graphics and interactive techniques (1995). https://api.semanticscholar.org/CorpusID:1497012
[48]
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. 2021. VideoGPT: Video Generation using VQ-VAE and Transformers. arxiv:2104.10157 [cs.CV]
[49]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arxiv:2210.03629 [cs.CL]
[50]
Wenjie Yin, Hang Yin, Kim Baraka, Danica Kragic, and M?rten Bj?rkman. 2023. Dance Style Transfer with Cross-modal Transformer. In 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). 5047?5056. https://doi.org/10.1109/WACV56688.2023.00503
[51]
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. 2022. MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model. arXiv preprint arXiv:2208.15001 (2022).
[52]
Mingyuan Zhang, Huirong Li, Zhongang Cai, Jiawei Ren, Lei Yang, and Ziwei Liu. 2023. FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing. NeurIPS (2023).