
“VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild” by Cheng, Cun, Zhang, Xia, Yin, et al. …
Conference:
Type(s):
Title:
- VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild
Session/Category Title:
- Technical Papers Fast-Forward
Presenter(s)/Author(s):
Abstract:
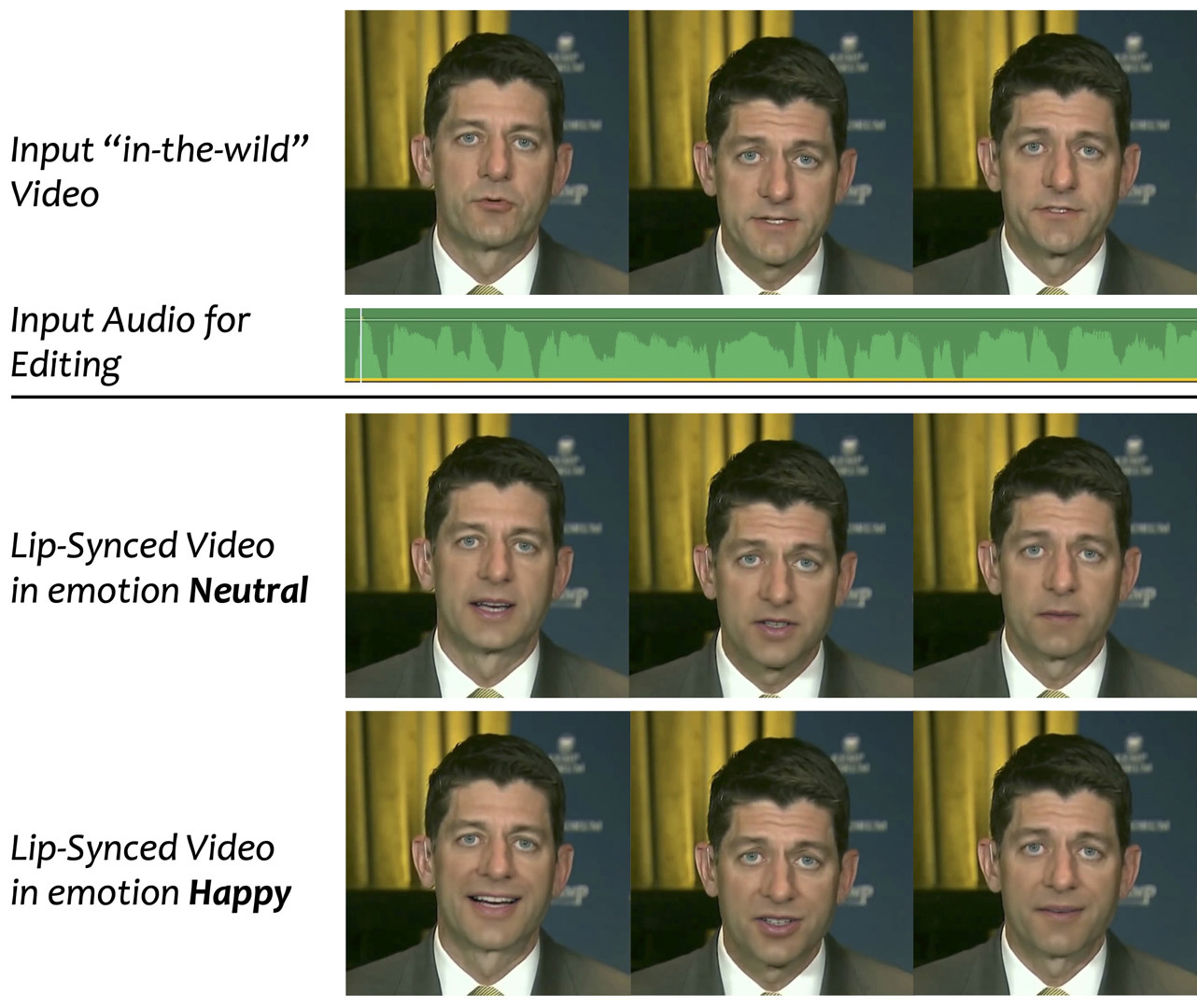
We present VideoReTalking, a new system to edit the faces of a real-world talking head video according to an input audio, producing a high-quality and lip-syncing output video even with a different emotion.Our system disentangles this objective into three sequential tasks: (1) face video generation with a canonical expression; (2) audio-driven lip-sync; and (3) face enhancement for improving photo-realism. Given a talking-head video, we first modify the expression of each frame according to the same expression template using the expression editing network, resulting in a video with the canonical expression. This video, together with a given audio, are then fed into the lip-sync network to generate a lip-syncing video. Finally, we improve the photo-realism of the synthesized faces through an identity-aware face enhancement network and post-processing. We use learning-based approaches for all three steps and all our modules can be tackled in a sequential pipeline without any user intervention. Furthermore, our system is a generic approach that is not retrained to a specific video or person. Evaluations on two widely-used datasets and in-the-wild examples demonstrate the superiority of our framework over other state-of-the-art methods in terms of lip-sync accuracy and visual quality.