
“Text2Human: text-driven controllable human image generation” by Jiang, Yang, Qju, Wu, Loy, et al. …
Conference:
Type(s):
Title:
- Text2Human: text-driven controllable human image generation
Presenter(s)/Author(s):
Abstract:
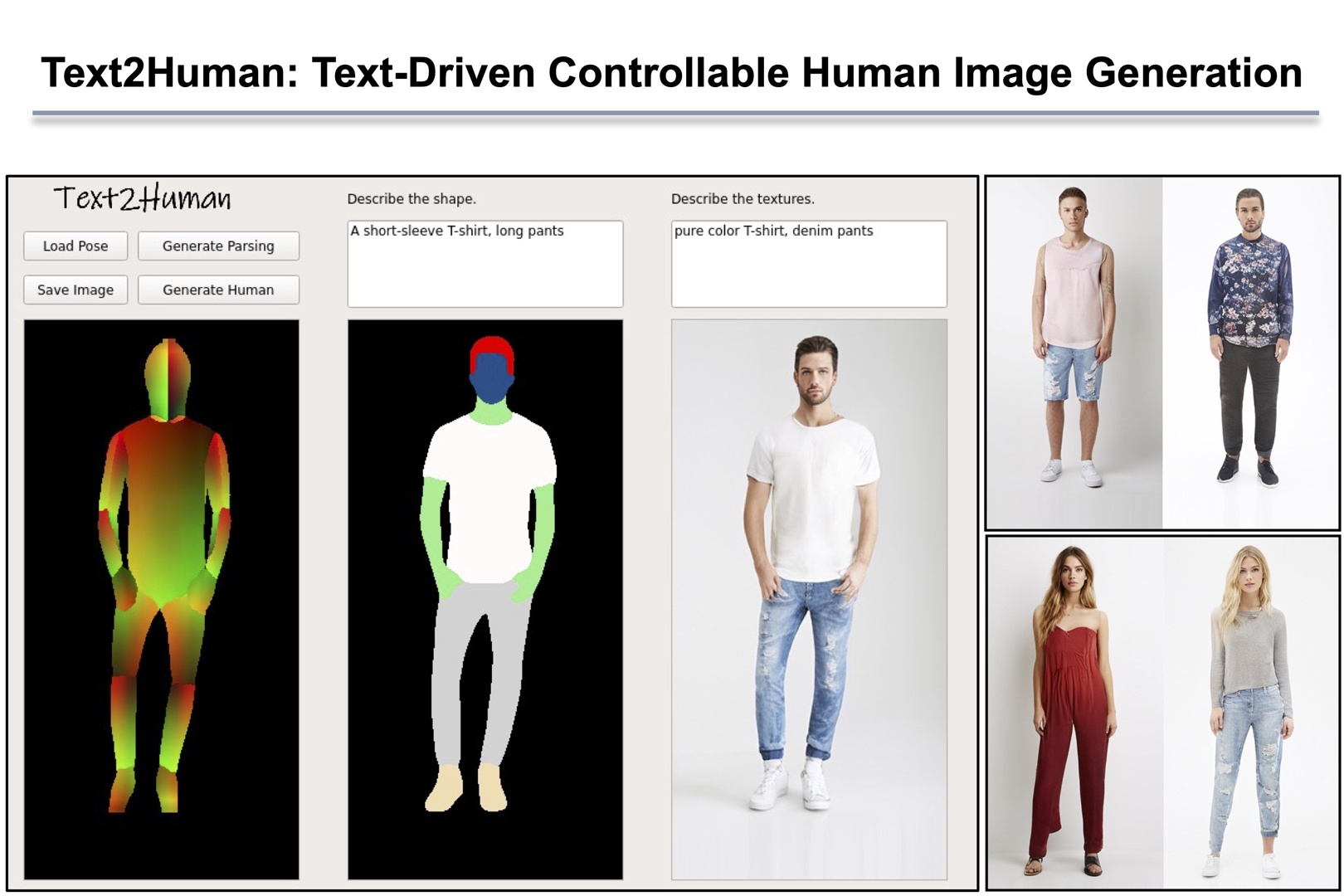
Generating high-quality and diverse human images is an important yet challenging task in vision and graphics. However, existing generative models often fall short under the high diversity of clothing shapes and textures. Furthermore, the generation process is even desired to be intuitively controllable for layman users. In this work, we present a text-driven controllable framework, Text2Human, for a high-quality and diverse human generation. We synthesize full-body human images starting from a given human pose with two dedicated steps. 1) With some texts describing the shapes of clothes, the given human pose is first translated to a human parsing map. 2) The final human image is then generated by providing the system with more attributes about the textures of clothes. Specifically, to model the diversity of clothing textures, we build a hierarchical texture-aware codebook that stores multi-scale neural representations for each type of texture. The codebook at the coarse level includes the structural representations of textures, while the codebook at the fine level focuses on the details of textures. To make use of the learned hierarchical codebook to synthesize desired images, a diffusion-based transformer sampler with mixture of experts is firstly employed to sample indices from the coarsest level of the codebook, which then is used to predict the indices of the codebook at finer levels. The predicted indices at different levels are translated to human images by the decoder learned accompanied with hierarchical codebooks. The use of mixture-of-experts allows for the generated image conditioned on the fine-grained text input. The prediction for finer level indices refines the quality of clothing textures. Extensive quantitative and qualitative evaluations demonstrate that our proposed Text2Human framework can generate more diverse and realistic human images compared to state-of-the-art methods. Our project page is https://yumingj.github.io/projects/Text2Human.html. Code and pretrained models are available at https://github.com/yumingj/Text2Human.
References:
1. Rameen Abdal, Peihao Zhu, Niloy J Mitra, and Peter Wonka. 2021. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows. ACM Transactions on Graphics (TOG) 40, 3 (2021), 1–21.Google ScholarDigital Library
2. Badour Albahar, Jingwan Lu, Jimei Yang, Zhixin Shu, Eli Shechtman, and Jia-Bin Huang. 2021. Pose with Style: Detail-preserving pose-guided image synthesis with conditional stylegan. ACM Transactions on Graphics (TOG) 40, 6 (2021), 1–11.Google ScholarDigital Library
3. Guha Balakrishnan, Amy Zhao, Adrian V Dalca, Fredo Durand, and John Guttag. 2018. Synthesizing images of humans in unseen poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8340–8348.Google ScholarCross Ref
4. Sam Bond-Taylor, Peter Hessey, Hiroshi Sasaki, Toby P Breckon, and Chris G Willcocks. 2021. Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes. arXiv preprint arXiv:2111.12701 (2021).Google Scholar
5. Andrew Brock, Jeff Donahue, and Karen Simonyan. 2019. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In International Conference on Learning Representations. https://openreview.net/forum?id=B1xsqj09FmGoogle Scholar
6. Zhongang Cai, Daxuan Ren, Ailing Zeng, Zhengyu Lin, Tao Yu, Wenjia Wang, Xiangyu Fan, Yang Gao, Yifan Yu, Liang Pan, Fangzhou Hong, Mingyuan Zhang, Chen Change Loy, Lei Yang, and Ziwei Liu. 2022. HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling. arXiv preprint arXiv:2204.13686 (2022).Google Scholar
7. Lucy Chai, Michael Gharbi, Eli Shechtman, Phillip Isola, and Richard Zhang. 2022. Any-resolution Training for High-resolution Image Synthesis. arXiv preprint arXiv:2204.07156 (2022).Google Scholar
8. Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. 2019. Everybody dance now. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5933–5942.Google ScholarCross Ref
9. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. 2022. MaskGIT: Masked Generative Image Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Google ScholarCross Ref
10. Xi Chen, Nikhil Mishra, Mostafa Rohaninejad, and Pieter Abbeel. 2018. Pixelsnail: An improved autoregressive generative model. In International Conference on Machine Learning. PMLR, 864–872.Google Scholar
11. Aiyu Cui, Daniel McKee, and Svetlana Lazebnik. 2021. Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-On and Outfit Editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3940–3945.Google Scholar
12. Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4690–4699.Google ScholarCross Ref
13. Patrick Esser, Robin Rombach, Andreas Blattmann, and Bjorn Ommer. 2021b. Imagebart: Bidirectional context with multinomial diffusion for autoregressive image synthesis. Advances in Neural Information Processing Systems 34 (2021).Google Scholar
14. Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021a. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12873–12883.Google ScholarCross Ref
15. Patrick Esser, Ekaterina Sutter, and Bj?rn Ommer. 2018. A variational u-net for conditional appearance and shape generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8857–8866.Google ScholarCross Ref
16. Anna Fr?hst?ck, Krishna Kumar Singh, Eli Shechtman, Niloy J. Mitra, Peter Wonka, and Jingwan Lu. 2022. InsetGAN for Full-Body Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Google ScholarCross Ref
17. Jianglin Fu, Shikai Li, Yuming Jiang, Kwan-Yee Lin, Chen Qian, Chen-Change Loy, Wayne Wu, and Ziwei Liu. 2022. StyleGAN-Human: A Data-Centric Odyssey of Human Generation. arXiv preprint arXiv:2204.11823 (2022).Google Scholar
18. Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. Advances in Neural Information Processing Systems 27 (2014).Google Scholar
19. Artur Grigorev, Karim Iskakov, Anastasia Ianina, Renat Bashirov, Ilya Zakharkin, Alexander Vakhitov, and Victor Lempitsky. 2021. Stylepeople: A generative model of fullbody human avatars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5151–5160.Google ScholarCross Ref
20. Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. 2022. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Google ScholarCross Ref
21. R?za Alp G?ler, Natalia Neverova, and Iasonas Kokkinos. 2018. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7297–7306.Google ScholarCross Ref
22. Fangzhou Hong, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang, and Ziwei Liu. 2022. AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars. ACM Transactions on Graphics (TOG) 41, 4, Article 161 (2022), 19 pages. Google ScholarDigital Library
23. Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2017. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1125–1134.Google ScholarCross Ref
24. Yuming Jiang, Ziqi Huang, Xingang Pan, Chen Change Loy, and Ziwei Liu. 2021. Talk-to-Edit: Fine-Grained Facial Editing via Dialog. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 13799–13808.Google ScholarCross Ref
25. Tero Karras, Miika Aittala, Samuli Laine, Erik H?rk?nen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. Alias-free generative adversarial networks. Advances in Neural Information Processing Systems 34 (2021).Google Scholar
26. Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4401–4410.Google ScholarCross Ref
27. Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8110–8119.Google ScholarCross Ref
28. Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013).Google Scholar
29. Anders Boesen Lindbo Larsen, S?ren Kaae S?nderby, Hugo Larochelle, and Ole Winther. 2016. Autoencoding beyond pixels using a learned similarity metric. In International conference on machine learning. PMLR, 1558–1566.Google Scholar
30. Kathleen M Lewis, Srivatsan Varadharajan, and Ira Kemelmacher-Shlizerman. 2021. Tryongan: Body-aware try-on via layered interpolation. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–10.Google ScholarDigital Library
31. Lingjie Liu, Weipeng Xu, Marc Habermann, Michael Zollh?fer, Florian Bernard, Hyeongwoo Kim, Wenping Wang, and Christian Theobalt. 2020. Neural Human Video Rendering by Learning Dynamic Textures and Rendering-to-Video Translation. IEEE Transactions on Visualization and Computer Graphics PP (05 2020), 1–1. Google ScholarDigital Library
32. Lingjie Liu, Weipeng Xu, Michael Zollhoefer, Hyeongwoo Kim, Florian Bernard, Marc Habermann, Wenping Wang, and Christian Theobalt. 2019. Neural rendering and reenactment of human actor videos. ACM Transactions on Graphics (TOG) 38, 5 (2019), 1–14.Google ScholarDigital Library
33. Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. 2016a. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1096–1104.Google ScholarCross Ref
34. Ziwei Liu, Sijie Yan, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2016b. Fashion landmark detection in the wild. In European Conference on Computer Vision. Springer, 229–245.Google ScholarCross Ref
35. Liqian Ma, Xu Jia, Qianru Sun, Bernt Schiele, Tinne Tuytelaars, and Luc Van Gool. 2017. Pose guided person image generation. Advances in Neural Information Processing Systems 30 (2017).Google Scholar
36. Liqian Ma, Qianru Sun, Stamatios Georgoulis, Luc Van Gool, Bernt Schiele, and Mario Fritz. 2018. Disentangled person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 99–108.Google ScholarCross Ref
37. Yifang Men, Yiming Mao, Yuning Jiang, Wei-Ying Ma, and Zhouhui Lian. 2020. Controllable person image synthesis with attribute-decomposed gan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5084–5093.Google ScholarCross Ref
38. Mehdi Mirza and Simon Osindero. 2014. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014).Google Scholar
39. Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. 2019. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2337–2346.Google ScholarCross Ref
40. Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. 2021. Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2085–2094.Google ScholarCross Ref
41. Justin NM Pinkney and Doron Adler. 2020. Resolution Dependent GAN Interpolation for Controllable Image Synthesis Between Domains. arXiv preprint arXiv:2010.05334 (2020).Google Scholar
42. Ali Razavi, Aaron van den Oord, and Oriol Vinyals. 2019. Generating diverse high-fidelity images with vq-vae-2. In Advances in Neural Information Processing Systems. 14866–14876.Google Scholar
43. Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics. http://arxiv.org/abs/1908.10084Google ScholarCross Ref
44. Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik P Kingma. 2017. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv preprint arXiv:1701.05517 (2017).Google Scholar
45. Kripasindhu Sarkar, Vladislav Golyanik, Lingjie Liu, and Christian Theobalt. 2021a. Style and Pose Control for Image Synthesis of Humans from a Single Monocular View. arXiv preprint arXiv:2102.11263 (2021).Google Scholar
46. Kripasindhu Sarkar, Lingjie Liu, Vladislav Golyanik, and Christian Theobalt. 2021b. HumanGAN: A Generative Model of Human Images. In 2021 International Conference on 3D Vision (3DV). IEEE, 258–267.Google Scholar
47. Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017).Google Scholar
48. Guoxian Song, Linjie Luo, Jing Liu, Wan-Chun Ma, Chunpong Lai, Chuanxia Zheng, and Tat-Jen Cham. 2021. AgileGAN: stylizing portraits by inversion-consistent transfer learning. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–13.Google ScholarDigital Library
49. Shiv Surya, Amrith Setlur, Arijit Biswas, and Sumit Negi. 2020. ReStGAN: A step towards visually guided shopper experience via text-to-image synthesis. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 1200–1208.Google ScholarCross Ref
50. Jiale Tao, Biao Wang, Borun Xu, Tiezheng Ge, Yuning Jiang, Wen Li, and Lixin Duan. 2022. Structure-Aware Motion Transfer with Deformable Anchor Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Google ScholarCross Ref
51. Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. 2016. Conditional image generation with pixelcnn decoders. Advances in Neural Information Processing Systems 29 (2016).Google Scholar
52. Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning. Advances in Neural Information Processing Systems 30 (2017).Google Scholar
53. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ?ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems. 5998–6008.Google Scholar
54. Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. 2018. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8798–8807.Google ScholarCross Ref
55. Shuchen Weng, Wenbo Li, Dawei Li, Hongxia Jin, and Boxin Shi. 2020. Misc: Multi-condition injection and spatially-adaptive compositing for conditional person image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7741–7749.Google ScholarCross Ref
56. Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. 2018. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1316–1324.Google ScholarCross Ref
57. Shuai Yang, Liming Jiang, Ziwei Liu, and Chen Change Loy. 2022. Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1–10.Google ScholarCross Ref
58. Gokhan Yildirim, Nikolay Jetchev, Roland Vollgraf, and Urs Bergmann. 2019. Generating high-resolution fashion model images wearing custom outfits. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 0–0.Google ScholarCross Ref
59. Jae Shin Yoon, Lingjie Liu, Vladislav Golyanik, Kripasindhu Sarkar, Hyun Soo Park, and Christian Theobalt. 2021. Pose-Guided Human Animation from a Single Image in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15039–15048.Google ScholarCross Ref
60. Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Google ScholarCross Ref
61. Xingran Zhou, Siyu Huang, Bin Li, Yingming Li, Jiachen Li, and Zhongfei Zhang. 2019. Text guided person image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3663–3672.Google ScholarCross Ref