
“Text-Guided Vector Graphics Customization” by Zhang, Zhao and Liao
Conference:
Type(s):
Title:
- Text-Guided Vector Graphics Customization
Session/Category Title:
- Creative Expression
Presenter(s)/Author(s):
Abstract:
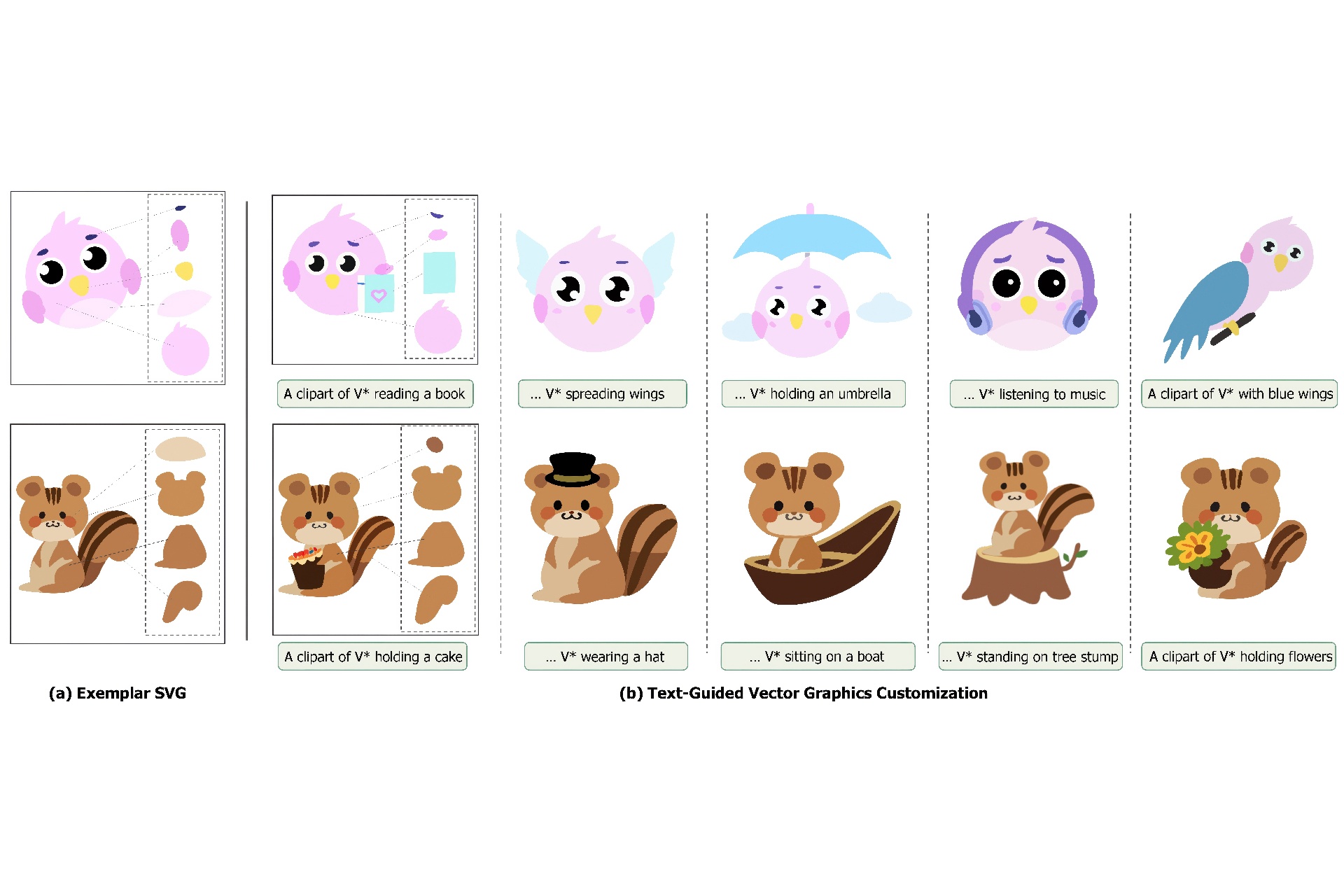
Vector graphics are widely used in digital art and valued by designers for their scalability and layer-wise topological properties. However, the creation and editing of vector graphics necessitate creativity and design expertise, leading to a time-consuming process. In this paper, we propose a novel pipeline that generates high-quality customized vector graphics based on textual prompts while preserving the properties and layer-wise information of a given exemplar SVG. Our method harnesses the capabilities of large pre-trained text-to-image models. By fine-tuning the cross-attention layers of the model, we generate customized raster images guided by textual prompts. To initialize the SVG, we introduce a semantic-based path alignment method that preserves and transforms crucial paths from the exemplar SVG. Additionally, we optimize path parameters using both image-level and vector-level losses, ensuring smooth shape deformation while aligning with the customized raster image. We extensively evaluate our method using multiple metrics from vector-level, image-level, and text-level perspectives. The evaluation results demonstrate the effectiveness of our pipeline in generating diverse customizations of vector graphics with exceptional quality. The project page is https://intchous.github.io/SVGCustomization.
References:
[1]
Gavin Ambrose, Paul Harris, and Nigel Ball. 2019. The fundamentals of graphic design. Bloomsbury Publishing.
[2]
Shir Amir, Yossi Gandelsman, Shai Bagon, and Tali Dekel. 2021. Deep vit features as dense visual descriptors. arXiv preprint arXiv:2112.05814 2, 3 (2021), 4.
[3]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision. 9650–9660.
[4]
Nassim Dehouche and Kullathida. 2023. What is in a Text-to-Image Prompt: The Potential of Stable Diffusion in Visual Arts Education. arXiv preprint arXiv:2301.01902 (2023).
[5]
James Richard Diebel. 2008. Bayesian Image Vectorization: the probabilistic inversion of vector image rasterization. Stanford University.
[6]
Edoardo Alberto Dominici, Nico Schertler, Jonathan Griffin, Shayan Hoshyari, Leonid Sigal, and Alla Sheffer. 2020. Polyfit: Perception-aligned vectorization of raster clip-art via intermediate polygonal fitting. ACM Transactions on Graphics (TOG) 39, 4 (2020), 77–1.
[7]
Jean-Dominique Favreau, Florent Lafarge, and Adrien Bousseau. 2017. Photo2clipart: Image abstraction and vectorization using layered linear gradients. ACM Transactions on Graphics (TOG) 36, 6 (2017), 1–11.
[8]
Kevin Frans, Lisa Soros, and Olaf Witkowski. 2022. Clipdraw: Exploring text-to-drawing synthesis through language-image encoders. Advances in Neural Information Processing Systems 35 (2022), 5207–5218.
[9]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2022. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618 (2022).
[10]
David Ha and Douglas Eck. 2017. A neural representation of sketch drawings. arXiv preprint arXiv:1704.03477 (2017).
[11]
Denis Hadjivelichkov, Sicelukwanda Zwane, Lourdes Agapito, Marc Peter Deisenroth, and Dimitrios Kanoulas. 2023. One-Shot Transfer of Affordance Regions? AffCorrs!. In Conference on Robot Learning. PMLR, 550–560.
[12]
Shayan Hoshyari, Edoardo Alberto Dominici, Alla Sheffer, Nathan Carr, Zhaowen Wang, Duygu Ceylan, and I-Chao Shen. 2018. Perception-driven semi-structured boundary vectorization. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–14.
[13]
Ajay Jain, Amber Xie, and Pieter Abbeel. 2022. VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models. arXiv preprint arXiv:2211.11319 (2022).
[14]
Johannes Kopf and Dani Lischinski. 2011. Depixelizing pixel art. In ACM SIGGRAPH 2011 papers. 1–8.
[15]
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. 2022. Multi-Concept Customization of Text-to-Image Diffusion. arXiv preprint arXiv:2212.04488 (2022).
[16]
Bowen Li, Xiaojuan Qi, Thomas Lukasiewicz, and Philip Torr. 2019. Controllable text-to-image generation. Advances in Neural Information Processing Systems 32 (2019).
[17]
Tzu-Mao Li, Michal Lukáč, Michaël Gharbi, and Jonathan Ragan-Kelley. 2020. Differentiable vector graphics rasterization for editing and learning. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1–15.
[18]
Xu Ma, Yuqian Zhou, Xingqian Xu, Bin Sun, Valerii Filev, Nikita Orlov, Yun Fu, and Humphrey Shi. 2022. Towards layer-wise image vectorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16314–16323.
[19]
Andriy Myronenko and Xubo Song. 2010. Point set registration: Coherent point drift. IEEE transactions on pattern analysis and machine intelligence 32, 12 (2010), 2262–2275.
[20]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021).
[21]
Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar R Zaiane, and Martin Jagersand. 2020. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern recognition 106 (2020), 107404.
[22]
Antoine Quint. 2003. Scalable vector graphics. IEEE MultiMedia 10, 3 (2003), 99–102.
[23]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748–8763.
[24]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. In International Conference on Machine Learning. PMLR, 8821–8831.
[25]
Pradyumna Reddy, Michael Gharbi, Michal Lukac, and Niloy J Mitra. 2021. Im2vec: Synthesizing vector graphics without vector supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7342–7351.
[26]
Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. 2016. Generative adversarial text to image synthesis. In International conference on machine learning. PMLR, 1060–1069.
[27]
Leo Sampaio Ferraz Ribeiro, Tu Bui, John Collomosse, and Moacir Ponti. 2020. Sketchformer: Transformer-based representation for sketched structure. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14153–14162.
[28]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695.
[29]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2022. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. arXiv preprint arXiv:2208.12242 (2022).
[30]
Peter Schaldenbrand, Zhixuan Liu, and Jean Oh. 2022. Styleclipdraw: Coupling content and style in text-to-drawing translation. arXiv preprint arXiv:2202.12362 (2022).
[31]
Peter Selinger. 2003. Potrace: a polygon-based tracing algorithm.
[32]
Yiren Song, Xning Shao, Kang Chen, Weidong Zhang, Minzhe Li, and Zhongliang Jing. 2022. CLIPVG: Text-Guided Image Manipulation Using Differentiable Vector Graphics. arXiv preprint arXiv:2212.02122 (2022).
[33]
Yingtao Tian and David Ha. 2022. Modern evolution strategies for creativity: Fitting concrete images and abstract concepts. In Artificial Intelligence in Music, Sound, Art and Design: 11th International Conference, EvoMUSART 2022, Held as Part of EvoStar 2022, Madrid, Spain, April 20–22, 2022, Proceedings. Springer, 275–291.
[34]
Yael Vinker, Ehsan Pajouheshgar, Jessica Y Bo, Roman Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir. 2022. Clipasso: Semantically-aware object sketching. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1–11.
[35]
Chang Wang and Sridhar Mahadevan. 2008. Manifold alignment using procrustes analysis. In Proceedings of the 25th international conference on Machine learning. 1120–1127.
[36]
Jinfan Yang, Nicholas Vining, Shakiba Kheradmand, Nathan Carr, Leonid Sigal, and Alla Sheffer. 2023. Subpixel Deblurring of Anti-Aliased Raster Clip-Art. In Computer Graphics Forum, Vol. 42. Wiley Online Library, 61–76.
[37]
Ming Yang, Hongyang Chao, Chi Zhang, Jun Guo, Lu Yuan, and Jian Sun. 2015. Effective clipart image vectorization through direct optimization of bezigons. IEEE transactions on visualization and computer graphics 22, 2 (2015), 1063–1075.