
“TexPainter: Generative Mesh Texturing With Multi-view Consistency”
Conference:
Type(s):
Title:
- TexPainter: Generative Mesh Texturing With Multi-view Consistency
Presenter(s)/Author(s):
Abstract:
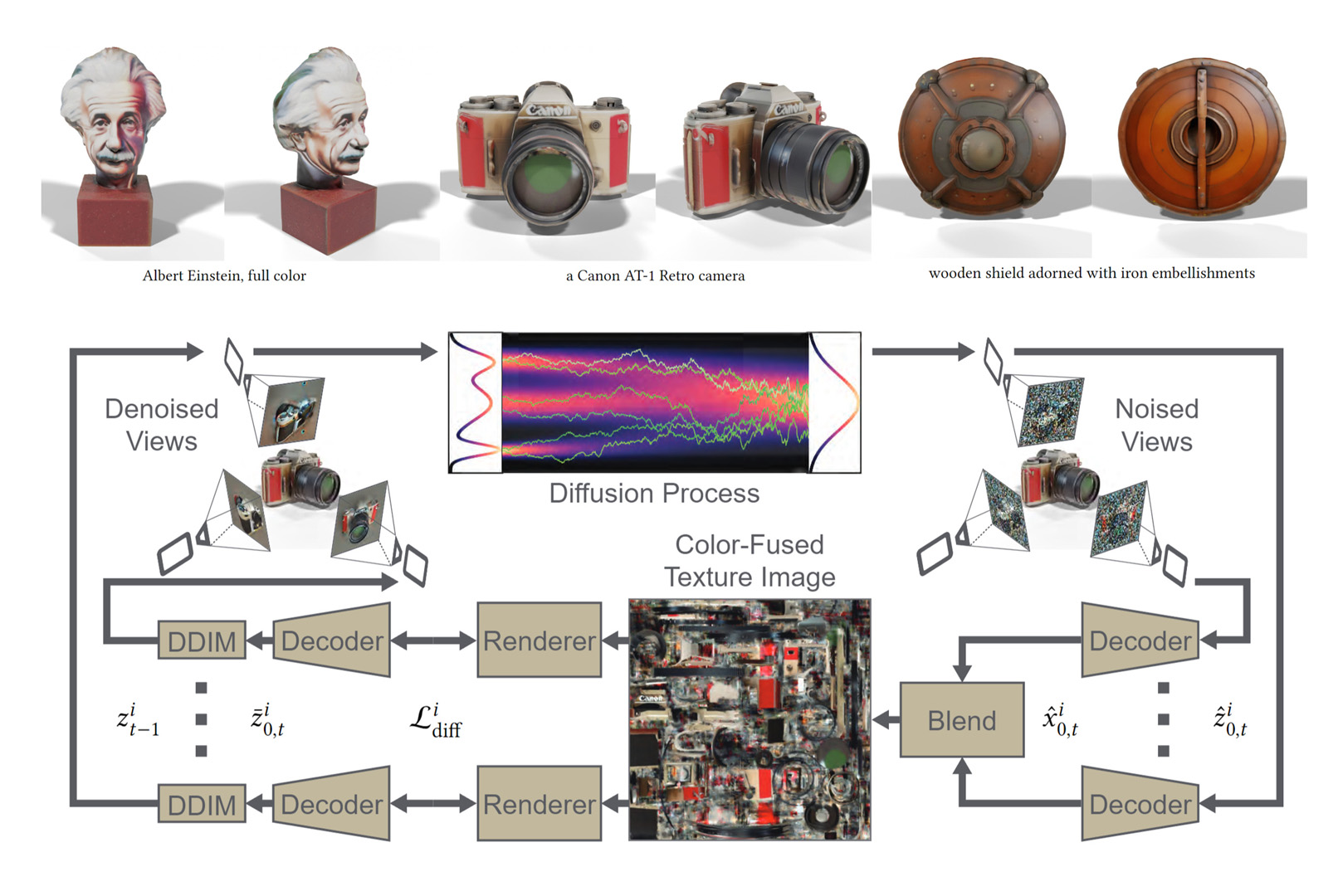
We propose a novel texture generation method with multi-view consistency using a pre-trained 2D diffusion model. Drawing on the principle of DDIM scheme and its adept prediction of noisy latent. Our method focuses on explicitly controlling the consistency of texture while preserving the denoise process of diffusion model.
References:
[1]
Omri Avrahami, Ohad Fried, and Dani Lischinski. 2023. Blended latent diffusion. ACM Transactions on Graphics (TOG) 42, 4 (2023), 1?11.
[2]
Fan Bao, Michael Schwarz, and Peter Wonka. 2013. Procedural facade variations from a single layout. ACM Trans. Graph. 32, 1, Article 8 (feb 2013), 13 pages. https://doi.org/10.1145/2421636.2421644
[3]
Alexey Bokhovkin, Shubham Tulsiani, and Angela Dai. 2023. Mesh2Tex: Generating Mesh Textures from Image Queries. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 8918?8928.
[4]
Andrew Brock, Theodore Lim, James M Ritchie, and Nick Weston. 2016. Generative and discriminative voxel modeling with convolutional neural networks. arXiv preprint arXiv:1608.04236 (2016).
[5]
Tianshi Cao, Karsten Kreis, Sanja Fidler, Nicholas Sharp, and KangXue Yin. 2023. TexFusion: Synthesizing 3D Textures with Text-Guided Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
[6]
Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Niesner. 2023c. Text2Tex: Text-driven Texture Synthesis via Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 18558?18568.
[7]
Guoning Chen, Gregory Esch, Peter Wonka, Pascal M?ller, and Eugene Zhang. 2008. Interactive procedural street modeling. In ACM SIGGRAPH 2008 papers. 1?10.
[8]
Qimin Chen, Zhiqin Chen, Hang Zhou, and Hao Zhang. 2023b. ShaDDR: Interactive Example-Based Geometry and Texture Generation via 3D Shape Detailization and Differentiable Rendering. In SIGGRAPH Asia 2023 Conference Papers (, Sydney, NSW, Australia, ) (SA ?23). Association for Computing Machinery, New York, NY, USA, Article 58, 11 pages. https://doi.org/10.1145/3610548.3618201
[9]
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. 2023a. Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
[10]
Yongwei Chen, Rui Chen, Jiabao Lei, Yabin Zhang, and Kui Jia. 2022a. TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition. In Advances in Neural Information Processing Systems (NeurIPS).
[11]
Zhiqin Chen, Kangxue Yin, and Sanja Fidler. 2022b. AUV-Net: Learning Aligned UV Maps for Texture Transfer and Synthesis. In The Conference on Computer Vision and Pattern Recognition (CVPR).
[12]
Junyu Dong, Jun Liu, Kang Yao, Mike Chantler, Lin Qi, Hui Yu, and Muwei Jian. 2020. Survey of procedural methods for two-dimensional texture generation. Sensors 20, 4 (2020), 1135.
[13]
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. 2022. GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.). Vol. 35. Curran Associates, Inc., 31841?31854.
[14]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems (Long Beach, California, USA). Red Hook, NY, USA, 6629?6640.
[15]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems (Vancouver, BC, Canada). Curran Associates Inc., Red Hook, NY, USA, Article 574, 12 pages.
[16]
Jonathan Ho and Tim Salimans. 2021. Classifier-Free Diffusion Guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications.
[17]
jpcy. [n. d.]. XAtlas. https://github.com/jpcy/xatlas
[18]
Animesh Karnewar, Andrea Vedaldi, David Novotny, and Niloy J. Mitra. 2023. HOLODIFFUSION: Training a 3D Diffusion Model Using 2D Images. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18423?18433.
[19]
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. 2020. Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1?14.
[20]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3D: High-Resolution Text-to-3D Content Creation. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 300?309.
[21]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan LI, and Jun Zhu. 2022. DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps. In Advances in Neural Information Processing Systems, Vol. 35. 5775?5787.
[22]
Tom Mertens, Jan Kautz, Jiawen Chen, Philippe Bekaert, and Fr?do Durand. 2006. Texture Transfer Using Geometry Correlation.Rendering Techniques 273, 10.2312 (2006), 273?284.
[23]
Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. 2023. Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12663?12673.
[24]
Oscar Michel, Roi Bar-On, Richard Liu, Sagie Benaim, and Rana Hanocka. 2022. Text2Mesh: Text-Driven Neural Stylization for Meshes. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13482?13492.
[25]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 1 (2021), 99?106.
[26]
Pascal M?ller, Peter Wonka, Simon Haegler, Andreas Ulmer, and Luc Van Gool. 2006. Procedural modeling of buildings. In ACM SIGGRAPH 2006 Papers. 614?623.
[27]
Norman M?ller, Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bul?, Peter Kontschieder, and Matthias Niesner. 2023. DiffRF: Rendering-Guided 3D Radiance Field Diffusion. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4328?4338.
[28]
Michael Oechsle, Lars Mescheder, Michael Niemeyer, Thilo Strauss, and Andreas Geiger. 2019. Texture Fields: Learning Texture Representations in Function Space. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV). 4530?4539.
[29]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2023. DreamFusion: Text-to-3D using 2D Diffusion. In The Eleventh International Conference on Learning Representations.
[30]
Przemyslaw Prusinkiewicz, Mark Hammel, Jim Hanan, and Radomir Mech. 1996. L-systems: from the theory to visual models of plants. In Proceedings of the 2nd CSIRO Symposium on Computational Challenges in Life Sciences, Vol. 3. 1?32.
[31]
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. 2023. TEXTure: Text-Guided Texturing of 3D Shapes. In ACM SIGGRAPH 2023 Conference Proceedings (Los Angeles, CA, USA) (SIGGRAPH ?23). Association for Computing Machinery, New York, NY, USA, Article 54, 11 pages.
[32]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj?rn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10674?10685.
[33]
Mehdi SM Sajjadi, Bernhard Scholkopf, and Michael Hirsch. 2017. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE international conference on computer vision. 4491?4500.
[34]
Dominik Sibbing, Darko Pavi?, and Leif Kobbelt. 2010. Image synthesis for branching structures. In Computer Graphics Forum, Vol. 29. Wiley Online Library, 2135?2144.
[35]
Yawar Siddiqui, Justus Thies, Fangchang Ma, Qi Shan, Matthias Niesner, and Angela Dai. 2022. Texturify: Generating Textures on 3D Shape Surfaces. In Computer Vision – ECCV 2022 – 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part III(Lecture Notes in Computer Science, Vol. 13663). Springer, 72?88. https://doi.org/10.1007/978-3-031-20062-5_5
[36]
Ruben M Smelik, Tim Tutenel, Rafael Bidarra, and Bedrich Benes. 2014. A survey on procedural modelling for virtual worlds. In Computer graphics forum, Vol. 33. Wiley Online Library, 31?50.
[37]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning. PMLR, 2256?2265.
[38]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2021a. Denoising Diffusion Implicit Models. In International Conference on Learning Representations.
[39]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2021b. Score-Based Generative Modeling through Stochastic Differential Equations. In International Conference on Learning Representations.
[40]
Ruoxi Sun, Jinyuan Jia, and Marc Jaeger. 2009. Intelligent tree modeling based on L-system. In 2009 IEEE 10th International Conference on Computer-Aided Industrial Design & Conceptual Design. IEEE, 1096?1100.
[41]
Jerry O Talton, Yu Lou, Steve Lesser, Jared Duke, Radom?r Mech, and Vladlen Koltun. 2011. Metropolis procedural modeling.ACM Trans. Graph. 30, 2 (2011), 11?1.
[42]
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. 2023. MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion. arXiv (2023).
[43]
Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis, 2022. LION: Latent Point Diffusion Models for 3D Shape Generation. Advances in Neural Information Processing Systems 35 (2022), 10021?10039.
[44]
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, and Thomas Wolf. 2022. Diffusers: State-of-the-art diffusion models.
[45]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. 2023. ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. In Advances in Neural Information Processing Systems (NeurIPS).
[46]
Li-Yi Wei, Sylvain Lefebvre, Vivek Kwatra, and Greg Turk. 2009. State of the art in example-based texture synthesis. Eurographics 2009, State of the Art Report, EG-STAR (2009), 93?117.
[47]
Jiajun Wu, Chengkai Zhang, Tianfan Xue, Bill Freeman, and Josh Tenenbaum. 2016. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. Advances in neural information processing systems 29 (2016).
[48]
Kai Yu, Jinlin Liu, Mengyang Feng, Miaomiao Cui, and Xuansong Xie. 2023b. Boosting3D: High-Fidelity Image-to-3D by Boosting 2D Diffusion Prior to 3D Prior with Progressive Learning. arxiv:2311.13617 [cs.CV]
[49]
Rui Yu, Yue Dong, Pieter Peers, and Xin Tong. 2021. Learning texture generators for 3d shape collections from internet photo sets. In British Machine Vision Conference.
[50]
Xin Yu, Peng Dai, Wenbo Li, Lan Ma, Zhengzhe Liu, and Xiaojuan Qi. 2023a. Texture Generation on 3D Meshes with Point-UV Diffusion. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV). 4183?4193.
[51]
Xianfang Zeng, Xin Chen, Zhongqi Qi, Wen Liu, Zibo Zhao, Zhibin Wang, Bin Fu, Yong Liu, and Gang Yu. 2023. Paint3D: Paint Anything 3D with Lighting-Less Texture Diffusion Models. arxiv:2312.13913 [cs.CV]
[52]
Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, and Karsten Kreis. 2022. LION: Latent Point Diffusion Models for 3D Shape Generation. In Advances in Neural Information Processing Systems (NeurIPS).
[53]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3836?3847.
[54]
Linqi Zhou, Yilun Du, and Jiajun Wu. 2021. 3d shape generation and completion through point-voxel diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5826?5835.
[55]
Qi Zuo, Yafei Song, Jianfang Li, Lin Liu, and Liefeng Bo. 2023. DG3D: Generating High Quality 3D Textured Shapes by Learning to Discriminate Multi-Modal Diffusion-Renderings. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV). 14529?14538. https://doi.org/10.1109/ICCV51070.2023.01340