
“T2DyVec: Leveraging Sparse Images and Controllable Text for Dynamic SVG” by Wu, Xiao and Jiang
Conference:
Type(s):
Title:
- T2DyVec: Leveraging Sparse Images and Controllable Text for Dynamic SVG
Session/Category Title:
- Images, Video & Computer Vision
Presenter(s)/Author(s):
Abstract:
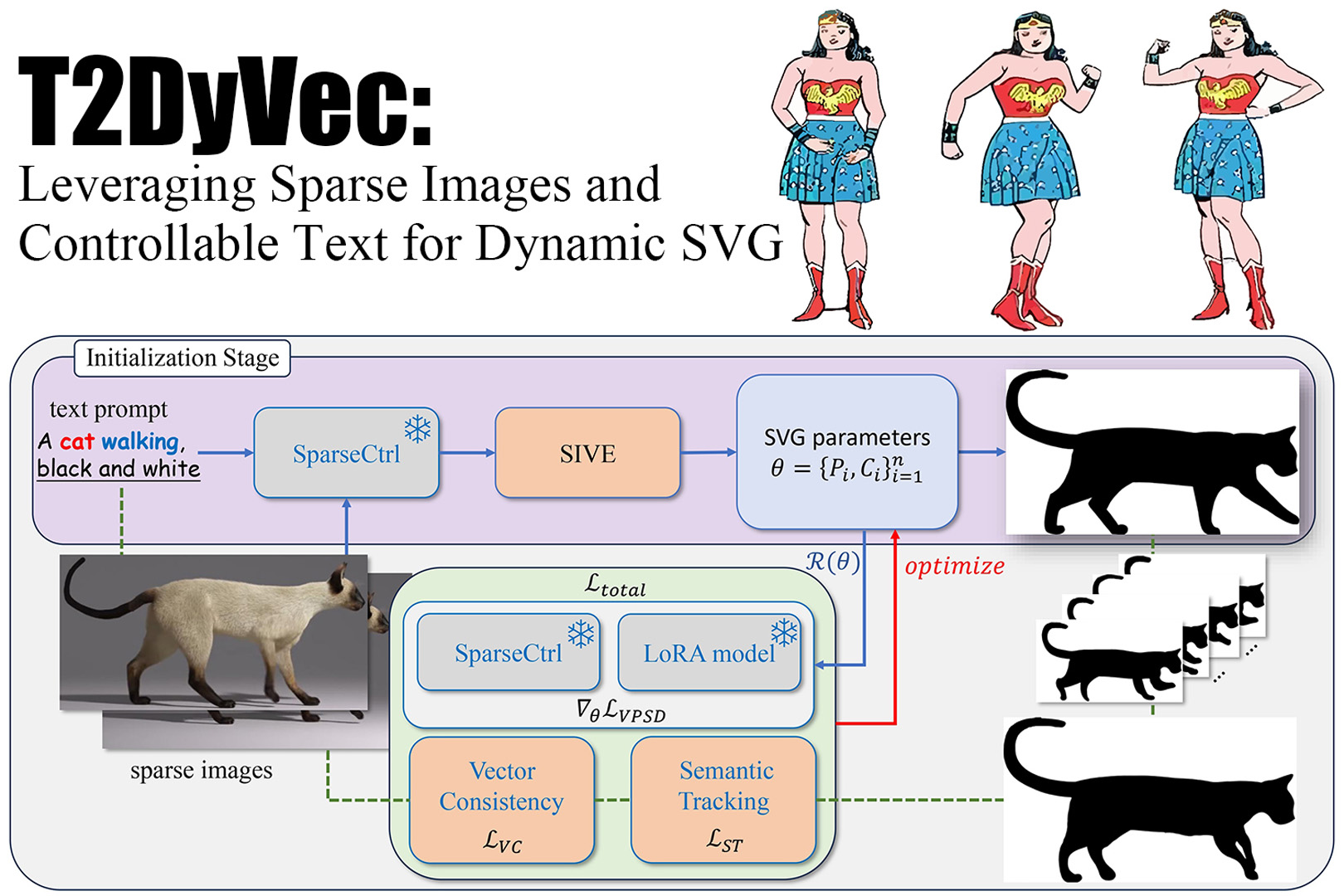
We propose T2DyVec, which leverages text prompts and sparse images as a control for dynamic vector generation. It incorporates Vector Consistency, Semantic Tracking, and VPSD to optimize the vector parameters, enabling the generation of multi-frame dynamic coherent vectors. This approach can help designers facilitate both generation and further editing.
References:
[1]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Maneesh Agrawala, Dahua Lin, and Bo Dai. 2023. SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models. CoRR abs/2311.16933 (2023). https://doi.org/10.48550/ARXIV.2311.16933 arXiv:2311.16933
[2]
Olga Sorkine and Marc Alexa. 2007. As-rigid-as-possible surface modeling. In Proceedings of the Fifth Eurographics Symposium on Geometry Processing, Barcelona, Spain, July 4-6, 2007(ACM International Conference Proceeding Series, Vol. 257), Alexander G. Belyaev and Michael Garland (Eds.). Eurographics Association, 109?116. https://doi.org/10.2312/SGP/SGP07/109-116
[3]
Ximing Xing, Haitao Zhou, Chuang Wang, Jing Zhang, Dong Xu, and Qian Yu. 2023. SVGDreamer: Text Guided SVG Generation with Diffusion Model. CoRR abs/2312.16476 (2023). https://doi.org/10.48550/ARXIV.2312.16476 arXiv:2312.16476