
“Speech gesture generation from the trimodal context of text, audio, and speaker identity” by Yoon, Cha, Lee, Jang, Lee, et al. …
Conference:
Type(s):
Title:
- Speech gesture generation from the trimodal context of text, audio, and speaker identity
Session/Category Title:
- Hands and Faces
Presenter(s)/Author(s):
Abstract:
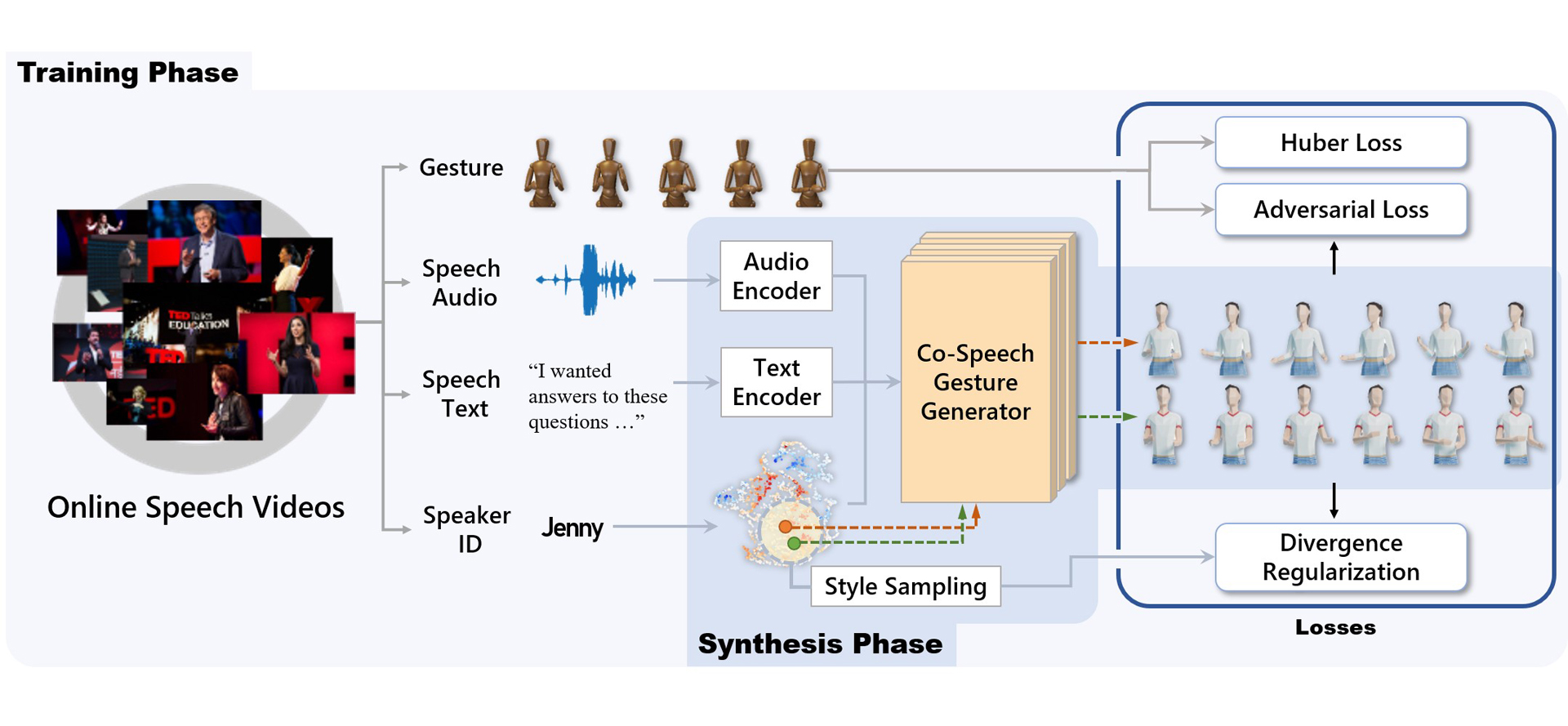
For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human-agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to generate human-like gestures due to the lack of understanding of how people gesture. Data-driven approaches attempt to learn gesticulation skills from human demonstrations, but the ambiguous and individual nature of gestures hinders learning. In this paper, we present an automatic gesture generation model that uses the multimodal context of speech text, audio, and speaker identity to reliably generate gestures. By incorporating a multimodal context and an adversarial training scheme, the proposed model outputs gestures that are human-like and that match with speech content and rhythm. We also introduce a new quantitative evaluation metric for gesture generation models. Experiments with the introduced metric and subjective human evaluation showed that the proposed gesture generation model is better than existing end-to-end generation models. We further confirm that our model is able to work with synthesized audio in a scenario where contexts are constrained, and show that different gesture styles can be generated for the same speech by specifying different speaker identities in the style embedding space that is learned from videos of various speakers. All the code and data is available at https://github.com/ai4r/Gesture-Generation-from-Trimodal-Context.
References:
1. Chaitanya Ahuja and Louis-Philippe Morency. 2019. Language2Pose: Natural Language Grounded Pose Forecasting. In International Conference on 3D Vision. IEEE, 719–728.Google ScholarCross Ref
2. Simon Alexanderson, Gustav Eje Henter, Taras Kucherenko, and Jonas Beskow. 2020. Style-Controllable Speech-Driven Gesture Synthesis Using Normalising Flows. In Computer Graphics Forum, Vol. 39. Wiley Online Library, 487–496.Google Scholar
3. Andreas Aristidou, Efstathios Stavrakis, Panayiotis Charalambous, Yiorgos Chrysanthou, and Stephania Loizidou Himona. 2015. Folk Dance Evaluation Using Laban Movement Analysis. Journal on Computing and Cultural Heritage 8, 4 (2015), 20.Google ScholarDigital Library
4. Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. International Conference on Learning Representations.Google Scholar
5. Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. 2018. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv:1803.01271 (2018).Google Scholar
6. Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2018. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 2 (2018), 423–443.Google ScholarDigital Library
7. Kirsten Bergmann, Volkan Aksu, and Stefan Kopp. 2011. The Relation of Speech and Gestures: Temporal Synchrony Follows Semantic Synchrony. In Proceedings of the 2nd Workshop on Gesture and Speech in Interaction.Google Scholar
8. Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics 5 (2017), 135–146.Google ScholarCross Ref
9. Ali Borji. 2019. Pros and Cons of GAN Evaluation Measures. Computer Vision and Image Understanding 179 (2019), 41–65.Google ScholarDigital Library
10. Paul Bremner, Anthony G Pipe, Chris Melhuish, Mike Fraser, and Sriram Subramanian. 2011. The Effects of Robot-Performed Co-Verbal Gesture on Listener Behaviour. In IEEE-RAS International Conference on Humanoid Robots. IEEE, 458–465.Google Scholar
11. Judee K Burgoon, Thomas Birk, and Michael Pfau. 1990. Nonverbal Behaviors, Persuasion, and Credibility. Human communication research 17, 1 (1990), 140–169.Google Scholar
12. Justine Cassell, Hannes Högni Vilhjálmsson, and Timothy Bickmore. 2004. BEAT: the Behavior Expression Animation Toolkit. In Life-Like Characters. Springer, 163–185.Google Scholar
13. Chung-Cheng Chiu, Louis-Philippe Morency, and Stacy Marsella. 2015. Predicting Co-verbal Gestures: A Deep and Temporal Modeling Approach. In ACM International Conference on Intelligent Virtual Agents. Springer, 152–166.Google Scholar
14. Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Empirical Methods in Natural Language Processing. 1724–1734.Google Scholar
15. Mingyuan Chu and Peter Hagoort. 2014. Synchronization of Speech and Gesture: Evidence for Interaction in Action. Journal of Experimental Psychology: General 143, 4 (2014), 1726.Google ScholarCross Ref
16. Wei Chu and Zoubin Ghahramani. 2005. Extensions of Gaussian Processes for Ranking: Semi-supervised and Active Learning. Learning to Rank (2005), 29.Google Scholar
17. Andrew P Clark, Kate L Howard, Andy T Woods, Ian S Penton-Voak, and Christof Neumann. 2018. Why Rate When You Could Compare? Using the “EloChoice” Package to Assess Pairwise Comparisons of Perceived Physical Strength. PloS one 13, 1 (2018).Google Scholar
18. Ylva Ferstl, Michael Neff, and Rachel McDonnell. 2019. Multi-Objective Adversarial Gesture Generation. In Motion, Interaction and Games. 1–10.Google Scholar
19. Peng Fu, Zheng Lin, Fengcheng Yuan, Weiping Wang, and Dan Meng. 2018. Learning Sentiment-Specific Word Embedding via Global Sentiment Representation. In AAAI Conference on Artificial Intelligence.Google Scholar
20. Shiry Ginosar, Amir Bar, Gefen Kohavi, Caroline Chan, Andrew Owens, and Jitendra Malik. 2019. Learning Individual Styles of Conversational Gesture. In IEEE Conference on Computer Vision and Pattern Recognition. 3497–3506.Google Scholar
21. Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. In Advances in Neural Information Processing Systems. 2672–2680.Google Scholar
22. Google. 2018. Google Cloud Text-to-Speech. https://cloud.google.com/text-to-speech Accessed: 2020-03-01.Google Scholar
23. Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems. 6626–6637.Google Scholar
24. Autumn B Hostetter and Andrea L Potthoff. 2012. Effects of Personality and Social Situation on Representational Gesture Production. Gesture 12, 1 (2012), 62–83.Google ScholarCross Ref
25. Chien-Ming Huang and Bilge Mutlu. 2014. Learning-Based Modeling of Multimodal Behaviors for Humanlike Robots. In ACM/IEEE International Conference on Human-Robot Interaction. ACM, 57–64.Google Scholar
26. Peter J Huber. 1964. Robust Estimation of a Location Parameter. The Annals of Mathematical Statistics 35, 1 (1964), 73–101.Google ScholarCross Ref
27. Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. 2013. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Transactions on Pattern Analysis and Machine Intelligence 36, 7 (2013), 1325–1339.Google ScholarDigital Library
28. Ali Jahanian, Lucy Chai, and Phillip Isola. 2020. On the “Steerability” of Generative Adversarial Networks. In International Conference on Learning Representations.Google Scholar
29. Hanbyul Joo, Tomas Simon, Mina Cikara, and Yaser Sheikh. 2019. Towards Social Artificial Intelligence: Nonverbal Social Signal Prediction in A Triadic Interaction. In IEEE Conference on Computer Vision and Pattern Recognition. 10873–10883.Google Scholar
30. Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. 2018. Fréchet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms. arXiv preprint arXiv:1812.08466 (2018).Google Scholar
31. Taewoo Kim and Joo-Haeng Lee. 2020. C-3PO: Cyclic-Three-Phase Optimization for Human-Robot Motion Retargeting based on Reinforcement Learning. In International Conference on Robotics and Automation.Google ScholarCross Ref
32. Diederik P Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In International Conference on Learning Representations.Google Scholar
33. Michael Kipp. 2005. Gesture Generation by Imitation: From Human Behavior to Computer Character Animation. Universal-Publishers.Google Scholar
34. Sotaro Kita. 2000. How Representational Gestures Help Speaking. Language and gesture 1 (2000), 162–185.Google Scholar
35. Stefan Kopp, Brigitte Krenn, Stacy Marsella, Andrew N Marshall, Catherine Pelachaud, Hannes Pirker, Kristinn R Thórisson, and Hannes Vilhjálmsson. 2006. Towards a Common Framework for Multimodal Generation: The Behavior Markup Language. In ACM International Conference on Intelligent Virtual Agents. Springer, 205–217.Google ScholarDigital Library
36. Taras Kucherenko, Dai Hasegawa, Gustav Eje Henter, Naoshi Kaneko, and Hedvig Kjellström. 2019. Analyzing Input and Output Representations for Speech-Driven Gesture Generation. In ACM International Conference on Intelligent Virtual Agents. 97–104.Google Scholar
37. Taras Kucherenko, Patrik Jonell, Sanne van Waveren, Gustav Eje Henter, Simon Alexanderson, Iolanda Leite, and Hedvig Kjellström. 2020. Gesticulator: A Framework for Semantically-Aware Speech-Driven Gesture Generation. In ACM International Conference on Multimodal Interaction.Google Scholar
38. Sergey Levine, Philipp Krähenbühl, Sebastian Thrun, and Vladlen Koltun. 2010. Gesture Controllers. ACM Transactions on Graphics 29, 4 (2010), 1–11.Google ScholarDigital Library
39. Stacy Marsella, Yuyu Xu, Margaux Lhommet, Andrew Feng, Stefan Scherer, and Ari Shapiro. 2013. Virtual Character Performance From Speech. In ACM SIGGRAPH/Eurographics Symposium on Computer Animation. 25–35.Google Scholar
40. Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. 2018. UMAP: Uniform Manifold Approximation and Projection. Journal of Open Source Software 3 (2018).Google Scholar
41. David McNeill. 1992. Hand and Mind: What Gestures Reveal About Thought. University of Chicago press.Google Scholar
42. David McNeill. 2008. Gesture and Thought. University of Chicago press.Google Scholar
43. Alberto Menache. 2000. Understanding Motion Capture for Computer Animation and Video Games. Morgan Kaufmann.Google Scholar
44. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems. 3111–3119.Google Scholar
45. George A Miller. 1995. WordNet: A Lexical Database for English. Commun. ACM 38, 11 (1995), 39–41.Google ScholarDigital Library
46. Michael Neff, Michael Kipp, Irene Albrecht, and Hans-Peter Seidel. 2008. Gesture Modeling and Animation Based on a Probabilistic Recreation of Speaker Style. ACM Transactions on Graphics 27, 1 (2008), 5.Google ScholarDigital Library
47. Robert Ochshorn and Max Hawkins. 2016. Gentle: A Forced Aligner. https://lowerquality.com/gentle/ Accessed: 2020-01-06.Google Scholar
48. Dario Pavllo, Christoph Feichtenhofer, David Grangier, and Michael Auli. 2019. 3D Human Pose Estimation in Video With Temporal Convolutions and Semi-Supervised Training. In IEEE Conference on Computer Vision and Pattern Recognition. 7753–7762.Google ScholarCross Ref
49. Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global Vectors for Word Representation. In Empirical Methods in Natural Language Processing. 1532–1543.Google Scholar
50. Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. 2014. Stochastic back-propagation and approximate inference in deep generative models. In Proceedings of the International Conference on Machine Learning, Vol. 32. 1278–1286.Google Scholar
51. Matthew Roddy, Gabriel Skantze, and Naomi Harte. 2018. Multimodal Continuous Turn-Taking Prediction Using Multiscale RNNs. In ACM International Conference on Multimodal Interaction. ACM, 186–190.Google Scholar
52. David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. 1985. Learning Internal Representations by Error Propagation. Technical Report. California Univ San Diego La Jolla Inst for Cognitive Science.Google Scholar
53. Najmeh Sadoughi and Carlos Busso. 2019. Speech-Driven Animation with Meaningful Behaviors. Speech Communication 110 (2019), 90–100.Google ScholarDigital Library
54. Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016. Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems. 2234–2242.Google Scholar
55. Robotics Softbank. 2018. NAOqi API Documentation. http://doc.aldebaran.com/2-5/index_dev_guide.html Accessed: 2020-01-06.Google Scholar
56. Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. 2019. FVD: A new Metric for Video Generation. In International Conference on Learning Representations Workshop.Google Scholar
57. Petra Wagner, Zofia Malisz, and Stefan Kopp. 2014. Gesture and Speech in Interaction: An Overview. Speech Communication 57, Special Iss. (2014).Google Scholar
58. Jason R Wilson, Nah Young Lee, Annie Saechao, Sharon Hershenson, Matthias Scheutz, and Linda Tickle-Degnen. 2017. Hand Gestures and Verbal Acknowledgments Improve Human-Robot Rapport. In International Conference on Social Robotics. Springer, 334–344.Google Scholar
59. Dingdong Yang, Seunghoon Hong, Yunseok Jang, Tianchen Zhao, and Honglak Lee. 2019. Diversity-Sensitive Conditional Generative Adversarial Networks. In International Conference on Learning Representations.Google Scholar
60. Youngwoo Yoon, Woo-Ri Ko, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. 2019. Robots Learn Social Skills: End-to-End Learning of Co-Speech Gesture Generation for Humanoid Robots. In International Conference on Robotics and Automation. IEEE, 4303–4309.Google Scholar
61. Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In IEEE Conference on Computer Vision and Pattern Recognition. 586–595.Google ScholarCross Ref