
“Spatial Storybook: Language Model-Driven Audiobook Spatialization” by Ananthabhotla and Brimijoin
Conference:
Type(s):
Title:
- Spatial Storybook: Language Model-Driven Audiobook Spatialization
Session/Category Title:
- Spatial Storytelling
Presenter(s)/Author(s):
Abstract:
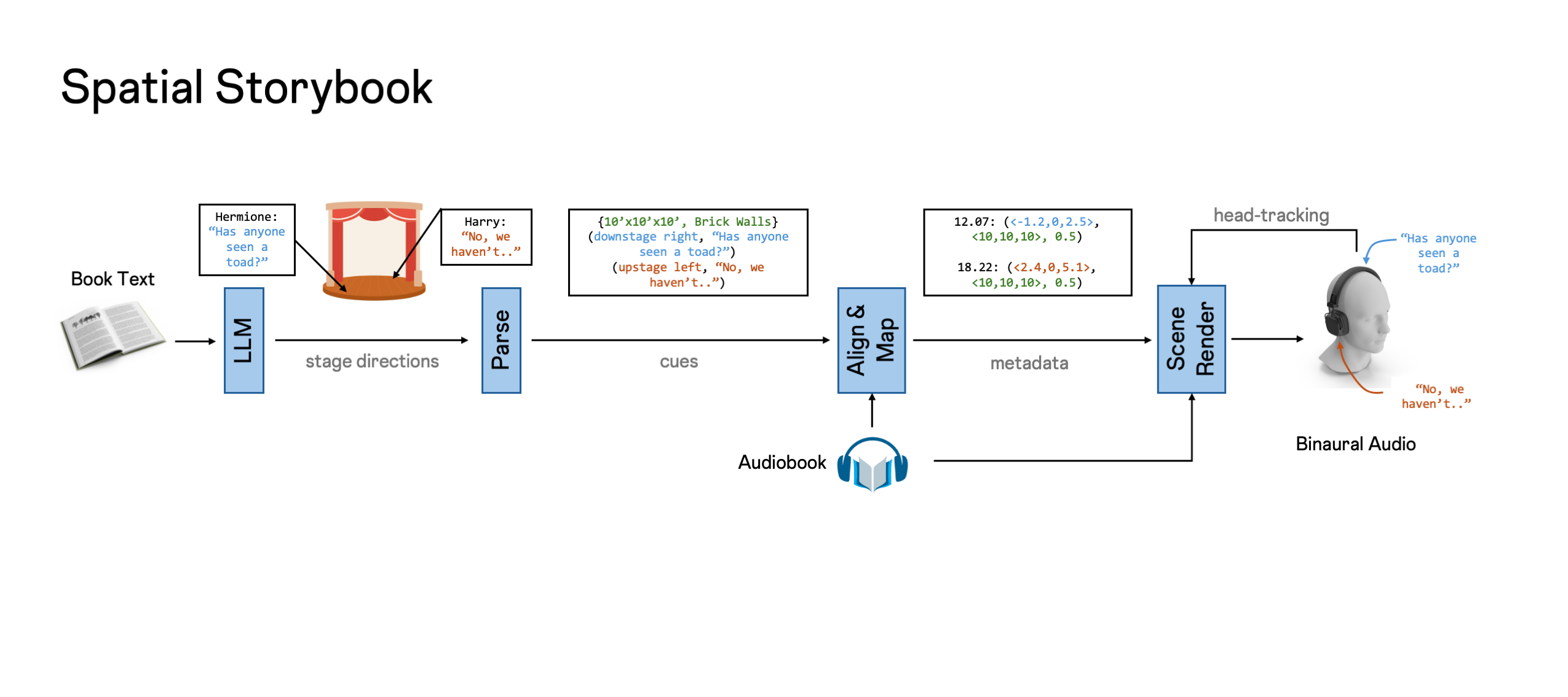
The Spatial Storybook system automatically converts a monaural audiobook into an immersive binaural presentation. It is comprised of an LLM prompted to reimagine a passage of text as a stage play, including stage directions and descriptions of rooms and wall materials; this information conditions a custom, real-time scene rendering engine.
References:
[1] Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Nieto, David Bourgin, Andrew Owens, and Justin Salamon. 2024. Video-guided foley sound generation with multimodal controls. arXiv preprint arXiv:https://arXiv.org/abs/2411.17698 (2024).
[2] Zikai Chen, Lin Wu, Junjie Pan, Xiang Yin, and AI Bytedance. 2022. An Automatic Soundtracking System for Text-to-Speech Audiobooks. In INTERSPEECH. 476–480.
[3] Kentaro Kitamura and Katsunobu Itou. 2023. Binaural Audio Synthesis with the Structured State Space sequence model. In 2023 9th International Conference on Computer and Communications (ICCC). 1505–1509.
[4] Oleksii Kuchaiev, Jason Li, Huyen Nguyen, Oleksii Hrinchuk, Ryan Leary, Boris Ginsburg, Samuel Kriman, Stanislav Beliaev, Vitaly Lavrukhin, Jack Cook, et al. 2019. Nemo: a toolkit for building ai applications using neural modules. arXiv preprint arXiv:https://arXiv.org/abs/1909.09577 (2019).
[5] Jin Woo Lee and Kyogu Lee. 2023. Neural fourier shift for binaural speech rendering. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5.
[6] Alon Levkovitch, Julian Salazar, Soroosh Mariooryad, RJ Skerry-Ryan, Nadav Bar, Bastiaan Kleijn, and Eliya Nachmani. 2024. Zero-Shot Mono-to-Binaural Speech Synthesis. arXiv preprint arXiv:https://arXiv.org/abs/2412.08356 (2024).
[7] Alexander Richard, Dejan Markovic, Israel D Gebru, Steven Krenn, Gladstone Alexander Butler, Fernando Torre, and Yaser Sheikh. 2021. Neural synthesis of binaural speech from mono audio. In International Conference on Learning Representations.
[8] Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Jun Zhang, Lu Lu, Zejun Ma, Yuxuan Wang, et al. 2024. Can Large Language Models Understand Spatial Audio? arXiv preprint arXiv:https://arXiv.org/abs/2406.07914 (2024).
[9] Li Yujian and Liu Bo. 2007. A normalized Levenshtein distance metric. IEEE transactions on pattern analysis and machine intelligence 29, 6 (2007), 1091–1095.
[10] Zhisheng Zheng, Puyuan Peng, Ziyang Ma, Xie Chen, Eunsol Choi, and David Harwath. 2024. Bat: Learning to reason about spatial sounds with large language models. arXiv preprint arXiv:https://arXiv.org/abs/2402.01591 (2024).