
“ShaDDR: Interactive Example-Based Geometry and Texture Generation via 3D Shape Detailization and Differentiable Rendering” by Chen, Chen, Zhou and Zhang
Conference:
Type(s):
Title:
- ShaDDR: Interactive Example-Based Geometry and Texture Generation via 3D Shape Detailization and Differentiable Rendering
Session/Category Title:
- From Pixels to Gradients
Presenter(s)/Author(s):
Abstract:
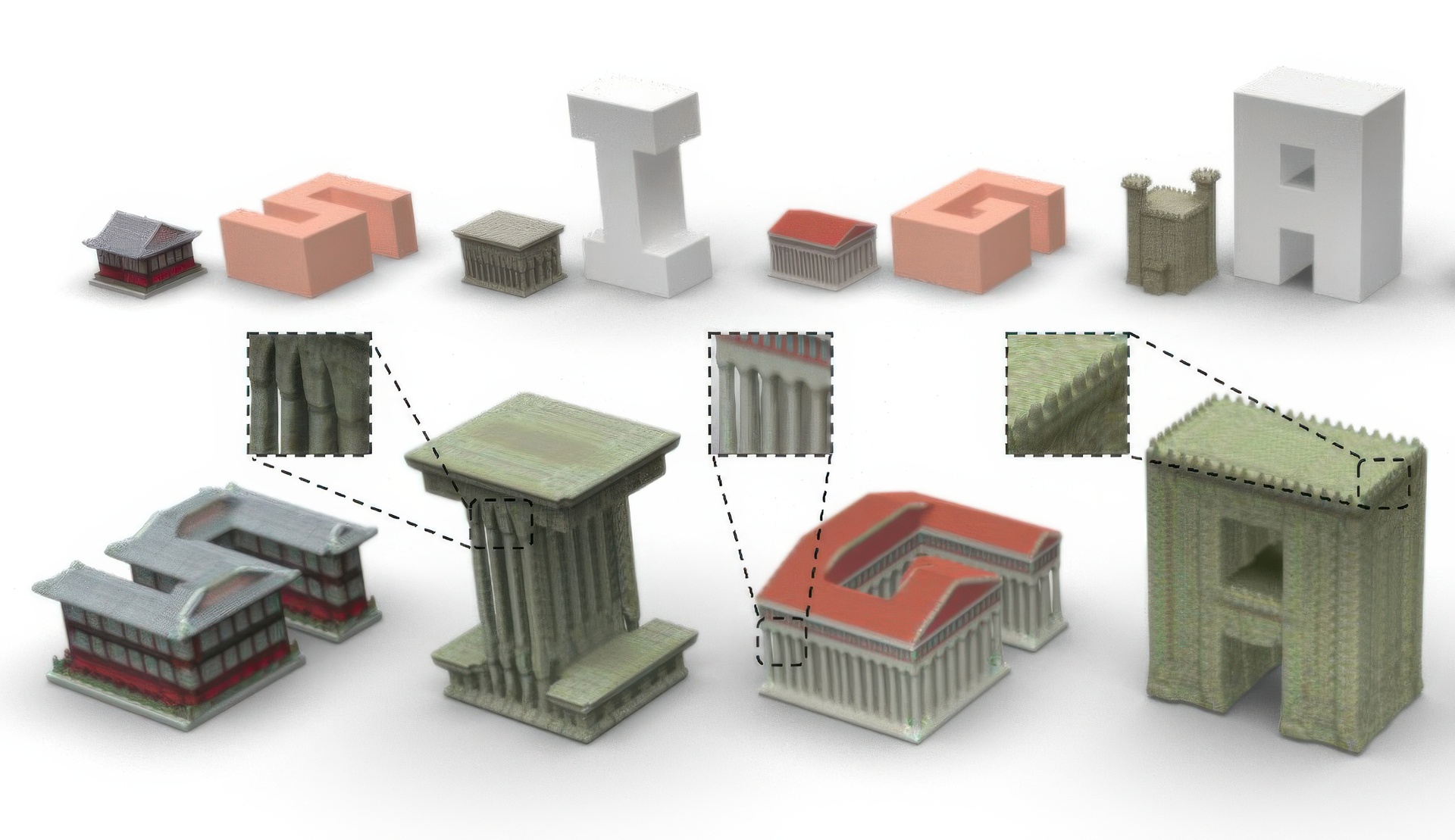
We present ShaDDR, an example-based deep generative neural network which produces a high-resolution textured 3D shape through geometry detailization and conditional texture generation applied to an input coarse voxel shape. Trained on a small set of detailed and textured exemplar shapes, our method learns to detailize the geometry via multi-resolution voxel upsampling and generate textures on voxel surfaces via differentiable rendering against exemplar texture images from a few views. The generation is real-time, taking less than 1 second to produce a 3D model with voxel resolutions up to 512^3. The generated shape preserves the overall structure of the input coarse voxel model, while the style of the generated geometric details and textures can be manipulated through learned latent codes. In the experiments, we show that our method can generate higher-resolution shapes with plausible and improved geometric details and clean textures compared to prior works. Furthermore, we showcase the ability of our method to learn geometric details and textures from shapes reconstructed from real-world photos. In addition, we have developed an interactive modeling application to demonstrate the generalizability of our method to various user inputs and the controllability it offers, allowing users to interactively sculpt a coarse voxel shape to define the overall structure of the detailized 3D shape.
References:
[1]
Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. 2018. Learning representations and generative models for 3D point clouds. In ICLR. 40–49.
[2]
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, 2022. Efficient geometry-aware 3D generative adversarial networks. In CVPR. 16123–16133.
[3]
Eric R Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. 2021. pi-GAN: Periodic implicit generative adversarial networks for 3D-aware image synthesis. In CVPR. 5799–5809.
[4]
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, 2015. ShapeNet: An information-rich 3D model repository. arXiv preprint arXiv:1512.03012 (2015).
[5]
Bindita Chaudhuri, Nikolaos Sarafianos, Linda Shapiro, and Tony Tung. 2021. Semi-supervised synthesis of high-resolution editable textures for 3D humans. In CVPR. 7991–8000.
[6]
Kevin Chen, Christopher B Choy, Manolis Savva, Angel X Chang, Thomas Funkhouser, and Silvio Savarese. 2019a. Text2Shape: Generating shapes from natural language by learning joint embeddings. In ACCV. 100–116.
[7]
Wenzheng Chen, Huan Ling, Jun Gao, Edward Smith, Jaakko Lehtinen, Alec Jacobson, and Sanja Fidler. 2019b. Learning to predict 3D objects with an interpolation-based differentiable renderer. In NeurIPS.
[8]
Xiaobai Chen, Tom Funkhouser, Dan B Goldman, and Eli Shechtman. 2012. Non-parametric texture transfer using meshmatch. Technical Report (2012).
[9]
Zhiqin Chen, Vladimir G. Kim, Matthew Fisher, Noam Aigerman, Hao Zhang, and Siddhartha Chaudhuri. 2021. DECOR-GAN: 3D Shape detailization by conditional refinement. In CVPR. 15740–15749.
[10]
Zhiqin Chen, Kangxue Yin, and Sanja Fidler. 2022. AUV-Net: Learning aligned UV maps for texture transfer and synthesis. In CVPR. 1465–1474.
[11]
Zhiqin Chen and Hao Zhang. 2019. Learning implicit fields for generative shape modeling. In CVPR. 5939–5948.
[12]
Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tuyakov, Alex Schwing, and Liangyan Gui. 2023. SDFusion: Multimodal 3D shape completion, reconstruction, and generation. In CVPR.
[13]
Christopher B Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, and Silvio Savarese. 2016. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In ECCV. 628–644.
[14]
George R Cross and Anil K Jain. 1983. Markov random field texture models. IEEE Transactions on Pattern Analysis and Machine Intelligence1 (1983), 25–39.
[15]
Alexei A Efros and William T Freeman. 2001. Image quilting for texture synthesis and transfer. In Proceedings of Annual Conference on Computer Graphics and Interactive Techniques. 341–346.
[16]
Alexei A Efros and Thomas K Leung. 1999. Texture synthesis by non-parametric sampling. In ICCV, Vol. 2. 1033–1038.
[17]
Haoqiang Fan, Hao Su, and Leonidas J Guibas. 2017. A point set generation network for 3D object reconstruction from a single image. In CVPR. 605–613.
[18]
Noa Fish, Lilach Perry, Amit Bermano, and Daniel Cohen-Or. 2020. SketchPatch: Sketch stylization via seamless patch-level synthesis. ACM Transactions on Graphics 39, 6 (2020), 1–14.
[19]
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. 2022. GET3D: A generative model of high quality 3D textured shapes learned from images. In NeurIPS.
[20]
Lin Gao, Tong Wu, Yu-Jie Yuan, Ming-Xian Lin, Yu-Kun Lai, and Hao Zhang. 2021. TM-NET: Deep generative networks for textured meshes. ACM Transactions on Graphics 40, 6 (2021), 1–15.
[21]
Lin Gao, Jie Yang, Tong Wu, Yu-Jie Yuan, Hongbo Fu, Yu-Kun Lai, and Hao Zhang. 2019. SDM-NET: Deep generative network for structured deformable mesh. ACM Transactions on Graphics 38, 6 (2019), 1–15.
[22]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
[23]
Thibault Groueix, Matthew Fisher, Vladimir G Kim, Bryan C Russell, and Mathieu Aubry. 2018. A papier-mâché approach to learning 3D surface generation. In CVPR. 216–224.
[24]
Christian Häne, Shubham Tulsiani, and Jitendra Malik. 2017. Hierarchical surface prediction for 3D object reconstruction. In 3DV. 412–420.
[25]
Paul Henderson, Vagia Tsiminaki, and Christoph H Lampert. 2020. Leveraging 2D data to learn textured 3D mesh generation. In CVPR. 7498–7507.
[26]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In NeurIPS.
[27]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. NeurIPS 33 (2020), 6840–6851.
[28]
Ka-Hei Hui, Ruihui Li, Jingyu Hu, and Chi-Wing Fu. 2022. Neural wavelet-domain diffusion for 3D shape generation. In SIGGRAPH Asia Conference Papers. 1–9.
[29]
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2017. Image-to-image translation with conditional adversarial networks. In CVPR. 1125–1134.
[30]
Animesh Karnewar, Tobias Ritschel, Oliver Wang, and Niloy Mitra. 2022. 3inGAN: Learning a 3D Generative Model from Images of a Self-similar Scene. In 3DV.
[31]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013).
[32]
Johannes Kopf, Chi-Wing Fu, Daniel Cohen-Or, Oliver Deussen, Dani Lischinski, and Tien-Tsin Wong. 2007. Solid texture synthesis from 2D exemplars. In ACM SIGGRAPH 2007 papers. 2–es.
[33]
Jun Li, Kai Xu, Siddhartha Chaudhuri, Ersin Yumer, Hao Zhang, and Leonidas Guibas. 2017. GRASS: Generative recursive autoencoders for shape structures. ACM Transactions on Graphics 36, 4 (2017), 1–14.
[34]
Weiyu Li, Xuelin Chen, Jue Wang, and Baoquan Chen. 2023. Patch-Based 3D Natural Scene Generation From a Single Example. In CVPR. 16762–16772.
[35]
Xueting Li, Sifei Liu, Kihwan Kim, Shalini De Mello, Varun Jampani, Ming-Hsuan Yang, and Jan Kautz. 2020. Self-supervised single-view 3D reconstruction via semantic consistency. In ECCV. 677–693.
[36]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3D: High-Resolution Text-to-3D Content Creation. In CVPR.
[37]
William E. Lorensen and Harvey E. Cline. 1987. Marching cubes: A high resolution 3D surface construction algorithm. In SIGGRAPH.
[38]
Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, and Andrea Vedaldi. 2023. RealFusion: 360 reconstruction of any object from a single image. In CVPR. 8446–8455.
[39]
Paul Merrell. 2007. Example-based model synthesis. In Proceedings of Interactive 3D Graphics and Games. 105–112.
[40]
Paul Merrell and Dinesh Manocha. 2008. Continuous model synthesis. In ACM SIGGRAPH Asia 2008 papers. 1–7.
[41]
Paul Merrell and Dinesh Manocha. 2010. Model synthesis: A general procedural modeling algorithm. IEEE Transactions on Visualization and Computer Graphics 17, 6 (2010), 715–728.
[42]
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. 2019. Occupancy networks: Learning 3D reconstruction in function space. In CVPR. 4460–4470.
[43]
Oscar Michel, Roi Bar-On, Richard Liu, Sagie Benaim, and Rana Hanocka. 2022. Text2Mesh: Text-driven neural stylization for meshes. In CVPR. 13492–13502.
[44]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. NeRF: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 1 (2021), 99–106.
[45]
Kaichun Mo, Paul Guerrero, Li Yi, Hao Su, Peter Wonka, Niloy Mitra, and Leonidas J Guibas. 2019. StructureNet: Hierarchical graph networks for 3D shape generation. ACM Transactions on Graphics 38, 6 (2019), 1–19.
[46]
Nasir Mohammad Khalid, Tianhao Xie, Eugene Belilovsky, and Tiberiu Popa. 2022. CLIP-Mesh: Generating textured meshes from text using pretrained image-text models. In SIGGRAPH Asia Conference Papers. 1–8.
[47]
Tom Monnier, Matthew Fisher, Alexei A. Efros, and Mathieu Aubry. 2022. Share With Thy Neighbors: Single-view reconstruction by cross-instance consistency. In ECCV.
[48]
Thu Nguyen-Phuoc, Chuan Li, Lucas Theis, Christian Richardt, and Yong-Liang Yang. 2019. HoloGAN: Unsupervised Learning of 3D Representations From Natural Images. In ICCV.
[49]
Michael Niemeyer and Andreas Geiger. 2021. GIRAFFE: Representing scenes as compositional generative neural feature fields. In CVPR. 11453–11464.
[50]
Michael Oechsle, Lars Mescheder, Michael Niemeyer, Thilo Strauss, and Andreas Geiger. 2019. Texture Fields: Learning texture representations in function space. In ICCV. 4531–4540.
[51]
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. 2019. DeepSDF: Learning continuous signed distance functions for shape representation. In CVPR. 165–174.
[52]
Dario Pavllo, Jonas Kohler, Thomas Hofmann, and Aurelien Lucchi. 2021. Learning generative models of textured 3D meshes from real-world images. In ICCV. 13879–13889.
[53]
Dario Pavllo, Graham Spinks, Thomas Hofmann, Marie-Francine Moens, and Aurelien Lucchi. 2020. Convolutional generation of textured 3D meshes. NeurIPS 33 (2020), 870–882.
[54]
Daryl Peralta, Joel Casimiro, Aldrin Michael Nilles, Justine Aletta Aguilar, Rowel Atienza, and Rhandley Cajote. 2020. Next-best view policy for 3D reconstruction. In ECCV Workshop. 558–573.
[55]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2022. DreamFusion: Text-to-3D using 2D diffusion. arXiv preprint arXiv:2209.14988 (2022).
[56]
Amit Raj, Cusuh Ham, Connelly Barnes, Vladimir Kim, Jingwan Lu, and James Hays. 2019. Learning to generate textures on 3D meshes. In CVPR Workshops. 32–38.
[57]
Daniel Rebain, Mark Matthews, Kwang Moo Yi, Dmitry Lagun, and Andrea Tagliasacchi. 2022. LOLNeRF: Learn from one look. In CVPR. 1558–1567.
[58]
Danilo Rezende and Shakir Mohamed. 2015. Variational inference with normalizing flows. In ICLR. 1530–1538.
[59]
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. 2023. TEXTure: Text-guided texturing of 3D shapes. In SIGGRAPH.
[60]
Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. 2020. GRAF: Generative radiance fields for 3D-aware image synthesis. NeurIPS 33 (2020), 20154–20166.
[61]
Tamar Rott Shaham, Tali Dekel, and Tomer Michaeli. 2019. SinGAN: Learning a generative model from a single natural image. In ICCV. 4570–4580.
[62]
Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. 2021. Deep Marching Tetrahedra: a hybrid representation for high-resolution 3D shape synthesis. In NeurIPS.
[63]
Yawar Siddiqui, Justus Thies, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. 2022. Texturify: Generating Textures on 3D Shape Surfaces. In ECCV. 72–88.
[64]
Ivan Skorokhodov, Sergey Tulyakov, Yiqun Wang, and Peter Wonka. 2022. EpiGRAF: Rethinking training of 3D GANs. In NeurIPS.
[65]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In ICML. PMLR, 2256–2265.
[66]
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. 2023. Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior. arxiv:2303.14184 [cs.CV]
[67]
Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, 2016. Conditional image generation with PixelCNN decoders. NeurIPS 29 (2016).
[68]
Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. 2018. Pixel2Mesh: Generating 3D mesh models from single RGB images. In ECCV. 52–67.
[69]
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. 2021. NeuS: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In NeurIPS.
[70]
Yujie Wang, Xuelin Chen, and Baoquan Chen. 2022. SinGRAV: Learning a generative radiance volume from a single natural scene. arXiv preprint arXiv:2210.01202 (2022).
[71]
Jiajun Wu, Chengkai Zhang, Tianfan Xue, Bill Freeman, and Josh Tenenbaum. 2016. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. NeurIPS 29 (2016).
[72]
Rundi Wu and Changxi Zheng. 2022. Learning to generate 3D shapes from a single example. ACM Transactions on Graphics 41, 6 (2022), 1–19.
[73]
Kangxue Yin, Zhiqin Chen, Hui Huang, Daniel Cohen-Or, and Hao Zhang. 2019. LOGAN: Unpaired shape transform in latent overcomplete space. ACM Transactions on Graphics 38, 6 (2019), 1–13.
[74]
Kangxue Yin, Jun Gao, Maria Shugrina, Sameh Khamis, and Sanja Fidler. 2021. 3DStyleNet: Creating 3D shapes with geometric and texture style variations. In ICCV. 12456–12465.
[75]
Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, and Karsten Kreis. 2022. LION: Latent point diffusion models for 3D shape generation. In NeurIPS.
[76]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR. 586–595.
[77]
Yuxuan Zhang, Wenzheng Chen, Huan Ling, Jun Gao, Yinan Zhang, Antonio Torralba, and Sanja Fidler. 2020. Image GANs meet differentiable rendering for inverse graphics and interpretable 3D neural rendering. In ICLR.
[78]
Yuxuan Zhang, Wenzheng Chen, Huan Ling, Jun Gao, Yinan Zhang, Antonio Torralba, and Sanja Fidler. 2021. Image GANs meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering. In International Conference on Learning Representations.
[79]
Kun Zhou, Xin Huang, Xi Wang, Yiying Tong, Mathieu Desbrun, Baining Guo, and Heung-Yeung Shum. 2006. Mesh quilting for geometric texture synthesis. In ACM SIGGRAPH 2006 Papers. 690–697.
[80]
Yang Zhou, Zhen Zhu, Xiang Bai, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. 2018. Non-stationary texture synthesis by adversarial expansion. ACM Transactions on Graphics 37, 4 (2018), 1–13.