
“Scene mover: automatic move planning for scene arrangement by deep reinforcement learning” by Wang, Liang and Yu
Conference:
Type(s):
Title:
- Scene mover: automatic move planning for scene arrangement by deep reinforcement learning
Session/Category Title:
- Learning to Move and Synthesize
Presenter(s)/Author(s):
Abstract:
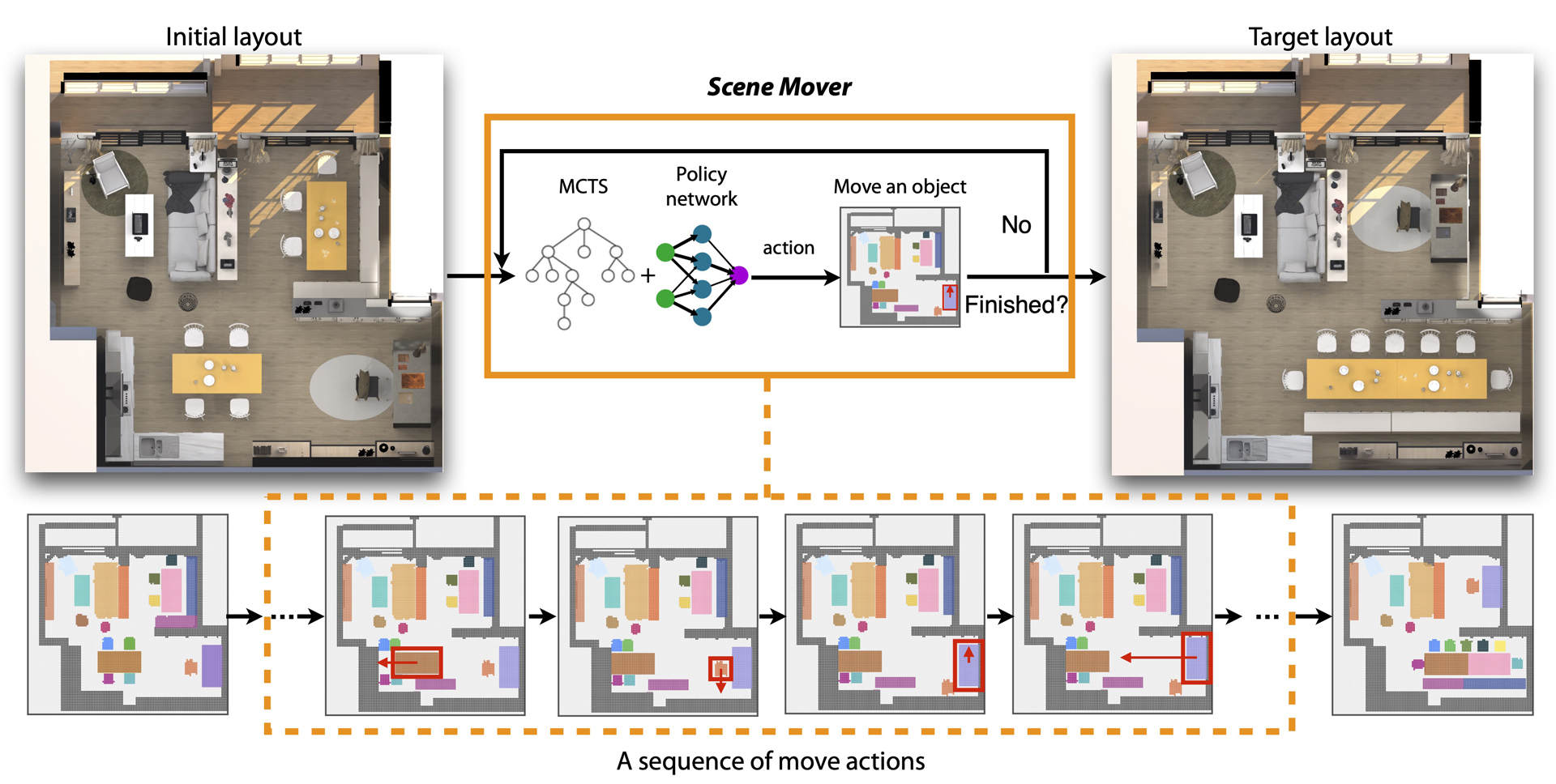
We propose a novel approach for automatically generating a move plan for scene arrangement.1 Given a scene like an apartment with many furniture objects, to transform its layout into another layout, one would need to determine a collision-free move plan. It could be challenging to design this plan manually because the furniture objects may block the way of each other if not moved properly; and there is a large complex search space of move action sequences that grow exponentially with the number of objects. To tackle this challenge, we propose a learning-based approach to generate a move plan automatically. At the core of our approach is a Monte Carlo tree that encodes possible states of the layout, based on which a search is performed to move a furniture object appropriately in the current layout. We trained a policy neural network embedded with a LSTM module for estimating the best actions to take in the expansion step and simulation step of the Monte Carlo tree search process. Leveraging the power of deep reinforcement learning, the network learned how to make such estimations through millions of trials of moving objects. We demonstrated our approach for moving objects under different scenarios and constraints. We also evaluated our approach on synthetic and real-world layouts, comparing its performance with that of humans and other baseline approaches.
References:
1. Douglas Aberdeen, Sylvie Thiébaux, and Lin Zhang. 2004. Decision-theoretic military operations planning. In International Conf. on Automated Planning and Scheduling.Google Scholar
2. Christos Alexopoulos and Paul M Griffin. 1992. Path planning for a mobile robot. IEEE Trans. on systems, man, and cybernetics 22, 2 (1992), 318–322.Google ScholarCross Ref
3. Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. 2016. Learning to learn by gradient descent by gradient descent. In NIPS.Google Scholar
4. Thomas Anthony, Zheng Tian, and David Barber. 2017. Thinking fast and slow with deep learning and tree search. In Advances in Neural Information Processing Systems.Google Scholar
5. Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. 2002. Finite-time analysis of the multiarmed bandit problem. Machine learning 47, 2–3 (2002), 235–256.Google Scholar
6. Andrew Best, Sahil Narang, Daniel Barber, and Dinesh Manocha. 2017. Autonovi: Autonomous vehicle planning with dynamic maneuvers and traffic constraints. In International Conference on Intelligent Robots and Systems. IEEE, 2629–2636.Google ScholarCross Ref
7. Sumana Biswas, Sreenatha G Anavatti, and Matthew A Garratt. 2017. Obstacle avoidance for multi-agent path planning based on vectorized particle swarm optimization. In Intelligent and Evolutionary Systems. Springer, 61–74.Google Scholar
8. Rodney A Brooks and Tomas Lozano-Perez. 1985. A subdivision algorithm in configuration space for findpath with rotation. IEEE Trans. on Systems, Man, and Cybernetics 2 (1985), 224–233.Google ScholarCross Ref
9. Murray Campbell, A Joseph Hoane Jr, and Feng-hsiung Hsu. 2002. Deep blue. Artificial Intelligence 134, 1–2 (2002), 57–83.Google ScholarDigital Library
10. Guillaume Chaslot, Sander Bakkes, Istvan Szita, and Pieter Spronck. 2008. Monte-Carlo Tree Search: A New Framework for Game AI.. In AIIDE.Google Scholar
11. Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. 2017. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. In IEEE CVPR.Google Scholar
12. Matthew Fisher, Manolis Savva, Yangyan Li, Pat Hanrahan, and Matthias Nießner. 2015. Activity-centric Scene Synthesis for Functional 3D Scene Modeling. ACM Trans. on Graphics 34, 6 (2015).Google ScholarDigital Library
13. Keith Frankish and William M Ramsey. 2014. The Cambridge handbook of artificial intelligence. Cambridge University Press.Google Scholar
14. Qiang Fu, Xiaowu Chen, Xiaotian Wang, Sijia Wen, Bin Zhou, and Hongbo Fu. 2017. Adaptive synthesis of indoor scenes via activity-associated object relation graphs. Acm Trans. on Graphics 36, 6 (2017), 201.Google ScholarDigital Library
15. Santiago Garrido, Luis Moreno, and Pedro U Lima. 2011. Robot formation motion planning using fast marching. Robotics and Autonomous Systems 59, 9 (2011).Google Scholar
16. Alessandro Gasparetto, Paolo Boscariol, Albano Lanzutti, and Renato Vidoni. 2015. Path planning and trajectory planning algorithms: A general overview. In Motion and Operation Planning of Robotic Systems. Springer, 3–27.Google Scholar
17. Russell Gayle, Paul Segars, Ming C. Lin, and Dinesh Manocha. 2005. Path Planning for Deformable Robots in Complex Environments. In Robotics: Science and Systems.Google Scholar
18. Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft actorcritic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290 (2018).Google Scholar
19. Peter E Hart, Nils J Nilsson, and Bertram Raphael. 1968. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. on Systems Science and Cybernetics 4, 2 (1968), 100–107.Google ScholarCross Ref
20. Matthew Hausknecht and Peter Stone. 2015. Deep recurrent q-learning for partially observable mdps. CoRR, abs/1507.06527 7, 1 (2015).Google Scholar
21. Joshua A Haustein, Isac Arnekvist, Johannes Stork, Kaiyu Hang, and Danica Kragic. 2019. Learning Manipulation States and Actions for Efficient Non-prehensile Rearrangement Planning. arXiv preprint arXiv:1901.03557 (2019).Google Scholar
22. Joshua A Haustein, Jennifer King, Siddhartha S Srinivasa, and Tamim Asfour. 2015. Kinodynamic randomized rearrangement planning via dynamic transitions between statically stable states. In IEEE ICRA.Google Scholar
23. Gene Eu Jan, Chi-Chia Sun, Wei Chun Tsai, and Ting-Hsiang Lin. 2014. An O(nlogn) Shortest Path Algorithm Based on Delaunay Triangulation. IEEE/ASME Trans. On Mechatronics 19, 2 (2014), 660–666.Google ScholarCross Ref
24. Jennifer E King, Marco Cognetti, and Siddhartha S Srinivasa. 2016. Rearrangement planning using object-centric and robot-centric action spaces. In IEEE ICRA.Google Scholar
25. Jennifer E King, Vinitha Ranganeni, and Siddhartha S Srinivasa. 2017. Unobservable monte carlo planning for nonprehensile rearrangement tasks. In IEEE ICRA.Google Scholar
26. Jens Kober, J Andrew Bagnell, and Jan Peters. 2013. Reinforcement learning in robotics: A survey. The International Journal of Robotics Research 32, 11 (2013), 1238–1274.Google ScholarDigital Library
27. Michael C Koval, Jennifer E King, Nancy S Pollard, and Siddhartha S Srinivasa. 2015. Robust trajectory selection for rearrangement planning as a multi-armed bandit problem. In 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems.Google ScholarCross Ref
28. Yann Labbé, Sergey Zagoruyko, Igor Kalevatykh, Ivan Laptev, Justin Carpentier, Mathieu Aubry, and Josef Sivic. 2020. Monte-Carlo Tree Search for Efficient Visually Guided Rearrangement Planning. IEEE Robotics and Automation Letters (2020).Google ScholarCross Ref
29. Sergey Levine, Peter Pastor, Alex Krizhevsky, Julian Ibarz, and Deirdre Quillen. 2018. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. The International Journal of Robotics Research 37, 4–5 (2018).Google ScholarCross Ref
30. Manyi Li, Akshay Gadi Patil, Kai Xu, Siddhartha Chaudhuri, Owais Khan, Ariel Shamir, Changhe Tu, Baoquan Chen, Daniel Cohen Or, and Hao Zhang. 2019. GRAINS: Generative Recursive Autoencoders for INdoor Scenes. ACM Trans. on Graphics 38 (2019).Google Scholar
31. Rui Ma, Honghua Li, Changqing Zou, Zicheng Liao, Xin Tong, and Hao Zhang. 2016. Action-driven 3D indoor scene evolution. ACM Trans. Graph. 35, 6 (2016), 173–1.Google ScholarDigital Library
32. Paul Merrell, Eric Schkufza, and Vladlen Koltun. 2010. Computer-generated residential building layouts. In ACM Trans. on Graphics, Vol. 29. ACM, 181.Google ScholarCross Ref
33. Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 2016. Asynchronous methods for deep reinforcement learning. In ICML.Google ScholarDigital Library
34. Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529.Google Scholar
35. Brendan O’Donoghue, Rémi Munos, Koray Kavukcuoglu, and Volodymyr Mnih. 2016. PGQ: Combing Policy Gradient and Q. arXiv preprint arXiv:1611.01626 (2016).Google Scholar
36. Chi-Han Peng, Yong-Liang Yang, and Peter Wonka. 2014. Computing layouts with deformable templates. ACM Trans. on Graphics 33, 4 (2014), 99.Google ScholarDigital Library
37. Siyuan Qi, Yixin Zhu, Siyuan Huang, Chenfanfu Jiang, and Song Chun Zhu. 2018. Human-centric Indoor Scene Synthesis Using Stochastic Grammar. In IEEE CVPR.Google Scholar
38. Daniel Ritchie, Kai Wang, and Yu-an Lin. 2019. Fast and Flexible Indoor Scene Synthesis via Deep Convolutional Generative Models. In IEEE CVPR.Google Scholar
39. Manolis Savva, Angel X Chang, Pat Hanrahan, Matthew Fisher, and Matthias Nießner. 2016. PiGraphs: learning interaction snapshots from observations. ACM Trans. on Graphics 35, 4 (2016), 139.Google ScholarDigital Library
40. Yelong Shen, Jianshu Chen, Posen Huang, Yuqing Guo, and Jianfeng Gao. 2018. ReinforceWalk: Learning to Walk in Graph with Monte Carlo Tree Search. arXiv: Artificial Intelligence (2018).Google Scholar
41. David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. 2016. Mastering the game of Go with deep neural networks and tree search. Nature 529, 7587 (2016), 484.Google Scholar
42. David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. 2017. Mastering the game of Go without human knowledge. Nature 550, 7676 (2017), 354.Google Scholar
43. Changkyu Song and Abdeslam Boularias. 2019. Object Rearrangement with Nested Nonprehensile Manipulation Actions. arXiv preprint arXiv:1905.07505 (2019).Google Scholar
44. Haoran Song, Joshua A Haustein, Weihao Yuan, Kaiyu Hang, Michael Yu Wang, Danica Kragic, and Johannes A Stork. 2019. Multi-Object Rearrangement with Monte Carlo Tree Search: A Case Study on Planar Nonprehensile Sorting. arXiv preprint arXiv:1912.07024 (2019).Google Scholar
45. Avneesh Sud, Erik Andersen, Sean Curtis, Ming C Lin, and Dinesh Manocha. 2008. Real-time path planning in dynamic virtual environments using multiagent navigation graphs. IEEE Trans. on Visualization and Computer Graphics 14, 3 (2008), 526–538.Google ScholarDigital Library
46. Richard S Sutton and Andrew G Barto. 2011. Reinforcement learning: An introduction. (2011).Google Scholar
47. Jur van den Berg, Jack Snoeyink, Ming Lin, and Dinesh Manocha. 2009. Centralized path planning for multiple robots: Optimal decoupling into sequential plans. In Robotics: Science and Systems.Google Scholar
48. Hanqing Wang, Wenguan Wang, Tianmin Shu, Wei Liang, and Jianbing Shen. 2020. Active Visual Information Gathering for Vision-Language Navigation. In ECCV.Google Scholar
49. Hanqing Wang, Jiaolong Yang, Wei Liang, and Xin Tong. 2019b. Deep Single-View 3D Object Reconstruction with Visual Hull Embedding. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).Google ScholarDigital Library
50. Kai Wang, Yu-an Lin, Ben Weissmann, Manolis Savva, Angel X. Chang, and Daniel Ritchie. 2019a. PlanIT: Planning and Instantiating Indoor Scenes with Relation Graph and Spatial Prior Networks. ACM Trans. on Graphics 38, 4 (2019).Google ScholarDigital Library
51. Kai Wang, Manolis Savva, Angel X Chang, and Daniel Ritchie. 2018. Deep convolutional priors for indoor scene synthesis. ACM Trans. on Graphics 37, 4 (2018), 70.Google ScholarDigital Library
52. Marco Wiering and Martijn Van Otterlo. 2012. Reinforcement learning. Adaptation, Learning, and Optimization 12 (2012), 51.Google Scholar
53. Wenming Wu, Lubin Fan, Ligang Liu, and Peter Wonka. 2018. MIQP-based layout design for building interiors. In Computer Graphics Forum, Vol. 37. 511–521.Google ScholarCross Ref
54. Yi-Ting Yeh, Lingfeng Yang, Matthew Watson, Noah D Goodman, and Pat Hanrahan. 2012. Synthesizing open worlds with constraints using locally annealed reversible jump mcmc. ACM Trans. on Graphics 31, 4 (2012), 56.Google ScholarDigital Library
55. Lap-Fai Yu, Sai Kit Yeung, Chi-Keung Tang, Demetri Terzopoulos, Tony F. Chan, and Stanley Osher. 2011. Make it home: automatic optimization of furniture arrangement. ACM Trans. Graph. 30, 4 (2011), 86.Google ScholarDigital Library
56. Weihao Yuan, Kaiyu Hang, Danica Kragic, Michael Y Wang, and Johannes A Stork. 2019. End-to-end nonprehensile rearrangement with deep reinforcement learning and simulation-to-reality transfer. Robotics and Autonomous Systems 119 (2019).Google Scholar
57. Weihao Yuan, Johannes A Stork, Danica Kragic, Michael Y Wang, and Kaiyu Hang. 2018. Rearrangement with nonprehensile manipulation using deep reinforcement learning. In 2018 IEEE International Conference on Robotics and Automation.Google ScholarCross Ref