
“S3: Speech, Script, and Scene Driven Head and Eye Animation”
Conference:
Type(s):
Title:
- S3: Speech, Script, and Scene Driven Head and Eye Animation
Presenter(s)/Author(s):
Abstract:
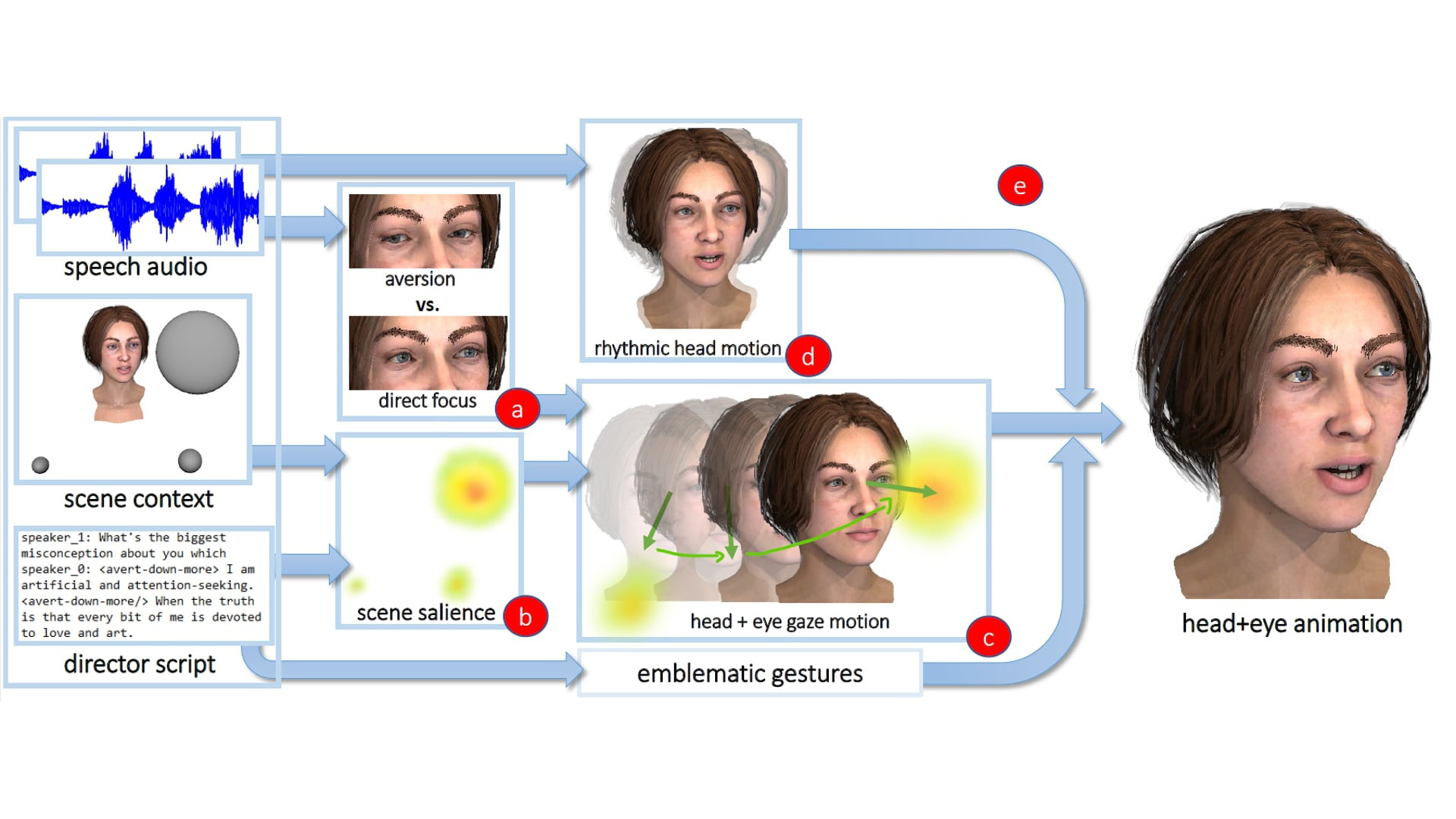
Our method generates 3D head and eye animations for characters in conversation using audio, scripts, and scene inputs. It incorporates animator goals and psycho-linguistic insights, producing realistic animations that align with human behavior and compares favorably with existing approaches, as confirmed by both experts and non-experts.
References:
[1]
Cengiz Acarturk, Bipin Indurkya, Piotr Nawrocki, Bartlomiej Sniezynski, Mateusz Jarosz, and Kerem Alp Usal. 2021. Gaze Aversion in Conversational Settings: An Investigation Based on Mock Job Interview. Journal of Eye Movement Research 14, 1 (May 2021).
[2]
Sean Andrist, Tomislav Pejsa, Bilge Mutlu, and Michael Gleicher. 2012. A Head-Eye Coordination Model for Animating Gaze Shifts of Virtual Characters. In Proceedings of the 4th Workshop on Eye Gaze in Intelligent Human Machine Interaction. ACM, Santa Monica California, 1–6.
[3]
Tenglong Ao, Qingzhe Gao, Yuke Lou, Baoquan Chen, and Libin Liu. 2022. Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings. ACM Transactions on Graphics 41, 6 (Dec. 2022), 1–19. arXiv:2210.01448 [cs, eess] Comment: SIGGRAPH Asia 2022 (Journal Track); Project Page: https://pku-mocca.github.io/Rhythmic-Gesticulator-Page/.
[4]
Michael Argyle and Mark Cook. 1976. Gaze and Mutual Gaze. Cambridge U Press, Oxford, England. xi, 210 pages.
[5]
Michael Argyle and Janet Dean. 1965. Eye-Contact, Distance and Affiliation. Sociometry 28 (1965), 289–304.
[6]
Janet Beavin Bavelas, Linda Coates, and Trudy Johnson. 2002. Listener Responses as a Collaborative Process: The Role of Gaze. Journal of Communication 52, 3 (2002), 566–580.
[7]
Birtukan Birawo and Pawel Kasprowski. 2022. Review and Evaluation of Eye Movement Event Detection Algorithms. Sensors (Basel, Switzerland) 22, 22 (Nov. 2022), 8810.
[8]
Sandika Biswas, Sanjana Sinha, Dipanjan Das, and Brojeshwar Bhowmick. 2021. Realistic Talking Face Animation with Speech-Induced Head Motion. In Proceedings of the Twelfth Indian Conference on Computer Vision, Graphics and Image Processing. ACM, Jodhpur India, 1–9.
[9]
Giuseppe Boccignone, Vittorio Cuculo, Alessandro D’Amelio, Giuliano Grossi, and Raffaella Lanzarotti. 2020. On Gaze Deployment to Audio-Visual Cues of Social Interactions. IEEE Access 8 (2020), 161630–161654.
[10]
Christoph Bregler, Michele Covell, and Malcolm Slaney. 1997. Video Rewrite: Driving Visual Speech with Audio. In Proc. SIGGRAPH.
[11]
Julie N. Buchan, Martin Par?, and Kevin G. Munhall. 2007. Spatial Statistics of Gaze Fixations during Dynamic Face Processing. Social Neuroscience 2, 1 (March 2007), 1–13.
[12]
Ryan Canales, Eakta Jain, and Sophie J?rg. 2023. Real-Time Conversational Gaze Synthesis for Avatars. In Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games (, Rennes, France, ) (MIG ’23). Association for Computing Machinery, New York, NY, USA, Article 17, 7 pages.
[13]
Justine Cassell, Yukiko I. Nakano, Timothy W. Bickmore, Candace L. Sidner, and Charles Rich. 2001. Non-Verbal Cues for Discourse Structure. In Proceedings of the 39th Annual Meeting on Association for Computational Linguistics (Toulouse, France) (ACL ’01). Association for Computational Linguistics, USA, 114–123.
[14]
Justine Cassell, Obed E Torres, and Scott Prevost. 1999. Turn taking versus discourse structure. Machine conversations (1999), 143–153.
[15]
Moran Cerf, Jonathan Harel, Wolfgang Einh?user, and Christof Koch. 2007. Predicting Human Gaze Using Low-Level Saliency Combined with Face Detection. In Adv Neural Inf Process Syst, Vol. 20.
[16]
Byungkuk Choi, Haekwang Eom, Benjamin Mouscadet, Stephen Cullingford, Kurt Ma, Stefanie Gassel, Suzi Kim, Andrew Moffat, Millicent Maier, Marco Revelant, Joe Letteri, and Karan Singh. 2022. Animatomy: An Animator-Centric, Anatomically Inspired System for 3D Facial Modeling, Animation and Transfer. In SIGGRAPH Asia 2022 Conference Papers (Daegu, Republic of Korea) (SA ’22). Association for Computing Machinery, New York, NY, USA, Article 16, 9 pages.
[17]
Susana T.L. Chung, Girish Kumar, Roger W. Li, and Dennis M. Levi. 2015. Characteristics of Fixational Eye Movements in Amblyopia: Limitations on Fixation Stability and Acuity? 114 (2015), 87–99.
[18]
Cagla Cig, Zerrin Kasap, Arjan Egges, and Nadia Magnenat-Thalmann. 2010. Realistic Emotional Gaze and Head Behavior Generation Based on Arousal and Dominance Factors. In Motion in Games (Lecture Notes in Computer Science), Ronan Boulic, Yiorgos Chrysanthou, and Taku Komura (Eds.). Springer, Berlin, Heidelberg, 278–289.
[19]
J. Dawson. 2022. Visual Attention during Conversation: An Investigation Using Real-World Stimuli. Ph. D. Dissertation. University of Essex.
[20]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2–7, 2019, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, 4171–4186.
[21]
Gwyneth Doherty-Sneddon, Deborah M Riby, and Lisa Whittle. 2012. Gaze Aversion as a Cognitive Load Management Strategy in Autism Spectrum Disorder and Williams Syndrome. Journal of Child Psychology and Psychiatry, and Allied Disciplines 53, 4 (April 2012), 420–430.
[22]
Andrew Duchowski, Sophie J?rg, Aubrey Lawson, Takumi Bolte, Lech ?wirski, and Krzysztof Krejtz. 2015. Eye Movement Synthesis with 1/f Pink Noise. In Proceedings of the 8th ACM SIGGRAPH Conference on Motion in Games (MIG ’15). Association for Computing Machinery, New York, NY, USA, 47–56.
[23]
Andrew T. Duchowski, Sophie J?rg, Jaret Screws, Nina A. Gehrer, Michael Sch?nenberg, and Krzysztof Krejtz. 2019. Guiding Gaze: Expressive Models of Reading and Face Scanning. In Proceedings of the 11th ACM Symposium on Eye Tracking Research & Applications (ETRA ’19). Association for Computing Machinery, New York, NY, USA, 1–9.
[24]
Pif Edwards, Chris Landreth, Eugene Fiume, and Karan Singh. 2016. JALI: an animator-centric viseme model for expressive lip synchronization. ACM Transactions on Graphics 35, 4 (July 2016), 1–11.
[25]
Pif Edwards, Chris Landreth, Mateusz Pop?awski, Robert Malinowski, Sarah Watling, Eugene Fiume, and Karan Singh. 2020a. JALI-Driven Expressive Facial Animation and Multilingual Speech in Cyberpunk 2077. In ACM SIGGRAPH 2020 Talks (Virtual Event, USA) (SIGGRAPH ’20). Association for Computing Machinery, New York, NY, USA, Article 60, 2 pages.
[26]
Pif Edwards, Chris Landreth, Mateusz Pop?awski, Robert Malinowski, Sarah Watling, Eugene Fiume, and Karan Singh. 2020b. JALI-Driven Expressive Facial Animation and Multilingual Speech in Cyberpunk 2077. In ACM SIGGRAPH 2020 Talks (Virtual Event, USA) (SIGGRAPH ’20). Association for Computing Machinery, New York, NY, USA, Article 60, 2 pages.
[27]
Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, and Michael Rubinstein. 2018. Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation. ACM Transactions on Graphics 37, 4 (Aug. 2018), 1–11. arXiv:1804.03619 [cs, eess]
[28]
Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, and Taku Komura. 2022. Joint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation. Proc. ACM Comput. Graph. Interact. Tech. 5, 1, Article 16 (may 2022), 15 pages.
[29]
Ylva Ferstl. 2023. Generating Emotionally Expressive Look-At Animation. In Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games (, Rennes, France,) (MIG ’23). Association for Computing Machinery, New York, NY, USA, Article 15, 6 pages.
[30]
Tom Foulsham, Joey Cheng, Jessica Tracy, Joseph Henrich, and Alan Kingstone. 2010. Gaze Allocation in a Dynamic Situation: Effects of Social Status and Speaking. Cognition 117 (Oct. 2010), 319–31.
[31]
Aisha Frampton-Clerk and Oyewole Oyekoya. 2022. Investigating the Perceived Realism of the Other User’s Look-Alike Avatars. In 28th ACM Symposium on Virtual Reality Software and Technology. ACM, Tsukuba Japan, 1–5.
[32]
Saeed Ghorbani, Ylva Ferstl, Daniel Holden, Nikolaus F. Troje, and Marc-Andr? Carbonneau. 2023. ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech. Computer Graphics Forum 42, 1 (2023), 206–216. arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/cgf.14734
[33]
Toni Giorgino. 2009. Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package. Journal of Statistical Software 31, 7 (2009), 1–24.
[34]
A. M. Glenberg, J. L. Schroeder, and D. A. Robertson. 1998. Averting the Gaze Disengages the Environment and Facilitates Remembering. Memory & Cognition 26, 4 (July 1998), 651–658.
[35]
Charles Goodwin. 1980. Restarts, Pauses, and the Achievement of a State of Mutual Gaze at Turn-Beginning. Sociological Inquiry 50, 3–4 (July 1980), 272–302.
[36]
Ific Goud?, Alexandre Bruckert, Anne-H?l?ne Olivier, Julien Pettr?, R?mi Cozot, Kadi Bouatouch, Marc Christie, and Ludovic Hoyet. 2023. Real-Time Multi-map Saliency-driven Gaze Behavior for Non-conversational Characters. IEEE Transactions on Visualization and Computer Graphics (2023), 1–13.
[37]
Jennifer X. Haensel, Tim J. Smith, and Atsushi Senju. 2022. Cultural Differences in Mutual Gaze during Face-to-Face Interactions: A Dual Head-Mounted Eye-Tracking Study. Visual Cognition 30 (2022), 100–115.
[38]
D. Y. P. Henriques, W. P. Medendorp, A. Z. Khan, and J. D. Crawford. 2002. Visuomotor Transformations for Eye-Hand Coordination. Progress in Brain Research 140 (2002), 329–340.
[39]
Simon Ho, Tom Foulsham, and Alan Kingstone. 2015. Speaking and Listening with the Eyes: Gaze Signaling during Dyadic Interactions. PloS One 10, 8 (2015), e0136905.
[40]
Laurent Itti. 2006. Quantitative Modelling of Perceptual Salience at Human Eye Position. Visual Cognition 14, 4–8 (Aug. 2006), 959–984.
[41]
Laurent Itti, Nitin Dhavale, and Frederic Pighin. 2004. Realistic Avatar Eye and Head Animation Using a Neurobiological Model of Visual Attention. In Optical Science and Technology, SPIE’s 48th Annual Meeting, Bruno Bosacchi, David B. Fogel, and James C. Bezdek (Eds.). San Diego, California, USA, 64.
[42]
Du?an Jan, David Herrera, Bilyana Martinovski, David Novick, and David Traum. 2007. A Computational Model of Culture-Specific Conversational Behavior. In Intelligent Virtual Agents (Lecture Notes in Computer Science), Catherine Pelachaud, Jean-Claude Martin, Elisabeth Andr?, G?rard Chollet, Kostas Karpouzis, and Danielle Pel? (Eds.). Springer, Berlin, Heidelberg, 45–56.
[43]
Aobo Jin, Qixin Deng, Yuting Zhang, and Zhigang Deng. 2019. A Deep Learning-Based Model for Head and Eye Motion Generation in Three-party Conversations. Proceedings of the ACM on Computer Graphics and Interactive Techniques 2, 2 (July 2019), 1–19.
[44]
Tero Karras, Timo Aila, Samuli Laine, Antti Herva, and Jaakko Lehtinen. 2017. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Transactions on Graphics 36, 4 (July 2017), 1–12.
[45]
Adam Kendon. 1967. Some Functions of Gaze-Direction in Social Interaction. Acta Psychologica 26 (Jan. 1967), 22–63.
[46]
Mohamed Amine Kerkouri and Aladine Chetouani. 2021. A Simple and Efficient Deep Scanpath Prediction. arXiv:2112.04610 [cs] Comment: Electronic Imaging Symposium 2022 (EI 2022).
[47]
Diederik P. Kingma and Jimmy Ba. 2014. Adam: A Method for Stochastic Optimization. https://arxiv.org/abs/1412.6980v9
[48]
Alex Klein, Zerrin Yumak, Arjen Beij, and A. Frank van der Stappen. 2019. Data-driven Gaze Animation using Recurrent Neural Networks. In Proceedings of the 12th ACM SIGGRAPH Conference on Motion, Interaction and Games (Newcastle upon Tyne, United Kingdom) (MIG ’19). Association for Computing Machinery, New York, NY, USA, Article 4, 11 pages.
[49]
Krzysztof Krejtz, Andrew Duchowski, Heng Zhou, Sophie J?rg, and Anna Niedzielska. 2018. Perceptual Evaluation of Synthetic Gaze Jitter. 29, 6 (2018), e1745.
[50]
Taras Kucherenko, Patrik Jonell, Sanne van Waveren, Gustav Eje Henter, Simon Alexanderson, Iolanda Leite, and Hedvig Kjellstr?m. 2020. Gesticulator: A Framework for Semantically-Aware Speech-Driven Gesture Generation. In Proceedings of the 2020 International Conference on Multimodal Interaction. 242–250. arXiv:2001.09326 [cs, eess] Comment: ICMI 2020 Best Paper Award. Code is available. 9 pages, 6 figures.
[51]
Binh H. Le, Xiaohan Ma, and Zhigang Deng. 2012. Live Speech Driven Head-and-Eye Motion Generators. IEEE Transactions on Visualization and Computer Graphics 18, 11 (Nov. 2012), 1902–1914.
[52]
R. John Leigh and David S. Zee. 2006. The Neurology of Eye Movements.
[53]
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, Wan-Teh Chang, Wei Hua, Manfred Georg, and Matthias Grundmann. 2019. MediaPipe: A Framework for Building Perception Pipelines. CoRR abs/1906.08172 (2019). arXiv:1906.08172 http://arxiv.org/abs/1906.08172
[54]
Laina G. Lusk and Aaron D. Mitchel. 2016. Differential Gaze Patterns on Eyes and Mouth During Audiovisual Speech Segmentation. Frontiers in Psychology 7 (2016).
[55]
Sophie Marat, Tien Ho Phuoc, Lionel Granjon, Nathalie Guyader, Denis Pellerin, and Anne Gu?rin-Dugu?. 2009. Modelling Spatio-Temporal Saliency to Predict Gaze Direction for Short Videos. International Journal of Computer Vision 82, 3 (May 2009), 231–243.
[56]
Stacy Marsella, Yuyu Xu, Margaux Lhommet, Andrew Feng, Stefan Scherer, and Ari Shapiro. 2013. Virtual character performance from speech. In Proceedings of the 12th ACM SIGGRAPH/Eurographics Symposium on Computer Animation (SCA ’13). Association for Computing Machinery, New York, NY, USA, 25–35.
[57]
Anjanie McCarthy, Kang Lee, Shoji Itakura, and Darwin W. Muir. 2008. Gaze Display When Thinking Depends on Culture and Context. Journal of Cross-Cultural Psychology 39 (2008), 716–729.
[58]
Craig H. Meyer, Adrian G. Lasker, and David A. Robinson. 1985. The upper limit of human smooth pursuit velocity. Vision Research 25, 4 (Jan. 1985), 561–563.
[59]
Louis-Philippe Morency, C. Mario Christoudias, and Trevor Darrell. 2006. Recognizing Gaze Aversion Gestures in Embodied Conversational Discourse. In Proceedings of the 8th International Conference on Multimodal Interfaces (ICMI ’06). Association for Computing Machinery, New York, NY, USA, 287–294.
[60]
Atsushi Nakazawa, Yu Mitsuzumi, Yuki Watanabe, Ryo Kurazume, Sakiko Yoshikawa, and Miwako Honda. 2020. First-Person Video Analysis for Evaluating Skill Level in the Humanitude Tender-Care Technique. Journal of Intelligent & Robotic Systems 98, 1 (April 2020), 103–118.
[61]
Aline Normoyle, Jeremy B. Badler, Teresa Fan, Norman I. Badler, Vinicius J. Cassol, and Soraia R. Musse. 2013. Evaluating Perceived Trust from Procedurally Animated Gaze. In Proceedings of Motion on Games (Dublin 2, Ireland) (MIG ’13). Association for Computing Machinery, New York, NY, USA, 141–148.
[62]
NVIDIA. 2021. Nemo Speaker Diarization. https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/asr/speaker_diarization/intro.html
[63]
Jason Osipa. 2010. Stop Staring: Facial Modeling and Animation Done Right (3rd ed.). SYBEX Inc.
[64]
Matthew K.X.J. Pan, Sungjoon Choi, James Kennedy, Kyna McIntosh, Daniel Campos Zamora, Gunter Niemeyer, Joohyung Kim, Alexis Wieland, and David Christensen. 2020. Realistic and Interactive Robot Gaze. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, Las Vegas, NV, USA, 11072–11078.
[65]
Yifang Pan, Chris Landreth, Eugene Fiume, and Karan Singh. 2022. VOCAL: Vowel and Consonant Layering for Expressive Animator-Centric Singing Animation. In SIGGRAPH Asia 2022 Conference Papers (Daegu, Republic of Korea) (SA ’22). Association for Computing Machinery, New York, NY, USA, Article 18, 9 pages.
[66]
Frederick I. Parke. 1998. Computer Gernerated Animation of Faces. Association for Computing Machinery, New York, NY, USA, 241–247.
[67]
Tomislav Pejsa, Daniel Rakita, Bilge Mutlu, and Michael Gleicher. 2016. Authoring directed gaze for full-body motion capture. ACM Transactions on Graphics 35, 6 (Dec. 2016), 161:1–161:11.
[68]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022a. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv:2212.04356 [cs, eess]
[69]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022b. Robust Speech Recognition via Large-Scale Weak Supervision. http://arxiv.org/abs/2212.04356 arXiv:2212.04356 [cs, eess].
[70]
Raoudha Rahmeni, Anis Ben Aicha, and Yassine Ben Ayed. 2020. Acoustic features exploration and examination for voice spoofing counter measures with boosting machine learning techniques. Procedia Computer Science 176 (2020), 1073–1082.
[71]
Alexander Richard, Michael Zollhoefer, Yandong Wen, Fernando de la Torre, and Yaser Sheikh. 2021. MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement. arXiv:2104.08223 [cs] (April 2021). http://arxiv.org/abs/2104.08223 arXiv: 2104.08223.
[72]
Federico Rossano. 2012. Gaze in Conversation. In The Handbook of Conversation Analysis (first ed.), Jack Sidnell and Tanya Stivers (Eds.). Wiley, 308–329.
[73]
K. Ruhland, C. E. Peters, S. Andrist, J. B. Badler, N. I. Badler, M. Gleicher, B. Mutlu, and R. McDonnell. 2015. A Review of Eye Gaze in Virtual Agents, Social Robotics and HCI: Behaviour Generation, User Interaction and Perception. Computer Graphics Forum 34, 6 (2015), 299–326.
[74]
Peiteng Shi, Markus Billeter, and Elmar Eisemann. 2020. SalientGaze: Saliency-based Gaze Correction in Virtual Reality. Computers & Graphics 91 (Oct. 2020), 83–94.
[75]
Sinan Sonlu, U?ur G?d?kbay, and Funda Durupinar. 2021. A Conversational Agent Framework with Multi-Modal Personality Expression. ACM Trans. Graph. 40, 1, Article 7 (jan 2021), 16 pages.
[76]
Matthew Stone, Doug DeCarlo, Insuk Oh, Christian Rodriguez, Adrian Stere, Alyssa Lees, and Chris Bregler. 2004. Speaking with Hands: Creating Animated Conversational Characters from Recordings of Human Performance. In ACM SIGGRAPH 2004 Papers (Los Angeles, California) (SIGGRAPH ’04). Association for Computing Machinery, New York, NY, USA, 506–513.
[77]
Yusuke Sugano, Yasuyuki Matsushita, and Yoichi Sato. 2013. Appearance-Based Gaze Estimation Using Visual Saliency. IEEE Transactions on Pattern Analysis and Machine Intelligence 35, 2 (Feb. 2013), 329–341.
[78]
Justus Thies, Mohamed A. Elgharib, Ayush Tewari, C. Theobalt, and M. Nie?ner. 2020. Neural Voice Puppetry: Audio-driven Facial Reenactment. In ECCV.
[79]
J. van der Steen. 2009. Vestibulo-Ocular Reflex (VOR). In Encyclopedia of Neuroscience, Marc D. Binder, Nobutaka Hirokawa, and Uwe Windhorst (Eds.). Springer, Berlin, Heidelberg, 4224–4228.
[80]
Jason Vandeventer, Andrew J. Aubrey, Paul L. Rosin, and David Marshall. 2015. 4D Cardiff Conversation Database (4D CCDb): a 4D database of natural, dyadic conversations. In Proc. Auditory-Visual Speech Processing. 157–162.
[81]
Suzhen Wang, Lincheng Li, Yu Ding, Changjie Fan, and Xin Yu. 2021. Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion. arXiv:2107.09293 [cs]
[82]
Nigel G. Ward, Chelsey N. Jurado, Ricardo A. Garcia, and Florencia A. Ramos. 2016. On the Possibility of Predicting Gaze Aversion to Improve Video-Chat Efficiency. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications (ETRA ’16). Association for Computing Machinery, New York, NY, USA, 267–270.
[83]
Justin W. Weeks, Ashley N. Howell, and Philippe R. Goldin. 2013. Gaze Avoidance in Social Anxiety Disorder. Depression and Anxiety 30, 8 (Aug. 2013), 749–756.
[84]
Thibaut Weise, Hao Li, Luc Van Gool, and Mark Pauly. 2009. Face/Off: live facial puppetry. In Proceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation – SCA ’09. ACM Press, New Orleans, Louisiana, 7.
[85]
Sang Hoon Yeo, Martin Lesmana, Debanga R. Neog, and Dinesh K. Pai. 2012. Eyecatch: Simulating Visuomotor Coordination for Object Interception. ACM Transactions on Graphics 31, 4 (July 2012), 42:1–42:10.
[86]
Sangbong Yoo, Seongmin Jeong, Seokyeon Kim, and Yun Jang. 2021. Saliency-Based Gaze Visualization for Eye Movement Analysis. Sensors (Basel, Switzerland) 21, 15 (July 2021), 5178.
[87]
Youngwoo Yoon, Pieter Wolfert, Taras Kucherenko, Carla Viegas, Teodor Nikolov, Mihail Tsakov, and Gustav Eje Henter. 2022. The GENEA Challenge 2022: A Large Evaluation of Data-Driven Co-Speech Gesture Generation. In Proceedings of the 2022 International Conference on Multimodal Interaction (ICMI ’22). Association for Computing Machinery, New York, NY, USA, 736–747.
[88]
L.R. Young and L. Stark. 1963. Variable Feedback Experiments Testing a Sampled Data Model for Eye Tracking Movements. IEEE Transactions on Human Factors in Electronics HFE-4, 1 (Sept. 1963), 38–51. Conference Name: IEEE Transactions on Human Factors in Electronics.
[89]
Xucong Zhang, Seonwook Park, Thabo Beeler, Derek Bradley, Siyu Tang, and Otmar Hilliges. 2020. ETH-XGaze: A Large Scale Dataset for Gaze Estimation under Extreme Head Pose and Gaze Variation. In European Conference on Computer Vision (ECCV).
[90]
Yang Zhou, Zhan Xu, Chris Landreth, Evangelos Kalogerakis, Subhransu Maji, and Karan Singh. 2018. Visemenet: audio-driven animator-centric speech animation. ACM Transactions on Graphics 37, 4 (Aug. 2018), 1–10.
[91]
Goranka Zoric, Rober Forchheimer, and Igor S. Pandzic. 2011. On Creating Multimodal Virtual Humans—Real Time Speech Driven Facial Gesturing. Multimedia Tools and Applications 54, 1 (Aug. 2011), 165–179.