
“Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings” by Ao, Gao, Lou, Chen and Liu
Conference:
Type(s):
Title:
- Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings
Session/Category Title:
- Face, Speech, and Gesture
Presenter(s)/Author(s):
Abstract:
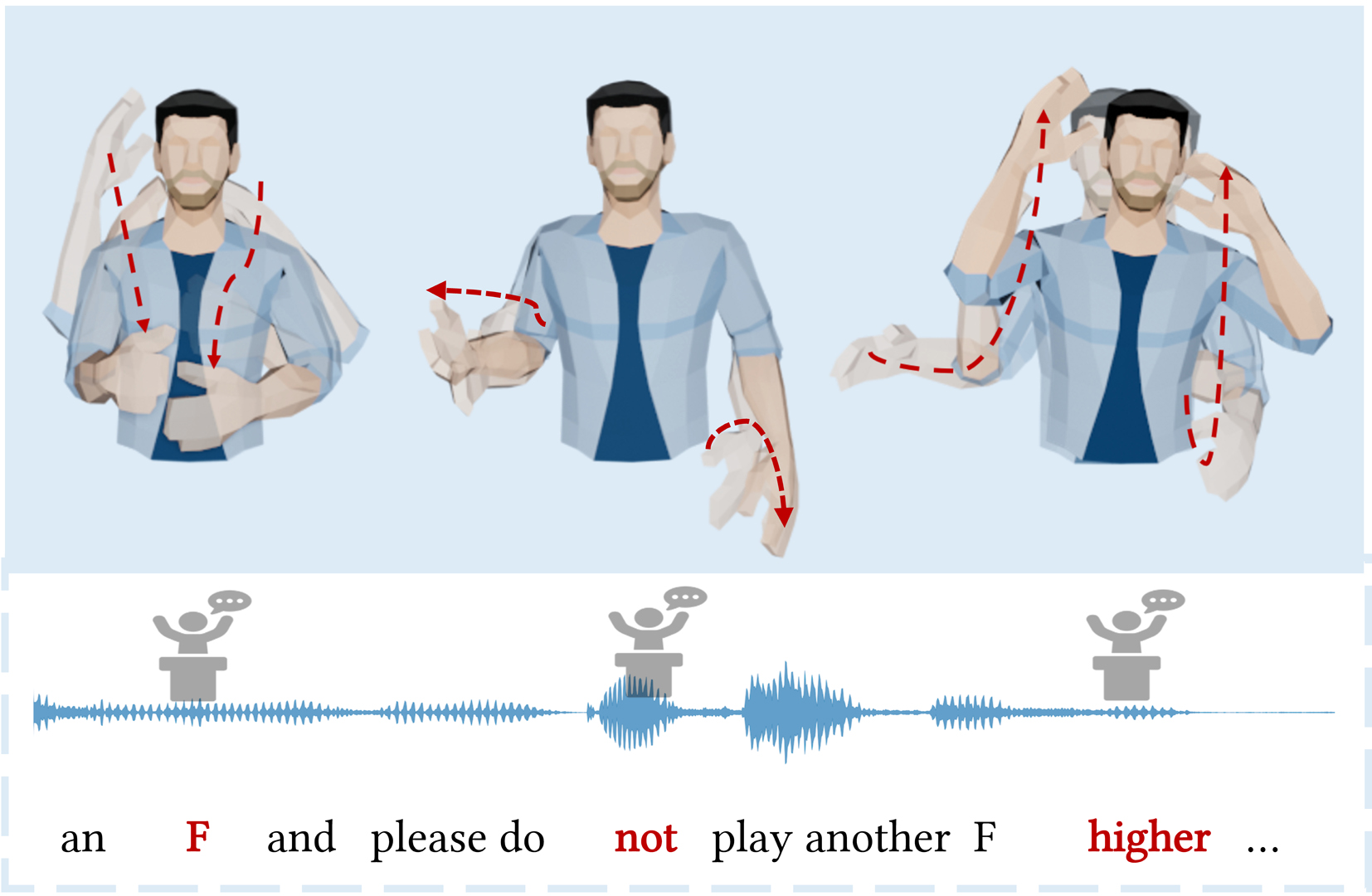
Automatic synthesis of realistic co-speech gestures is an increasingly important yet challenging task in artificial embodied agent creation. Previous systems mainly focus on generating gestures in an end-to-end manner, which leads to difficulties in mining the clear rhythm and semantics due to the complex yet subtle harmony between speech and gestures. We present a novel co-speech gesture synthesis method that achieves convincing results both on the rhythm and semantics. For the rhythm, our system contains a robust rhythm-based segmentation pipeline to ensure the temporal coherence between the vocalization and gestures explicitly. For the gesture semantics, we devise a mechanism to effectively disentangle both low- and high-level neural embeddings of speech and motion based on linguistic theory. The high-level embedding corresponds to semantics, while the low-level embedding relates to subtle variations. Lastly, we build correspondence between the hierarchical embeddings of the speech and the motion, resulting in rhythm- and semantics-aware gesture synthesis. Evaluations with existing objective metrics, a newly proposed rhythmic metric, and human feedback show that our method outperforms state-of-the-art systems by a clear margin.
References:
1. Simon Alexanderson, Gustav Eje Henter, Taras Kucherenko, and Jonas Beskow. 2020. Style-Controllable Speech-Driven Gesture Synthesis Using Normalising Flows. Computer Graphics Forum 39, 2 (2020), 487–496.
2. Andreas Aristidou, Daniel Cohen-Or, Jessica K Hodgins, Yiorgos Chrysanthou, and Ariel Shamir. 2018. Deep motifs and motion signatures. ACM Transactions on Graphics (TOG) 37, 6 (2018), 1–13.
3. Andreas Aristidou, Anastasios Yiannakidis, Kfir Aberman, Daniel Cohen-Or, Ariel Shamir, and Yiorgos Chrysanthou. 2022. Rhythm is a Dancer: Music-Driven Motion Synthesis with Global Structure. IEEE Transactions on Visualization and Computer Graphics (2022), 1–1.
4. Alexei Baevski, Steffen Schneider, and Michael Auli. 2020. vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations. In International Conference on Learning Representations.
5. Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2019. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 2 (2019), 423–443.
6. J.P. Bello, L. Daudet, S. Abdallah, C. Duxbury, M. Davies, and M.B. Sandler. 2005. A Tutorial on Onset Detection in Music Signals. IEEE Transactions on Speech and Audio Processing 13, 5 (Sept. 2005), 1035–1047.
7. Uttaran Bhattacharya, Elizabeth Childs, Nicholas Rewkowski, and Dinesh Manocha. 2021a. Speech2AffectiveGestures: Synthesizing Co-Speech Gestures with Generative Adversarial Affective Expression Learning. In Proceedings of the 29th ACM International Conference on Multimedia (Virtual Event, China) (MM ’21). Association for Computing Machinery, New York, NY, USA, 2027–2036.
8. Uttaran Bhattacharya, Nicholas Rewkowski, Abhishek Banerjee, Pooja Guhan, Aniket Bera, and Dinesh Manocha. 2021b. Text2Gestures: A Transformer-Based Network for Generating Emotive Body Gestures for Virtual Agents. CoRR abs/2101.11101 (2021).
9. Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching word vectors with subword information. Transactions of the association for computational linguistics 5 (2017), 135–146.
10. Judee K Burgoon, Thomas Birk, and Michael Pfau. 1990. Nonverbal behaviors, persuasion, and credibility. Human communication research 17, 1 (1990), 140–169.
11. Justine Cassell, Hannes Högni Vilhjálmsson, and Timothy Bickmore. 2004. Beat: the behavior expression animation toolkit. In Life-Like Characters. Springer, 163–185.
12. Kang Chen, Zhipeng Tan, Jin Lei, Song-Hai Zhang, Yuan-Chen Guo, Weidong Zhang, and Shi-Min Hu. 2021. Choreomaster: choreography-oriented music-driven dance synthesis. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–13.
13. Chung-Cheng Chiu, Louis-Philippe Morency, and Stacy Marsella. 2015. Predicting co-verbal gestures: A deep and temporal modeling approach. In International Conference on Intelligent Virtual Agents. Springer, 152–166.
14. Abe Davis and Maneesh Agrawala. 2018. Visual rhythm and beat. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2532–2535.
15. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. north american chapter of the association for computational linguistics (2019).
16. Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. 2020. Jukebox: A Generative Model for Music. ArXiv abs/2005.00341 (2020).
17. Paul Ekman and Wallace V Friesen. 1969. The repertoire of nonverbal behavior: Categories, origins, usage, and coding. semiotica 1, 1 (1969), 49–98.
18. Daniel PW Ellis. 2007. Beat tracking by dynamic programming. Journal of New Music Research 36, 1 (2007), 51–60.
19. Ylva Ferstl and Rachel McDonnell. 2018. Investigating the use of recurrent motion modelling for speech gesture generation. In Proceedings of the 18th International Conference on Intelligent Virtual Agents. 93–98.
20. Shiry Ginosar, Amir Bar, Gefen Kohavi, Caroline Chan, Andrew Owens, and Jitendra Malik. 2019. Learning individual styles of conversational gesture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3497–3506.
21. Maria Graziano and Marianne Gullberg. 2018. When Speech Stops, Gesture Stops: Evidence From Developmental and Crosslinguistic Comparisons. Frontiers in Psychology 0 (2018).
22. David Greenwood, Stephen Laycock, and Iain Matthews. 2017. Predicting head pose from speech with a conditional variational autoencoder. ISCA.
23. Ikhsanul Habibie, Weipeng Xu, Dushyant Mehta, Lingjie Liu, Hans-Peter Seidel, Gerard Pons-Moll, Mohamed Elgharib, and Christian Theobalt. 2021. Learning speech-driven 3d conversational gestures from video. In Proceedings of the 21st ACM International Conference on Intelligent Virtual Agents. 101–108.
24. Félix G. Harvey, Mike Yurick, Derek Nowrouzezahrai, and Christopher Pal. 2020. Robust Motion In-Betweening. ACM Trans. Graph. 39, 4, Article 60 (jul 2020), 12 pages.
25. Dai Hasegawa, Naoshi Kaneko, Shinichi Shirakawa, Hiroshi Sakuta, and Kazuhiko Sumi. 2018. Evaluation of speech-to-gesture generation using bi-directional LSTM network. In Proceedings of the 18th International Conference on Intelligent Virtual Agents. 79–86.
26. Gustav Eje Henter, Simon Alexanderson, and Jonas Beskow. 2020. Moglow: Probabilistic and controllable motion synthesis using normalising flows. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1–14.
27. Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 (2017).
28. Chieh Ho, Wei-Tze Tsai, Keng-Sheng Lin, and Homer H Chen. 2013. Extraction and alignment evaluation of motion beats for street dance. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2429–2433.
29. Daniel Holden, Taku Komura, and Jun Saito. 2017. Phase-functioned neural networks for character control. ACM Transactions on Graphics (TOG) 36, 4 (2017), 1–13.
30. Chien-Ming Huang and Bilge Mutlu. 2012. Robot behavior toolkit: generating effective social behaviors for robots. In 2012 7th ACM/IEEE International Conference on Human-Robot Interaction (HRI). IEEE, 25–32.
31. Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. 2013. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence 36, 7 (2013), 1325–1339.
32. Eric Jang, Shixiang Gu, and Ben Poole. 2017. Categorical Reparameterization with Gumbel-Softmax. ICLR (2017).
33. Hanbyul Joo, Tomas Simon, Mina Cikara, and Yaser Sheikh. 2019. Towards social artificial intelligence: Nonverbal social signal prediction in a triadic interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10873–10883.
34. Adam Kendon. 2004. Gesture: Visible Action as Utterance. Cambridge University Press, Cambridge.
35. Jae Woo Kim, Hesham Fouad, and James K Hahn. 2006. Making Them Dance.. In AAAI Fall Symposium: Aurally Informed Performance, Vol. 2.
36. Michael Kipp. 2004. Gesture Generation by Imitation: From Human Behavior to Computer Character Animation. Dissertation.com, Boca Raton.
37. Stefan Kopp, Brigitte Krenn, Stacy Marsella, Andrew N Marshall, Catherine Pelachaud, Hannes Pirker, Kristinn R Thórisson, and Hannes Vilhjálmsson. 2006. Towards a common framework for multimodal generation: The behavior markup language. In International workshop on intelligent virtual agents. Springer, 205–217.
38. Lucas Kovar, Michael Gleicher, and Frédéric Pighin. 2002. Motion Graphs. ACM Transactions on Graphics 21, 3 (July 2002), 473–482.
39. Taras Kucherenko, Dai Hasegawa, Gustav Eje Henter, Naoshi Kaneko, and Hedvig Kjellström. 2019. Analyzing input and output representations for speech-driven gesture generation. In Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents. 97–104.
40. Taras Kucherenko, Patrik Jonell, Sanne van Waveren, Gustav Eje Henter, Simon Alexandersson, Iolanda Leite, and Hedvig Kjellström. 2020. Gesticulator: A framework for semantically-aware speech-driven gesture generation. In Proceedings of the 2020 International Conference on Multimodal Interaction. 242–250.
41. Taras Kucherenko, Patrik Jonell, Youngwoo Yoon, Pieter Wolfert, and Gustav Eje Henter. 2021a. A Large, Crowdsourced Evaluation of Gesture Generation Systems on Common Data: The GENEA Challenge 2020. In 26th International Conference on Intelligent User Interfaces (College Station, TX, USA) (IUI ’21). Association for Computing Machinery, New York, NY, USA, 11–21.
42. Taras Kucherenko, Rajmund Nagy, Patrik Jonell, Michael Neff, Hedvig Kjellström, and Gustav Eje Henter. 2021b. Speech2Properties2Gestures: Gesture-Property Prediction as a Tool for Generating Representational Gestures from Speech. In Proceedings of the 21st ACM International Conference on Intelligent Virtual Agents (Virtual Event, Japan) (IVA ’21). Association for Computing Machinery, New York, NY, USA, 145–147.
43. Sergey Levine, Philipp Krähenbühl, Sebastian Thrun, and Vladlen Koltun. 2010. Gesture Controllers. ACM Trans. Graph. 29, 4, Article 124 (jul 2010), 11 pages.
44. Jing Li, Di Kang, Wenjie Pei, Xuefei Zhe, Ying Zhang, Zhenyu He, and Linchao Bao. 2021a. Audio2Gestures: Generating Diverse Gestures from Speech Audio with Conditional Variational Autoencoders. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 11293–11302.
45. Ruilong Li, Shan Yang, David A. Ross, and Angjoo Kanazawa. 2021b. AI Choreographer: Music Conditioned 3D Dance Generation With AIST++. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 13401–13412.
46. Hung Yu Ling, Fabio Zinno, George Cheng, and Michiel van de Panne. 2020. Character Controllers Using Motion VAEs. ACM Transactions on Graphics 39, 4 (July 2020), 40:40:1–40:40:12.
47. Xian Liu, Qianyi Wu, Hang Zhou, Yinghao Xu, Rui Qian, Xinyi Lin, Xiaowei Zhou, Wayne Wu, Bo Dai, and Bolei Zhou. 2022. Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
48. Daniel P. Loehr. 2012. Temporal, Structural, and Pragmatic Synchrony between Intonation and Gesture. Laboratory Phonology 3, 1 (May 2012), 71–89.
49. Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. 2017. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi.. In Interspeech, Vol. 2017. 498–502.
50. Evelyn McClave. 1994. Gestural beats: The rhythm hypothesis. Journal of psycholinguistic research 23, 1 (1994), 45–66.
51. Brian McFee, Colin Raffel, Dawen Liang, Daniel P. W. Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. 2015. Librosa: Audio and Music Signal Analysis in Python. Proceedings of the 14th Python in Science Conference, 18–24.
52. David McNeill. 1992. Hand and Mind. Advances in Visual Semiotics (1992), 351.
53. Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, and Christian Theobalt. 2017. Vnect: Real-time 3d human pose estimation with a single rgb camera. ACM Transactions on Graphics (TOG) 36, 4 (2017), 1–14.
54. Michael Neff, Michael Kipp, Irene Albrecht, and Hans-Peter Seidel. 2008. Gesture Modeling and Animation Based on a Probabilistic Re-Creation of Speaker Style. ACM Transactions on Graphics 27, 1 (March 2008), 5:1–5:24.
55. van den Aaron Oord, Oriol Vinyals, and Koray Kavukcuoglu. 2017. Neural Discrete Representation Learning. ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS 30 (NIPS 2017) (2017).
56. Wim Pouw and James A Dixon. 2019. Quantifying gesture-speech synchrony. In the 6th gesture and speech in interaction conference. Universitaetsbibliothek Paderborn, 75–80.
57. Shenhan Qian, Zhi Tu, Yihao Zhi, Wen Liu, and Shenghua Gao. 2021. Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 11077–11086.
58. Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-Shot Text-to-Image Generation. In Proceedings of the 38th International Conference on Machine Learning. PMLR, 8821–8831.
59. Alexander Richard, Michael Zollhoefer, Yandong Wen, de la Fernando Torre, and Yaser Sheikh. 2021. MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement. (2021).
60. Najmeh Sadoughi and Carlos Busso. 2018. Novel realizations of speech-driven head movements with generative adversarial networks. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 6169–6173.
61. Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. 2022. Bailando: 3D Dance Generation by Actor-Critic GPT With Choreographic Memory. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11050–11059.
62. Robotics Softbank. 2018. Naoqi api documentation. In 2016 IEEE International Conference on Multimedia and Expo (ICME), vol. http://doc.aldebaran.com/2-5/homepepper.html.
63. Sebastian Starke, Ian Mason, and Taku Komura. 2022. DeepPhase: Periodic Autoencoders for Learning Motion Phase Manifolds. ACM Transactions on Graphics 41, 4 (July 2022), 136:1–136:13.
64. Sebastian Starke, Yiwei Zhao, Taku Komura, and Kazi Zaman. 2020. Local motion phases for learning multi-contact character movements. ACM Transactions on Graphics (TOG) 39, 4 (2020), 54–1.
65. Guillermo Valle-Pérez, Gustav Eje Henter, Jonas Beskow, Andre Holzapfel, Pierre-Yves Oudeyer, and Simon Alexanderson. 2021. Transflower: probabilistic autoregressive dance generation with multimodal attention. ACM Transactions on Graphics (TOG) 40, 6 (2021), 1–14.
66. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. In Advances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc.
67. Petra Wagner, Zofia Malisz, and Stefan Kopp. 2014. Gesture and speech in interaction: An overview., 209–232 pages.
68. Rebecca A. Webb. 1996. Linguistic Features of Metaphoric Gestures. Ph. D. Dissertation. University of Rochester, Rochester, New York.
69. Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. 2016. Convolutional Pose Machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
70. Pieter Wolfert, Nicole Robinson, and Tony Belpaeme. 2022. A Review of Evaluation Practices of Gesture Generation in Embodied Conversational Agents. IEEE Transactions on Human-Machine Systems 52, 3 (2022), 379–389.
71. Jing Xu, Wei Zhang, Yalong Bai, Qibin Sun, and Tao Mei. 2022. Freeform Body Motion Generation from Speech. arXiv preprint arXiv:2203.02291 (2022).
72. Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. 2021. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157 (2021).
73. Youngwoo Yoon, Bok Cha, Joo-Haeng Lee, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. 2020. Speech gesture generation from the trimodal context of text, audio, and speaker identity. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1–16.
74. Youngwoo Yoon, Woo-Ri Ko, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. 2019. Robots Learn Social Skills: End-to-End Learning of Co-Speech Gesture Generation for Humanoid Robots. In 2019 International Conference on Robotics and Automation (ICRA). 4303–4309.