
“Part123: Part-aware 3D Reconstruction From a Single-view Image”
Conference:
Type(s):
Title:
- Part123: Part-aware 3D Reconstruction From a Single-view Image
Presenter(s)/Author(s):
Abstract:
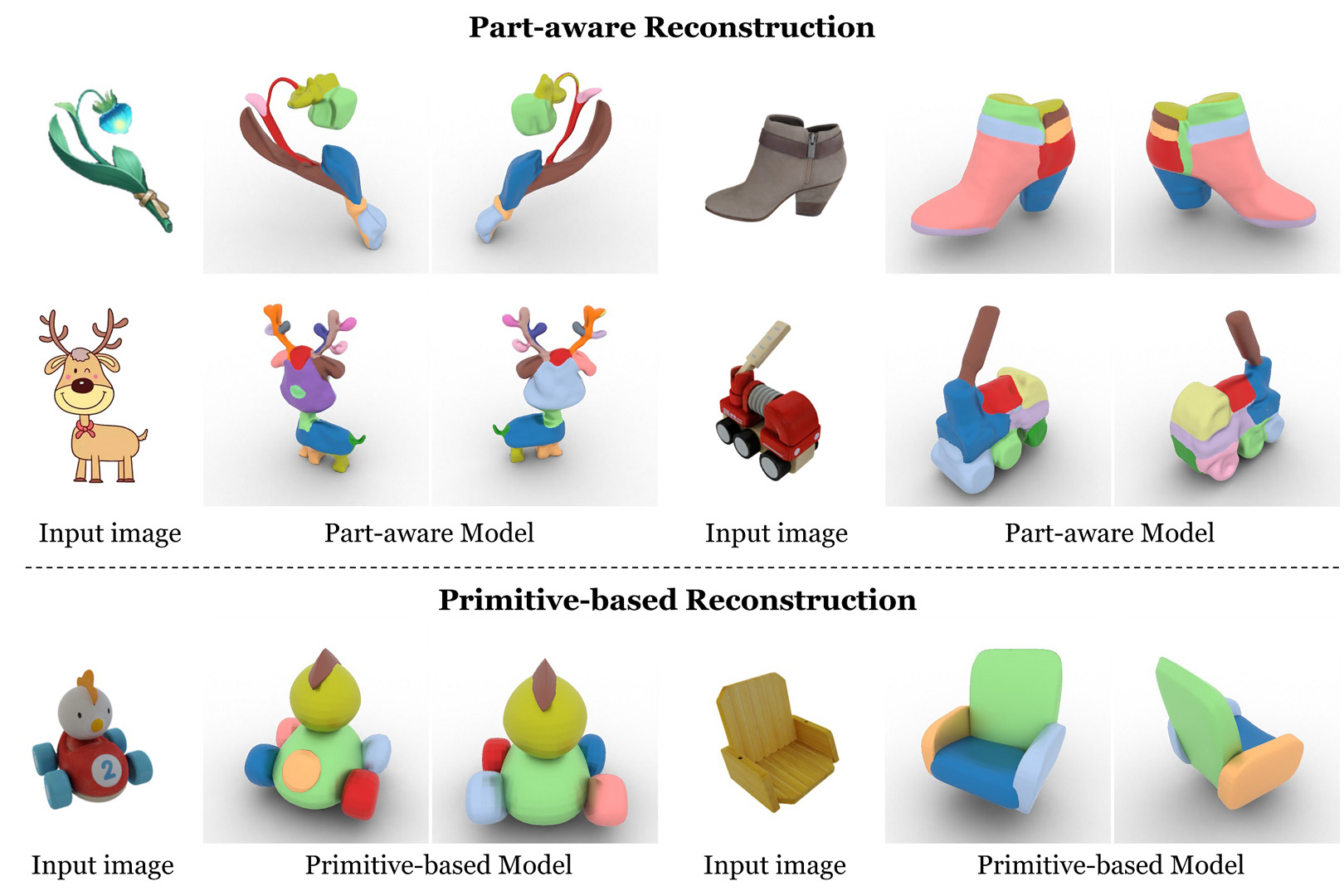
This paper proposes Part123, a novel framework for part-aware 3D reconstruction from a single-view image. Based on the multiview images generated by multiview diffusion, we apply contrastive learning to incorporate their 2D image segmentations into the 3D reconstruction process, thus enabling the generation of 3D models with high-quality part segments.
References:
[1]
Shmuel Asafi, Avi Goren, and Daniel Cohen-Or. 2013. Weak convex decomposition by lines-of-sight. In Computer graphics forum, Vol. 32. Wiley Online Library, 23?31.
[2]
Marco Attene, Bianca Falcidieno, and Michela Spagnuolo. 2006. Hierarchical mesh segmentation based on fitting primitives. The Visual Computer 22 (2006), 181?193.
[3]
Jiazhong Cen, Zanwei Zhou, Jiemin Fang, Chen Yang, Wei Shen, Lingxi Xie, Xiaopeng Zhang, and Qi Tian. 2023. Segment Anything in 3D with NeRFs. In NeurIPS.
[4]
Eric R Chan, Koki Nagano, Matthew A Chan, Alexander W Bergman, Jeong Joon Park, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, and Gordon Wetzstein. 2023. Generative novel view synthesis with 3d-aware diffusion models. arXiv preprint arXiv:2304.02602 (2023).
[5]
Hansheng Chen, Jiatao Gu, Anpei Chen, Wei Tian, Zhuowen Tu, Lingjie Liu, and Hao Su. 2023. Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction. arXiv preprint arXiv:2304.06714 (2023).
[6]
Xiaobai Chen, Aleksey Golovinskiy, and Thomas Funkhouser. 2009. A benchmark for 3D mesh segmentation. Acm transactions on graphics (tog) 28, 3 (2009), 1?12.
[7]
Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tulyakov, Alexander G Schwing, and Liang-Yan Gui. 2023. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4456?4465.
[8]
David L. Davies and Donald W. Bouldin. 1979. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1, 2 (1979), 224?227.
[9]
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. 2023. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13142?13153.
[10]
Zhiyang Dou, Xuelin Chen, Qingnan Fan, Taku Komura, and Wenping Wang. 2023. C? ase: Learning conditional adversarial skill embeddings for physics-based characters. In SIGGRAPH Asia 2023 Conference Papers. 1?11.
[11]
Zhiyang Dou, Cheng Lin, Rui Xu, Lei Yang, Shiqing Xin, Taku Komura, and Wenping Wang. 2022. Coverage axis: Inner point selection for 3d shape skeletonization. In Computer Graphics Forum, Vol. 41. Wiley Online Library, 419?432.
[12]
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kinman, Ryan Hickman, Krista Reymann, Thomas B McHugh, and Vincent Vanhoucke. 2022. Google scanned objects: A high-quality dataset of 3d scanned household items. In 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2553?2560.
[13]
Alfredo Ferreira, Simone Marini, Marco Attene, Manuel J Fonseca, Michela Spagnuolo, Joaquim A Jorge, and Bianca Falcidieno. 2010. Thesaurus-based 3D object retrieval with part-in-whole matching. International Journal of Computer Vision 89 (2010), 327?347.
[14]
Thomas Funkhouser, Michael Kazhdan, Philip Shilane, Patrick Min, William Kiefer, Ayellet Tal, Szymon Rusinkiewicz, and David Dobkin. 2004. Modeling by example. ACM transactions on graphics (TOG) 23, 3 (2004), 652?663.
[15]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2022. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618 (2022).
[16]
Lin Gao, Jie Yang, Tong Wu, Yu-Jie Yuan, Hongbo Fu, Yu-Kun Lai, and Hao Zhang. 2019. SDM-NET: Deep generative network for structured deformable mesh. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1?15.
[17]
Aleksey Golovinskiy and Thomas Funkhouser. 2008. Randomized cuts for 3D mesh analysis. In ACM SIGGRAPH Asia 2008 papers. 1?12.
[18]
Jiatao Gu, Qingzhe Gao, Shuangfei Zhai, Baoquan Chen, Lingjie Liu, and Josh Susskind. 2023a. Learning Controllable 3D Diffusion Models from Single-view Images. arXiv preprint arXiv:2304.06700 (2023).
[19]
Jiatao Gu, Alex Trevithick, Kai-En Lin, Joshua M Susskind, Christian Theobalt, Lingjie Liu, and Ravi Ramamoorthi. 2023b. Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion. In International Conference on Machine Learning. PMLR, 11808?11826.
[20]
Kan Guo, Dongqing Zou, and Xiaowu Chen. 2015. 3D Mesh Labeling via Deep Convolutional Neural Networks. ACM Trans. Graph. 35, 1 (2015), 3:1?3:12.
[21]
Amir Hertz, Or Perel, Raja Giryes, Olga Sorkine-Hornung, and Daniel Cohen-Or. 2022. Spaghetti: Editing implicit shapes through part aware generation. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1?20.
[22]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840?6851.
[23]
Ji Hou, Angela Dai, and Matthias Nie?ner. 2019. 3d-sis: 3d semantic instance segmentation of rgb-d scans. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4421?4430.
[24]
Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Alaa Maalouf, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Keetha, 2023. Conceptfusion: Open-set multimodal 3d mapping. arXiv preprint arXiv:2302.07241 (2023).
[25]
Zhongping Ji, Ligang Liu, Zhonggui Chen, and Guojin Wang. 2006. Easy mesh cutting. In Computer Graphics Forum, Vol. 25. Wiley Online Library, 283?291.
[26]
Heewoo Jun and Alex Nichol. 2023. Shap-e: Generating conditional 3d implicit functions. arXiv preprint arXiv:2305.02463 (2023).
[27]
Oliver Van Kaick, Noa Fish, Yanir Kleiman, Shmuel Asafi, and Daniel Cohen-Or. 2014. Shape segmentation by approximate convexity analysis. ACM Transactions on Graphics (TOG) 34, 1 (2014), 1?11.
[28]
Adrien Kaiser, Jos? Alonso Yb??ez Zepeda, and Tamy Boubekeur. 2019. A Survey of Simple Geometric Primitives Detection Methods for Captured 3D Data. Comput. Graph. Forum 38, 1 (2019), 167?196.
[29]
James T Kajiya and Brian P Von Herzen. 1984. Ray tracing volume densities. ACM SIGGRAPH computer graphics 18, 3 (1984), 165?174.
[30]
Evangelos Kalogerakis, Melinos Averkiou, Subhransu Maji, and Siddhartha Chaudhuri. 2017. 3D shape segmentation with projective convolutional networks. In proceedings of the IEEE conference on computer vision and pattern recognition. 3779?3788.
[31]
Evangelos Kalogerakis, Aaron Hertzmann, and Karan Singh. 2010. Learning 3D mesh segmentation and labeling. ACM Trans. Graph. 29, 4 (2010), 102:1?102:12.
[32]
Animesh Karnewar, Niloy J Mitra, Andrea Vedaldi, and David Novotny. 2023a. Holofusion: Towards photo-realistic 3d generative modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22976?22985.
[33]
Animesh Karnewar, Andrea Vedaldi, David Novotny, and Niloy J Mitra. 2023b. Holodiffusion: Training a 3D diffusion model using 2D images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18423?18433.
[34]
Sagi Katz, George Leifman, and Ayellet Tal. 2005. Mesh segmentation using feature point and core extraction. The Visual Computer 21 (2005), 649?658.
[35]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll?r, and Ross Girshick. 2023. Segment Anything. arXiv:2304.02643 (2023).
[36]
Sosuke Kobayashi, Eiichi Matsumoto, and Vincent Sitzmann. 2022. Decomposing nerf for editing via feature field distillation. Advances in Neural Information Processing Systems 35 (2022), 23311?23330.
[37]
Juil Koo, Seungwoo Yoo, Minh Hieu Nguyen, and Minhyuk Sung. 2023. Salad: Part-level latent diffusion for 3d shape generation and manipulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14441?14451.
[38]
Yu-Kun Lai, Shi-Min Hu, Ralph R Martin, and Paul L Rosin. 2008. Fast mesh segmentation using random walks. In Proceedings of the 2008 ACM symposium on Solid and physical modeling. 183?191.
[39]
Bruno L?vy, Sylvain Petitjean, Nicolas Ray, and J?r?me Maillot. 2002. Least Squares Conformal Maps for Automatic Texture Atlas Generation. ACM Transactions on Graphics 21, 3 (2002), 10?p.
[40]
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, 2022. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10965?10975.
[41]
Cheng Lin, Tingxiang Fan, Wenping Wang, and Matthias Nie?ner. 2020a. Modeling 3d shapes by reinforcement learning. In Computer Vision?ECCV 2020: 16th European Conference, Glasgow, UK, August 23?28, 2020, Proceedings, Part X 16. Springer, 545?561.
[42]
Cheng Lin, Changjian Li, Yuan Liu, Nenglun Chen, Yi-King Choi, and Wenping Wang. 2021. Point2skeleton: Learning skeletal representations from point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4277?4286.
[43]
Cheng Lin, Lingjie Liu, Changjian Li, Leif Kobbelt, Bin Wang, Shiqing Xin, and Wenping Wang. 2020b. Seg-mat: 3d shape segmentation using medial axis transform. IEEE transactions on visualization and computer graphics 28, 6 (2020), 2430?2444.
[44]
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Zexiang Xu, Hao Su, 2023c. One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization. arXiv preprint arXiv:2306.16928 (2023).
[45]
Minghua Liu, Yinhao Zhu, Hong Cai, Shizhong Han, Zhan Ling, Fatih Porikli, and Hao Su. 2023d. Partslip: Low-shot part segmentation for 3d point clouds via pretrained image-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21736?21746.
[46]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. 2023b. Zero-1-to-3: Zero-shot One Image to 3D Object. CoRR abs/2303.11328 (2023).
[47]
Weixiao Liu, Yuwei Wu, Sipu Ruan, and Gregory S Chirikjian. 2022. Robust and accurate superquadric recovery: A probabilistic approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2676?2685.
[48]
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. 2023a. SyncDreamer: Generating Multiview-consistent Images from a Single-view Image. arXiv preprint arXiv:2309.03453 (2023).
[49]
Stuart Lloyd. 1982. Least squares quantization in PCM. IEEE transactions on information theory 28, 2 (1982), 129?137.
[50]
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, 2023a. Wonder3D: Single Image to 3D using Cross-Domain Diffusion. arXiv preprint arXiv:2310.15008 (2023).
[51]
Xiaoxiao Long, Cheng Lin, Lingjie Liu, Yuan Liu, Peng Wang, Christian Theobalt, Taku Komura, and Wenping Wang. 2023b. Neuraludf: Learning unsigned distance fields for multi-view reconstruction of surfaces with arbitrary topologies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20834?20843.
[52]
Xiaoxiao Long, Cheng Lin, Peng Wang, Taku Komura, and Wenping Wang. 2022. Sparseneus: Fast generalizable neural surface reconstruction from sparse views. In European Conference on Computer Vision. Springer, 210?227.
[53]
William E. Lorensen and Harvey E. Cline. 1987. Marching cubes: A high resolution 3D surface construction algorithm. In Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 1987, Anaheim, California, USA, July 27-31, 1987, Maureen C. Stone (Ed.). ACM, 163?169.
[54]
Luke Melas-Kyriazi, Iro Laina, Christian Rupprecht, and Andrea Vedaldi. 2023. Realfusion: 360deg reconstruction of any object from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8446?8455.
[55]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In European Conference on Computer Vision. Springer, 405?421.
[56]
Kaichun Mo, Paul Guerrero, Li Yi, Hao Su, Peter Wonka, Niloy J Mitra, and Leonidas J Guibas. 2019. StructureNet: hierarchical graph networks for 3D shape generation. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1?19.
[57]
George Kiyohiro Nakayama, Mikaela Angelina Uy, Jiahui Huang, Shi-Min Hu, Ke Li, and Leonidas Guibas. 2023. Difffacto: Controllable part-based 3d point cloud generation with cross diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14257?14267.
[58]
Gimin Nam, Mariem Khlifi, Andrew Rodriguez, Alberto Tono, Linqi Zhou, and Paul Guerrero. 2022. 3d-ldm: Neural implicit 3d shape generation with latent diffusion models. arXiv preprint arXiv:2212.00842 (2022).
[59]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. 2022. Point-e: A system for generating 3d point clouds from complex prompts. arXiv preprint arXiv:2212.08751 (2022).
[60]
Chengjie Niu, Jun Li, and Kai Xu. 2018. Im2struct: Recovering 3d shape structure from a single rgb image. In Proceedings of the IEEE conference on computer vision and pattern recognition. 4521?4529.
[61]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018).
[62]
Despoina Paschalidou, Luc Van Gool, and Andreas Geiger. 2020. Learning unsupervised hierarchical part decomposition of 3d objects from a single rgb image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1060?1070.
[63]
Despoina Paschalidou, Angelos Katharopoulos, Andreas Geiger, and Sanja Fidler. 2021. Neural parts: Learning expressive 3d shape abstractions with invertible neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3204?3215.
[64]
Despoina Paschalidou, Ali Osman Ulusoy, and Andreas Geiger. 2019. Superquadrics Revisited: Learning 3D Shape Parsing Beyond Cuboids. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 10344?10353.
[65]
Dmitry Petrov, Matheus Gadelha, Radom?r M?ch, and Evangelos Kalogerakis. 2023. ANISE: Assembly-based Neural Implicit Surface rEconstruction. IEEE Transactions on Visualization and Computer Graphics (2023).
[66]
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. 2022. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022).
[67]
Guocheng Qian, Jinjie Mai, Abdullah Hamdi, Jian Ren, Aliaksandr Siarohin, Bing Li, Hsin-Ying Lee, Ivan Skorokhodov, Peter Wonka, Sergey Tulyakov, 2023. Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors. arXiv preprint arXiv:2306.17843 (2023).
[68]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748?8763.
[69]
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, 2023. Dreambooth3d: Subject-driven text-to-3d generation. arXiv preprint arXiv:2303.13508 (2023).
[70]
Rui SV Rodrigues, Jos? FM Morgado, and Abel JP Gomes. 2018. Part-based mesh segmentation: a survey. In Computer Graphics Forum, Vol. 37. Wiley Online Library, 235?274.
[71]
Pedro V Sander, Zo? J Wood, Steven Gortler, John Snyder, and Hugues Hoppe. 2003. Multi-chart geometry images. (2003).
[72]
Lior Shapira, Ariel Shamir, and Daniel Cohen-Or. 2008. Consistent mesh partitioning and skeletonisation using the shape diameter function. The Visual Computer 24 (2008), 249?259.
[73]
Shymon Shlafman, Ayellet Tal, and Sagi Katz. 2002. Metamorphosis of polyhedral surfaces using decomposition. In Computer graphics forum, Vol. 21. Wiley Online Library, 219?228.
[74]
Zhenyu Shu, Chengwu Qi, Shi-Qing Xin, Chao Hu, Li Wang, Yu Zhang, and Ligang Liu. 2016. Unsupervised 3D shape segmentation and co-segmentation via deep learning. Comput. Aided Geom. Des. 43 (2016), 39?52.
[75]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning. PMLR, 2256?2265.
[76]
Robert W Sumner and Jovan Popovi?. 2004. Deformation transfer for triangle meshes. ACM Transactions on graphics (TOG) 23, 3 (2004), 399?405.
[77]
Chun-Yu Sun and Qian-Fang Zou. 2019. Learning adaptive hierarchical cuboid abstractions of 3D shape collections. ACM Trans. Graph. 38, 6 (2019), 241:1?241:13.
[78]
Stanislaw Szymanowicz, Christian Rupprecht, and Andrea Vedaldi. 2023. Viewset Diffusion:(0-) Image-Conditioned 3D Generative Models from 2D Data. arXiv preprint arXiv:2306.07881 (2023).
[79]
Ay?a Takmaz, Elisabetta Fedele, Robert W Sumner, Marc Pollefeys, Federico Tombari, and Francis Engelmann. 2023. Openmask3d: Open-vocabulary 3d instance segmentation. arXiv preprint arXiv:2306.13631 (2023).
[80]
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. 2023. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. arXiv preprint arXiv:2303.14184 (2023).
[81]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. 2022. Human motion diffusion model. arXiv preprint arXiv:2209.14916 (2022).
[82]
Ayush Tewari, Tianwei Yin, George Cazenavette, Semon Rezchikov, Joshua B Tenenbaum, Fr?do Durand, William T Freeman, and Vincent Sitzmann. 2023. Diffusion with Forward Models: Solving Stochastic Inverse Problems Without Direct Supervision. arXiv preprint arXiv:2306.11719 (2023).
[83]
Shubham Tulsiani, Hao Su, Leonidas J. Guibas, Alexei A. Efros, and Jitendra Malik. 2017. Learning Shape Abstractions by Assembling Volumetric Primitives. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 1466?1474.
[84]
Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis, 2022. LION: Latent Point Diffusion Models for 3D Shape Generation. Advances in Neural Information Processing Systems 35 (2022), 10021?10039.
[85]
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A Yeh, and Greg Shakhnarovich. 2023. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12619?12629.
[86]
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. 2021. NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction. NeurIPS (2021).
[87]
Rundi Wu, Yixin Zhuang, Kai Xu, Hao Zhang, and Baoquan Chen. 2020. Pq-net: A generative part seq2seq network for 3d shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 829?838.
[88]
Zhijie Wu, Xiang Wang, Di Lin, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. 2019. Sagnet: Structure-aware generative network for 3d-shape modeling. ACM Transactions on Graphics (TOG) 38, 4 (2019), 1?14.
[89]
Jianfeng Xiang, Jiaolong Yang, Binbin Huang, and Xin Tong. 2023. 3D-aware Image Generation using 2D Diffusion Models. arXiv preprint arXiv:2303.17905 (2023).
[90]
Desai Xie, Jiahao Li, Hao Tan, Xin Sun, Zhixin Shu, Yi Zhou, Sai Bi, S?ren Pirk, and Arie E Kaufman. 2023. Carve3D: Improving Multi-view Reconstruction Consistency for Diffusion Models with RL Finetuning. arXiv preprint arXiv:2312.13980 (2023).
[91]
Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Yi Wang, and Zhangyang Wang. 2023. NeuralLift-360: Lifting an In-the-Wild 2D Photo to a 3D Object With 360deg Views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4479?4489.
[92]
Haotian Xu, Ming Dong, and Zichun Zhong. 2017. Directionally Convolutional Networks for 3D Shape Segmentation. In IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEEE Computer Society, 2717?2726.
[93]
Yunhan Yang, Xiaoyang Wu, Tong He, Hengshuang Zhao, and Xihui Liu. 2023. SAM3D: Segment Anything in 3D Scenes. arXiv preprint arXiv:2306.03908 (2023).
[94]
Qing Yuan, Guiqing Li, Kai Xu, Xudong Chen, and Hui Huang. 2016. Space-time co-segmentation of articulated point cloud sequences. In Computer Graphics Forum, Vol. 35. Wiley Online Library, 419?429.
[95]
Wangyu Zhang, Bailin Deng, Juyong Zhang, Sofien Bouaziz, and Ligang Liu. 2015. Guided Mesh Normal Filtering. Comput. Graph. Forum 34, 7 (2015), 23?34.
[96]
Xin-Yang Zheng, Hao Pan, Peng-Shuai Wang, Xin Tong, Yang Liu, and Heung-Yeung Shum. 2023. Locally attentional sdf diffusion for controllable 3d shape generation. arXiv preprint arXiv:2305.04461 (2023).
[97]
Youyi Zheng, Hongbo Fu, Oscar Kin-Chung Au, and Chiew-Lan Tai. 2011. Bilateral Normal Filtering for Mesh Denoising. IEEE Trans. Vis. Comput. Graph. 17, 10 (2011), 1521?1530.
[98]
Yan Zheng, Lemeng Wu, Xingchao Liu, Zhen Chen, Qiang Liu, and Qixing Huang. 2022. Neural volumetric mesh generator. arXiv preprint arXiv:2210.03158 (2022).
[99]
Wenyang Zhou, Zhiyang Dou, Zeyu Cao, Zhouyingcheng Liao, Jingbo Wang, Wenjia Wang, Yuan Liu, Taku Komura, Wenping Wang, and Lingjie Liu. 2023. EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Motion Generation. arXiv preprint arXiv:2312.02256 (2023).
[100]
Emanoil Zuckerberger, Ayellet Tal, and Shymon Shlafman. 2002. Polyhedral surface decomposition with applications. Computers & Graphics 26, 5 (2002), 733?743.